「小样本深度学习图像识别」最新2022综述
技术来自于点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
小样本深度学习图像识别最新综述论文
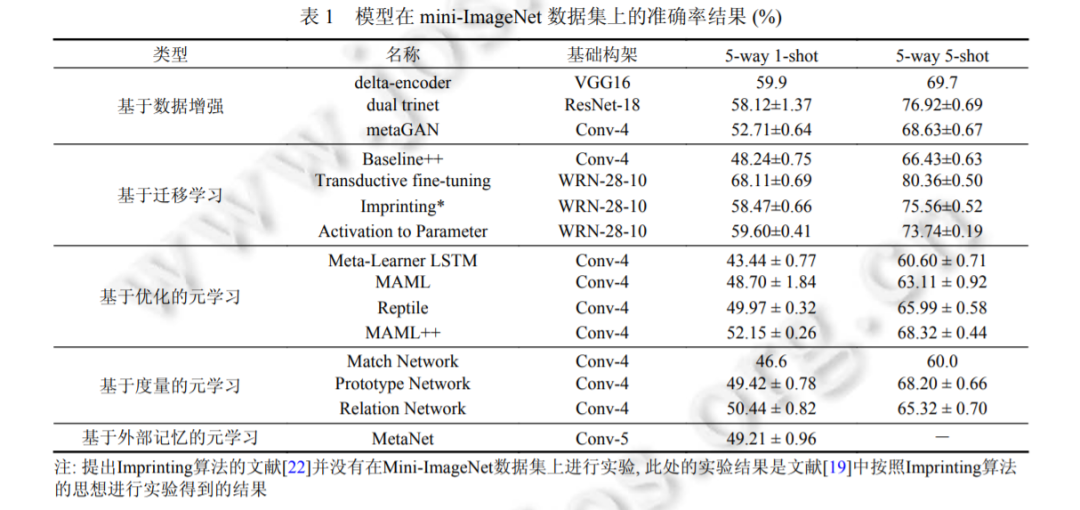
图像识别是图像研究领域的核心问题, 解决图像识别问题对人脸识别、自动驾驶、机器人等各领域研究都有重要意义. 目前广泛使用的基于深度神经网络的机器学习方法, 已经在鸟类分类、人脸识别、日常物品分类等图像识别数据集上达到了超过人类的水平, 同时越来越多的工业界应用开始考虑基于深度神经网络的方法, 以完成一系列图像识别业务. 但是深度学习方法极度依赖大规模标注数据, 这一缺陷极大地限制了深度学习方法在实际图像识别任务中的应用. 针对这一问题, 越来越多的研究者开始研究如何基于少量的图像识别标注样本来训练识别模型. 为了更好地理解基于少量标注样本的图像识别问题, 广泛地讨论了几种图像识别领域主流的少量标注学习方法, 包括基于数据增强的方法、基于迁移学习的方法以及基于元学习的方法, 通过讨论不同算法的流程以及核心思想, 可以清晰地看到现有方法在解决少量标注的图像识别问题上的优点和不足. 最后针对现有方法的局限性, 指出了小样本图像识别未来的研究方向.
地址:
http://www.jos.org.cn/jos/article/abstract/6342?st=article_issue
现在的机器学习方法, 尤其是基于深度神经网络的机器学习方法已经在人脸识别[1]、自动驾驶[2]、机器人[3] 等图像识别相关领域取得了巨大的成就, 有的甚至已经超过人类目前的识别水平. 然而在深度学习取得巨大成就 的同时, 人们发现把其应用到实际问题中却困难重重. 首先是标注数据的问题, 目前的深度学习方法需要大量的标 注数据来进行训练[4] , 但是实际应用中数据获取往往是困难的, 这之中既有个人隐私的问题, 比如人脸数据, 也有 问题对象本身就很少的问题, 比如识别珍稀保护动物的问题, 除此之外, 数据标注工作往往需要耗费大量人力物力, 从而阻碍了深度学习技术在图像识别领域的落地. 其次是算力问题, 深度学习方法在提高算法性能的同时, 往往伴随着庞大的网络运算, 这也就使得深度学习的方法很难部署在计算资源受限的设备上, 因此在一些算力受限 的应用场景, 比如自动驾驶、机器人、道路监控等问题中, 图像识别任务目前大多还是使用一些低智能化、低算力消耗的技术完成的, 这同样严重阻碍了智能化图像识别技术的发展.
与之相反, 人类的识别却是相对轻量的, 即并不需要收集大量的数据来进行学习, 更不需要长时间的思考或者 计算[5] . 比如父母教新生婴儿识字, 分辨动物, 只需要简单地在家里贴上一两幅相应的字画即可, 小孩很快就会认 识上面的内容. 如何在保留现在的深度学习方法强大的知识表示能力的同时, 使其可以快速从少量样本中学习到 有用的知识, 这种基于小样本的图像识别问题已经逐渐引起了人们的注意.
