
【论文解读】PFLD:高精度实时人脸关键点检测算法

这篇文章作者分别来自天津大学、武汉大学、腾讯AI实验室、美国天普大学。该算法对在高通ARM 845处理器可达140fps;另外模型大小较小,仅2.1MB;此外在许多关键点检测的benchmark中也取得了相当好的结果。
摘要:
高精度,速度快,模型小是人脸关键点的实际使用必不可少的要求。为了同时考虑这三个问题,本文研究了一个整洁的模型,该模型在野外环境(如无约束的姿态、表情、光照和遮挡条件)和移动设备上的超实时速度下具有良好的检测精度。更具体地说,我们定制了一个与加速技术相关的端到端single stage 网络。在训练阶段,对每个样本进行旋转信息进行估计,用于几何规则的关键点定位,然后在测试阶段不涉及。在考虑几何规则化的基础上,设计了一种新的损失算法通过调整训练集中不同状态(如大姿态、极端光照和遮挡)的样本权重,来解决数据不平衡的问题。我们进行了大量的实验来证明我们的有效性,在被广泛采用的具有挑战性的基准测试中, 300W(包括iBUG, LFPW, AFW, HELEN,以及XM2VTS)和AFLW,设计并显示其优于最先进的替代品的性能。我们的模型只有2.1Mb 大小和达到140帧/张在手机上 (高通ARM 845处理器)高精度,适合大规模或实时应用。
为了能更清晰了解文章的内容,用下面的思维导图来展示文章的主要贡献

Introduction
人脸关键点检测也称为人脸对齐,目的是自动定位一组预定义的人脸基准点(比如眼角点、嘴角点)。作为一系列人脸应用的基础,如人脸识别和验证,以及脸部变形和人脸编辑。这个问题一直以来都受到视觉界的高度关注,在过去的几年里,我们的产品取得了很大的进步。然而,开发一种实用的人脸关键点检测器仍然具有挑战性,因为检测精度,处理速度和模型大小都应该考虑。
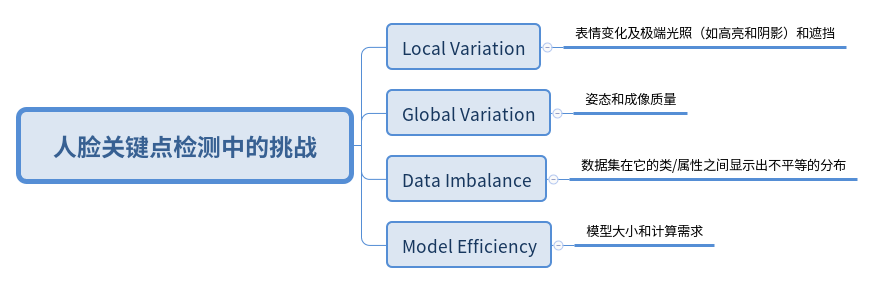
在现实世界条件下,获得完美的面孔几乎是不可能的。换句话说,人脸经常是出现在控制不足甚至没有约束的环境中。在不同的照明条件下,它的外表有各种各样的姿势、表情和形状,有时还有部分遮挡。图1提供了这样的几个例子。此外,有足够的训练数据用于数据驱动方法也是模型性能的关键。在综合考虑不同条件下,捕捉多个人脸可能是可行的,但这种收集方式会变得不切实际,特别是当需要大规范的数据来训练深度模型时。在这种情况下,我们经常会遇到不平衡的数据分布。以下总结了有关人脸关键点检测精度的问题,分为三个挑战(考虑实际使用时,还有一个额外的挑战!)。

Challenge #1 - Local Variation.
表情变化及极端光照(如高亮和阴影)和遮挡的下,人脸的部分区域特征就会发生较大偏差甚至消失的情况。
Challenge #2 - Global Variation.
姿态和成像质量是影响人脸在图像中出现的两个主要因素,当对人脸的整体结构估计错误时,会导致很大一部分标志点定位不理想。
Challenge #3 - Data Imbalance.
在浅层学习和深度学习中,一个可用的数据集在它的类/属性之间显示出不平等的分布,这是很常见的。这种不平衡很可能使算法/模型不能恰当地代表数据的特征,从而在不同属性之间提供不理想的准确性。
上述挑战极大地增加了准确检测的难度,要求检测器更加鲁棒。
随着便携式设备的出现,越来越多的人喜欢随时随地处理他们的业务或娱乐。因此,除了追求检测的高精度外,还应考虑以下挑战。
Challenge #4 - Model Efficiency.
