
EfficientDet 算法解读
Google Brain 团队的三位 Auto ML 大佬 Mingxing Tan, Ruoming Pang, Quoc V. Le 在 CVPR 2020 发表一篇文章 EfficientDet: Scalable and Efficient Object Detection,代码已经开源到了 Github。
这篇工作可以看做是中了 ICML 2019 Oral 的 EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks 扩展,从分类任务扩展到检测任务(Object Detection)。
众所周知,神经网络的速度和精度之间存在权衡,而 EfficientDet 是一个总称,可以分为 EfficientDet D1 ~ EfficientDet D7,速度逐渐变慢,但是精度也逐渐提高。
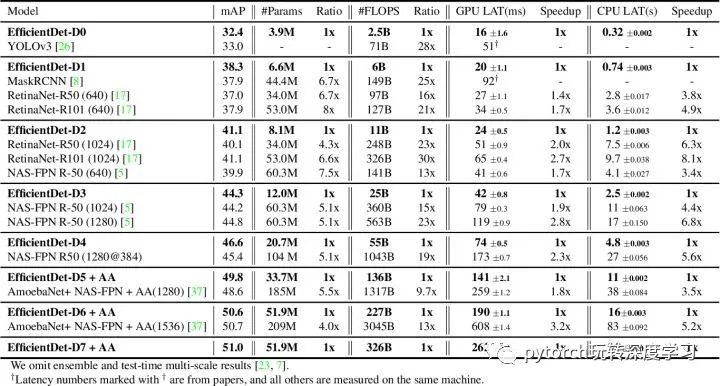
从下图中可以看出,EfficientDet-D7 的性能非常的惊人:在 326B FLOPS,参数量 52 M的情况下,COCO 2017 validation 数据集上取得了 51.0 的 mAP,state-of-the-art 的结果。和 AmoebaNet + NAS-FPN 相比,FLOPS 仅为其十分之一的情况下取得了更好的结果。
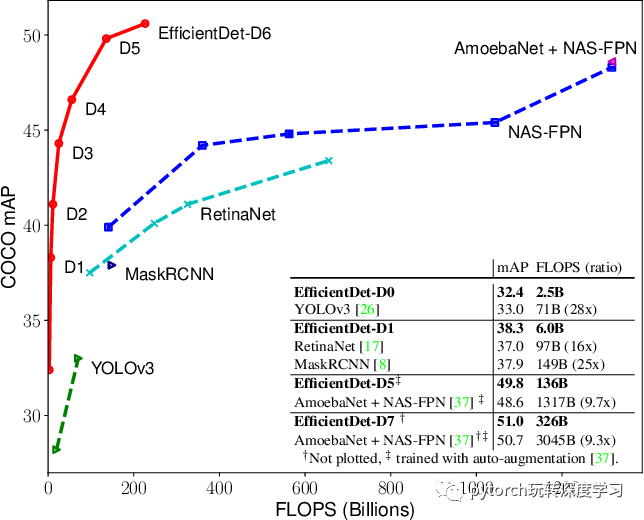
这篇文章的主要贡献点是 BiFPN,Compound Scaling 两部分,会在下面一一介绍。
BiFPN
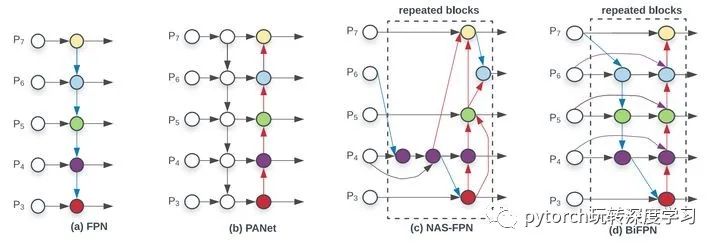
CVPR 2017 的 FPN 指出了不同层之间特征融合的重要性,并且以一种比较简单,Heuristic 的方法把底层的特征乘两倍和浅层相加来融合。之后人们也试了各种别的融合方法,比如 PANet 先从底向上连,再自顶向下连回去;M2Det 在连的时候加入 skip-connection; Libra-RCNN 先把所有feature 都汇聚到中间层,然后再 refine。
总之上述都是一些人工连连看的设计,包含 Conv,Sum,Concatenate,Resize,Skip Connection 等候选操作。很明显使用哪些操作、操作之间的顺序是可以用 NAS 搜的。进入 Auto ML 时代之后,NAS-FPN 珠玉在前,搜到了一个更好的 neck 部分的结构。
本文的作者基于下面的观察结果/假设,进一步进行了优化:
作者观察到 PANet 的效果比 FPN ,NAS-FPN 要好,就是计算量更大;
作者从 PANet 出发,移除掉了只有一个输入的节点。这样做是假设只有一个输入的节点相对不太重要。这样把 PANet 简化,得到了上图 (e) Simplified PANet 的结果;
作者在相同 level 的输入和输出节点之间连了一条边,假设是能融合更多特征,有点 skip-connection 的意味,得到了上图 (f) 的结果;
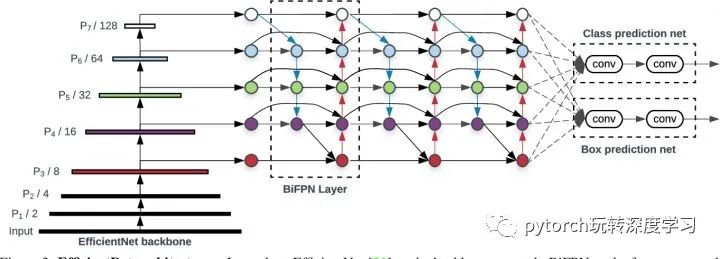
PANet 只有从底向上连,自顶向下两条路径,作者认为这种连法可以作为一个基础层,重复多次。这样就得到了下图的结果(看中间的 BiFPN Layer 部分)。如何确定重复几次呢,这是一个速度和精度之间的权衡,会在下面的Compound Scaling 部分介绍。
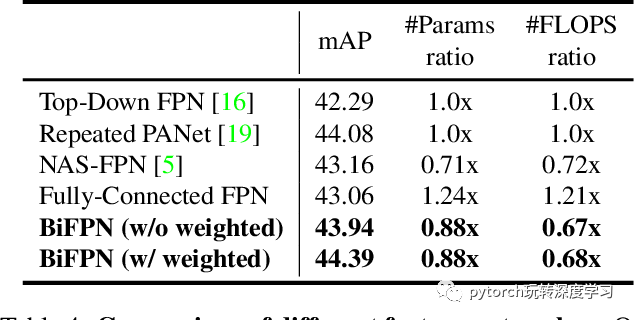
BiFPN 相对 FPN 能涨 4 个点,而且参数量反而是下降的,如下表所示。