本文将按照下面的顺序来展开讨论, 首先在第 1 节介绍小样本图像识别的问题描述, 然后会在第 2 节介绍基 于数据增强的小样本学习算法, 在第 3 部分介绍基于迁移学习的算法, 在第 4 节介绍基于元学习的算法, 会在第 5 节介绍现在广泛使用的小样本图像识别问题评价指标, 并对比上面介绍的算法在该问题基准上的性能, 最后会在 第 6 部分指出现有算法的不足以及未来的发展方向.
1 小样本学习简介
小样本图像识别任务需要机器学习模型在少量标注数据上进行训练和学习, 目前经常研究的问题为 N-way Kshot 形式, 即问题包括 N 种数据, 每种数据只包含 K 个标注样本[6] . 现有的小样本图像识别问题可以看做是基于深 度迁移学习的图像识别问题, 这里我们把上面提到的少量标注数据称作目标数据域, 后续的识别任务都是基于目 标数据所包含的类别进行的; 然后为了辅助模型的训练, 通常会引入一个和目标数据域类别互斥的辅助数据集, 和 目标数据域的少量标注相反, 辅助数据集的标注样本更加丰富, 类别也更加多.
解决 N-way K-shot 形式的小样本图像识别任务, 大多数方法会从辅助数据集学习先验知识, 然后在标注有限 的目标数据域上利用这些先验知识完成学习和预测任务. 在下面的章节我们会详细讨论如何基于辅助数据集来学 习先验知识, 以及如何利用这些先验知识来在小样本图像识别问题上完成学习和预测.
2 基于数据增强的小样本图像识别方法
小样本图像识别任务的核心问题是标注数据不足, 所以通过算法生成人工标注数据, 来扩充原有的数据量是 一种非常直观的方法[7] . 在小样本图像识别任务领域, 目前常用的数据增强方法基本上都是利用少量的标注数据 来生成更多的伪数据, 比如人工合成图像, 同时需要给这些伪数据打上标签, 然后作为标注数据来辅助训练, 本质 上和迁移学习的方法是异曲同工的[8] . 按照伪数据的使用方式, 可以将其划分为两种类型: 一种是使用伪数据来填 补标注不足的小样本数据, 另外一种是使用伪数据来显式地锐化分类算法学习到的决策边界. 下面就这两种方法 以及对应的具体算法展开讨论.
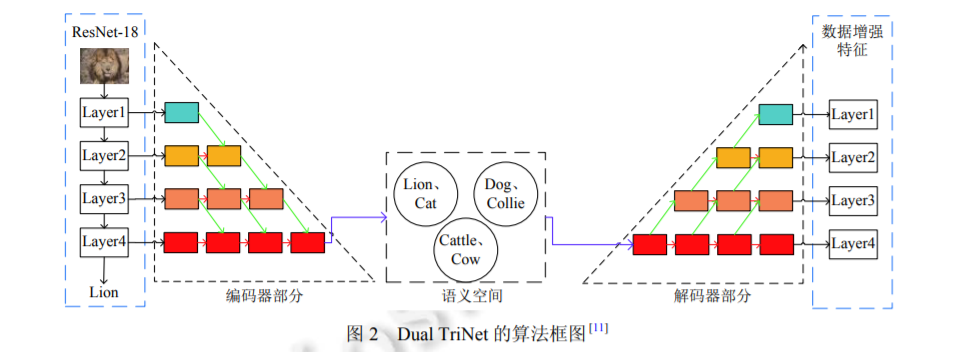
基于数据增强的思路来解决小样本学习问题是一种最直观的思路, 而且该类方法更加灵活, 通过设 计数据增强模块生成伪数据, 将其扩充到小样本数据中, 使用混合数据直接对识别模型进行更新即可. 但是因为实 际样本数目较少, 目前广泛使用的基于深度神经网络的方法在实际的数据增强中, 容易出现知识偏移以及过拟合 的问题, 所以实际的应用效果会比后面介绍的几类方法差一些. 但是这种数据增强的思路对于解决实际的样本缺 失问题来说更具有普遍意义, 所以将数据增强的思路融入迁移学习或者元学习的算法中, 是未来值得研究的方向.