对与应用而言,另两个限制是模型大小和计算需求。机器人、增强现实和视频聊天等任务有望在一个装备有限计算和内存资源的平台(如智能手机或嵌入式产品)上及时执行。
这一点特别要求探测器是模型尺寸小,处理速度快。毫无疑问,建立准确、高效、紧凑的实际关键点检测系统是很有必要的。
网络结构
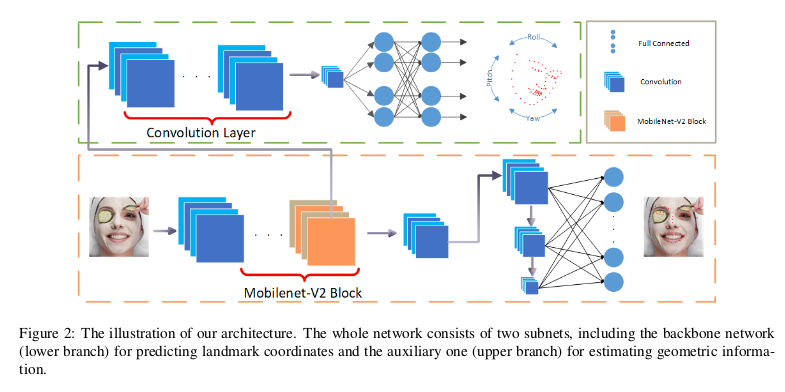
黄色曲线包围的是主网络,用于预测特征点的位置;
绿色曲线包围的部分为辅助子网络,在训练时预测人脸姿态(主要包括三个姿态角,,有文献表明给网络加这个辅助任务可以提高定位精度,具体参考原论文),这部分在测试时不需要。
backbone 网络是 bottleneck,用MobileNet块代替了传统的卷积运算。通过这样做,我们的backbone的计算量大大减少,从而加快了速度。此外,可以根据用户需求通过调整MobileNets的width参数来压缩我们的网络,从而使模型更小,更快。
姿态角的计算方法:
预先定义一个标准人脸(在一堆正面人脸上取平均值),在人脸主平面上固定11个关键点作为所有训练人脸的参考;
使用对应的11个关键点和估计旋转矩阵的参考矩阵;
由旋转矩阵计算欧拉角。
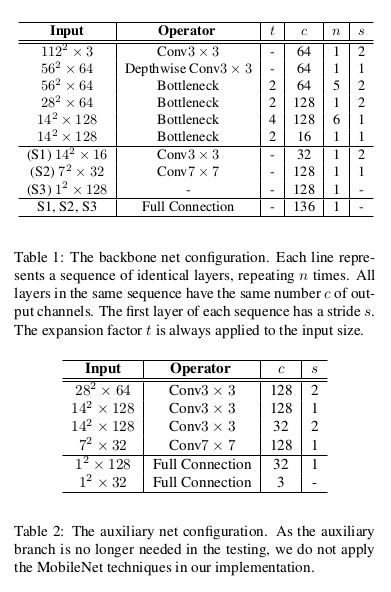
网络结构细节如下:
Loss函数
在深度学习中,数据不平衡是另一个经常限制准确检测性能的问题。例如,训练集可能包含大量正面,而缺少那些姿势较大的面孔。如果没有额外的技巧,几乎可以肯定的是,由这样的训练集训练的模型不能很好地处理大型姿势情况。在这种情况下,“平均”惩罚每个样本将使其不平等。为了解决这个问题,我们主张对训练样本数量少进行大的惩罚,而不是对样本数量多的进行惩罚。
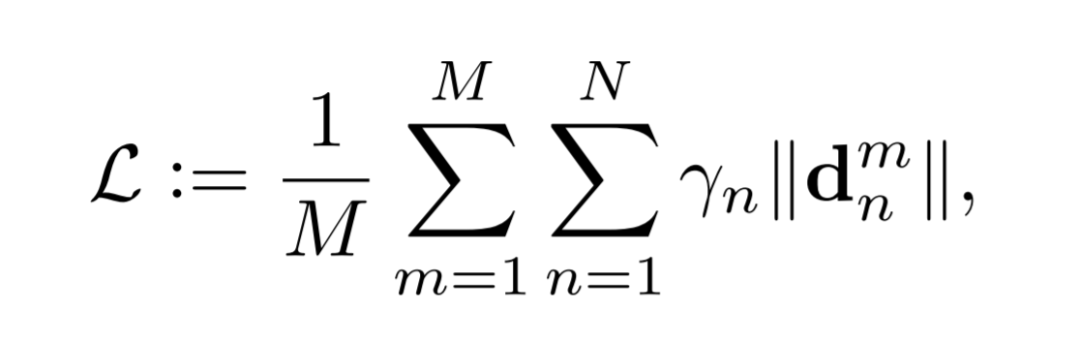
M为样本个数,N为特征点个数,Yn为不同的权重,|| * ||为特征点的距离度量(L1或L2距离)。(以Y代替公式里的希腊字母)
进一步细化Yn:
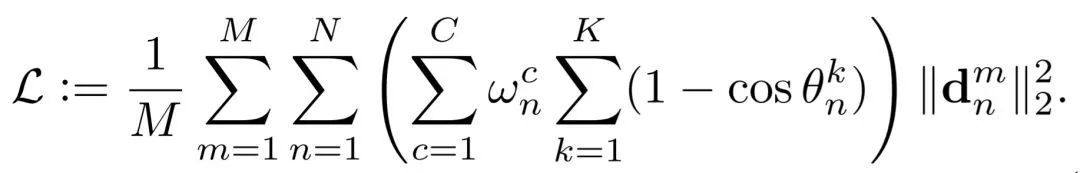
其中:
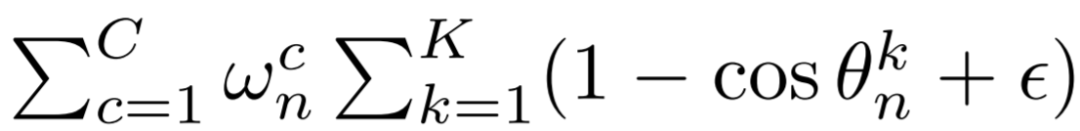
即为最终的样本权重。
K=3,这一项代表着人脸姿态估计的三个维度,即yaw, pitch, roll 角度,由计算公式可知角度越高,权重越大。
C为不同的人脸类别数,作者将人脸分成多个类别,比如侧脸、正脸、抬头、低头、表情、遮挡等,w为与类别对应的给定权重,如果某类别样本少则给定权重大。
3 Experimental Evaluation
作者在主流人脸特征点数据集300W,AFLW上测试了精度,尽管看起来上述模型很简单,但超过了以往文献的最高精度!