Cross-Scale Connections
此外,作者还提出,之前从FPN 开始普遍采用的,一个特征先 Resize ,再和另一层的特征相加的方式不合理。因为这样假设这两层的特征有了相同的权重。从更复杂的建模角度出发,应该每一个 feature 在相加的时候都要乘一个自己的权重。这样 weighted 的方式能涨 0.4,如下表所示:
weigjted 的时候,权重理论上要用 softmax 归一化到和为1,但由于 softmax 的指数运算开销比较大,作者简化为一个快速的方式 (Fast normalized fusion),其实就是去掉了 softmax 的指数运算,在 GPU 上能快 30%,性能微微掉一点,如下表所示:

总结一下 BiFPN 部分,是在 PANet 的基础上,根据一些主观的假设,做了针对性的化简,得到了参数量更少,效果更好的连接方式。
Compound Scaling
下面介绍的 Compound Scaling 部分,可以说是 Mingxing Tan 大佬的拿手好戏。Model Scaling 指的是人们经常根据资源的限制,对模型进行调整。比如说为了把 backbone 部分 scale up,得到更大的模型,就会考虑把层数加深, Res50 -> Res101这种,或者说比如把输入图的分辨率拉大。
EfficientNet 在 Model Scaling 的时候考虑了网络的 width, depth, and resolution 三要素。而 EfficientDet 进一步扩展,把 EfficientNet 拿来做 backbone,这样从 EfficientNet B0 ~ B6,就可以控制 Backbone 的规模;neck 部分,BiFPN 的 channel 数量、重复的 layer 数量也可以控制;此外还有 head 部分的层数,以及 输入图片的分辨率,这些组成了 EfficientDet 的 scaling config 。
从 EfficientDet D0 到 D7 的 “丹方” 如下表所示:
按照这个 “丹方” 可以复现这篇工作,但是这个“丹方”怎么来的作者没有详细说。这里面有非常非常多的超参数,比如 BiFPN 的 channel 数量的增长的公式为

从 EfficientDet D0 到 D7 在 COCO 上的 mAP 结果如下表所示,可以说是吊打其他方法的存在:
结论
这篇 paper 的介绍就告一段落了,个人感觉这篇 paper 虽然性能很好,但是设计的时候基于经验法则、难以解释的参数有很多。