3 基于迁移学习的小样本图像识别方法
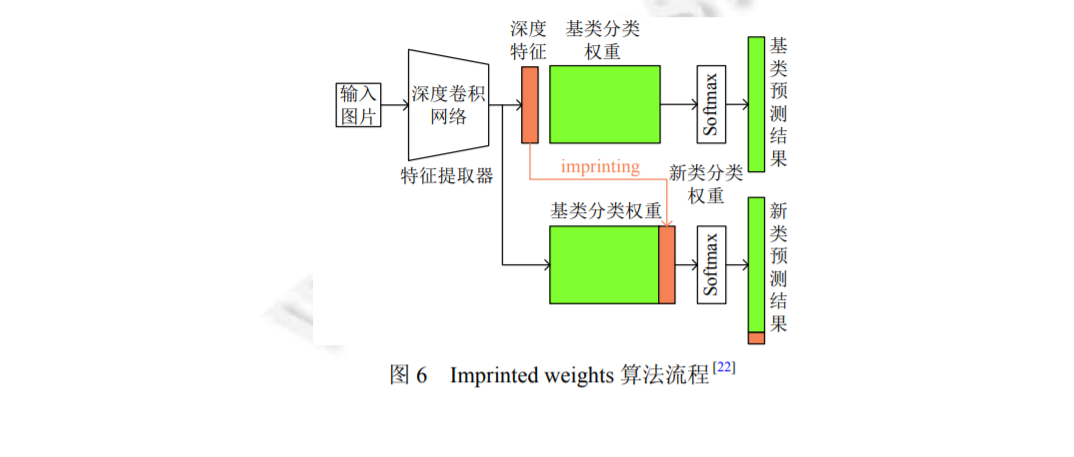
面对标注限制的机器学习任务, 一个很自然的思路就是将模型在大数据集上进行预训练, 从中学习到一些有 利于当前任务的先验知识, 从而来弥补标注数据不足的问题. 这一方法在机器学习领域, 尤其是近几年普遍使用的 神经网络方法中取得了不错的效果, 下面关于为什么迁移学习[16]可以应用于小样本学习, 以及迁移学习如何应用 于小样本学习进行讨论。
4 基于元学习的小样本图像识别方法
元学习[24]的目标是使得网络模型具有快速学习的能力, 快速学习是人类与生俱来的一种生存能力, 元学习方 法希望模型具有像人类一样, 通过较少的示例就可以在较短的时间内学会分辨新的事物的能力. 通过元学习的问 题定义可以发现, 元学习方法是处理小样本学习问题的一个重要思路. 本节将围绕 3 种用于小样本图像识别问题 的元学习方法展开讨论, 这 3 种方法分别为基于优化器的小样本学习算法, 基于度量的小样本学习算法以及基于 外部记忆的小样本学习算法.
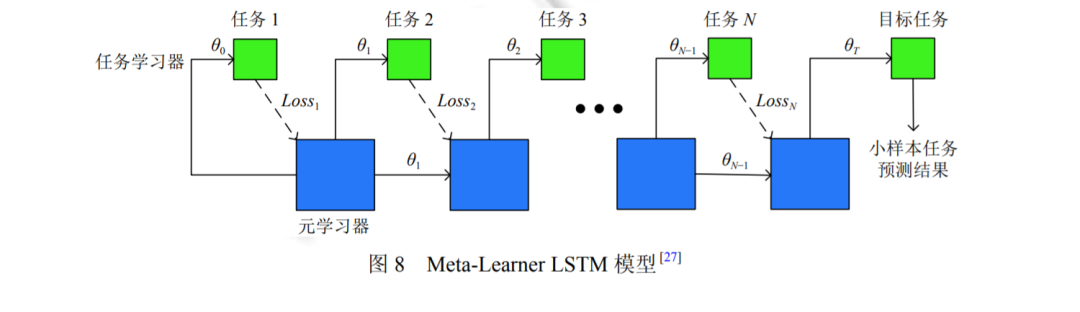
基于元学习的思路来解决小样本学习问题, 是近两年该领域的研究热点, 如何划分任务通用参数和任务特定 参数, 如何更加有效地训练元学习模型等课题一直具有相当的活力. 元学习算法希望学习一个可以“自主”学习的模型, 使得模型在只有少量样本的新任务上可以快速泛化. 尽管元学习方法在小样本学习中已经取得了不错的效 果, 但是该类方法仍然存在一些问题.
(1) 元学习算法优化难; 因为采用多任务交替训练的方式来更新模型, 不同任务的数据之间存在数据分布的不 同, 只是简单地交替训练, 在任务数据分布差别较大的时候, 会导致最后的模型难以收敛的问题;
(2) 元学习算法缺乏相关的可解释性; 元学习算法的思路具有一定的启发性, 但是关于方法的有效性一直难以 被证明, 同时元学习方法和迁移学习方法之间的区别也一直是研究者们关注的重点, 如何从理论上解释元学习的 有效性, 是未来的一个重要的研究方向.