下图是在300W上的CED,与其他算法相比有一定的优势
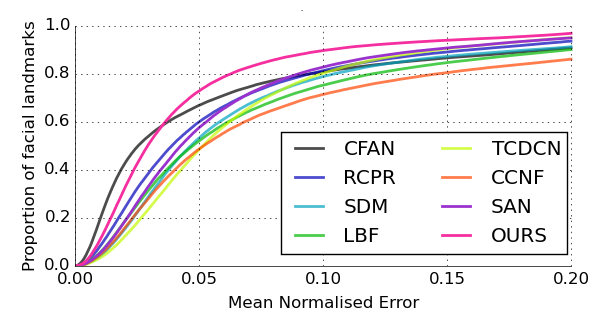
图的含义:横坐标是 归一化的平均误差,纵坐标是 人脸关键点的比例
下面来看一下算法处理速度和模型大小,图中C代表i7-6700K CPU,G代表080 Ti GPU,G*代表Titan X GPU,A代表移动平台Qualcomm ARM 845处理器。

下图为在300W数据集上不同数据集难度上精度比较结果,依然是领先的。
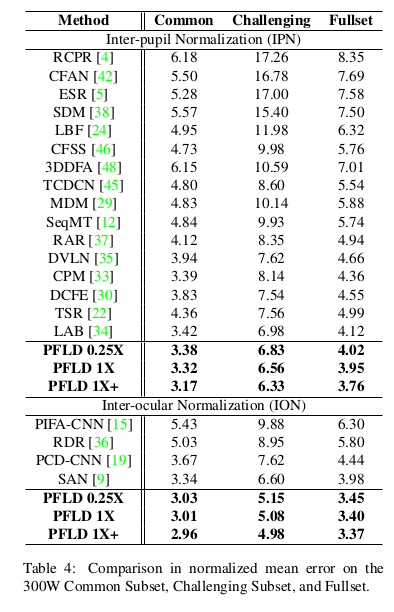
其中PFLD 1X是标准网络,PFLD 0.25X是MobileNet blocks width 参数设为0.25的压缩网络,PFLD 1X+是在WFLW数据集上预训练的网络。
下图是该算法在AFLW数据集上与其他算法的精度比较:
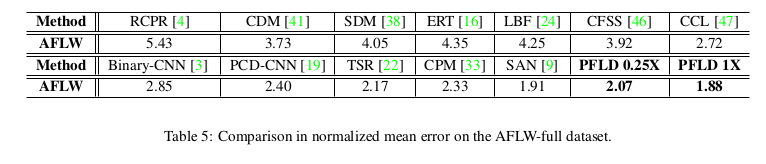
同样是达到了新高度!
结论:
人脸关键点探测器需要具备三个方面,才能胜任大规模和/或实时任务,即准确性、效率和模型大小。本文提出了一种实用的人脸关键点检测器,称为PFLD,它由主干网和辅助子网组成。backbone是由MobileNet块构建的,它可以很大程度上释放卷积层的计算压力,并根据用户的要求,通过调整宽度参数,使模型在尺寸上灵活。通过引入多尺度全连接层来扩大感受野,提高捕捉人脸结构的能力。为了进一步规范化关键点定位,我们自定义了另一个分支,即辅助网络,通过辅助网络可以有效地估计出关键点的旋转信息。考虑几何正则化和数据不平衡问题,设计了一种新的损失算法。大量的实验结果表明,我们的设计在精度、模型大小和处理速度方面优于最新的方法,因此验证了我们的PFLD 0.25X在实际使用中是一个很好的折衷。
参考资料
https://arxiv.org/abs/1902.10859
https://zhuanlan.zhihu.com/p/73546427
https://www.sohu.com/a/299993701_633698
https://github.com/guoqiangqi/PFLD
https://github.com/polarisZhao/PFLD-pytorch (亲测可用)
APP下载链接:https://pan.baidu.com/s/16HjDy9TyotCVwDdd55oWVQ
提取码:glwr
往期精彩回顾
获取一折本站知识星球优惠券,复制链接直接打开:
https://t.zsxq.com/yFQV7am
本站qq群1003271085。
加入微信群请扫码进群: