
服装关键点检测算法(CNN/STN)含(4点、6点以及8点)

向AI转型的程序员都关注了这个号👇👇👇
人工智能大数据与深度学习 公众号:datayx
最近几年服饰关键点检测分析引起了人们的广泛关注。以前的具有代表性的工作是服装关键点的检测或人体关节。这项工作提出预测关键位置在时尚物品上定义的点,例如领口的角落,下摆和袖口。然而,由于背景杂乱,人体的姿势和尺度,检测时尚义务上的关键点是具有挑战性的,为了消除上述变化,以前的工作通常是假设在训练和测试中提供的边界的边框作为附加条件,然而这在实践中是不适用的,本项目涉及的是无约束的服装的关键点的检测,无论是训练还是测试所涉及到的是没有提供服饰的边界框,对此我们提出了一种新的网络结构, 此结构主要包含两个部分,首先使用Resnet进行特征提取,然后利用STN空间转换网络除去背景的干扰,最后使用全连接网络进行对关键点的位置和可见性进行预测。
1、 背景介绍 最近几年人们对于视觉时尚分析兴趣不断增加,主要体现在服装属性的预测,衣服的检索 ,关键点的检测。视觉时尚分析给行业会带来巨大的价值。现在现代的神经网络技术以及大型的时尚服饰数据库使我们能够应对这些具有挑战性的任务。2、 初步工作 2.1数据划分 实验室为我们提供了 Consumer-to-shop Clothes Retrieval Benchmark数据集用于服装关键点检测,由于该数据集主要用于训练衣服检索模型,与我们的目标不太符合,因此我们将买家和卖家相应的图片全部用于关键点检测模型训练(即不区分买家和卖家图片)。我们通过list_eval_partition.txt文件将服装图片数据集划分为train - 训练图片集,val - 验证图片集,test - 测试图片集。借助list_bbox.txt中的服装 bbox 标注对原图进行切割,将切割处理后的图片用于训练。实验后期考虑到在 Consumer-to-shop Clothes Retrieval Benchmark数据集上的训练效果不是很好(因为部分买家服装图片对于关键点检测训练干扰较大),我们选择了专门用于服装关键点检测的Fashion Landmark Detection Benchmark数据集,同样借助list_eval_partition.txt文件划分服装图片数据集。由于数据集相对较好,我们不需要bbox 标注切割图片也可以训练模型。对于以上两个数据集,我们均采用先分开训练4点检测,6点检测,8点检测的模型,然后再尝试4,6,8点检测统一训练。我们在各自的数据集上都采用了相应的对比实验以便测试评估最优模型。
2.2数据处理 实验过程主要涉及两类数据处理,图片填充和图像增强。2.2.1图片填充 对于Consumer-to-shop Clothes Retrieval Benchmark数据集,我们首先将切割后的图片等比例放缩,将其宽或者高中相对较长的一边放缩为224,然后相应的进行上下区域填充(切割后的图片宽大于高)和左右区域填充(切割后的图片高大于宽),均采取全黑填充(R,G,B设为0,0,0),最终所有图片尺寸均为224X224,图片的关键点坐标均需做相应变换。对于Fashion Landmark Detection Benchmark数据集,由于图片对于模型训练相对容易,我们直接将所有图片统一填充为512X512的图片,在图片右方和下方区域进行全黑填充,这样就不会影响关键点的坐标。2.2.2图像增强 后期训练过程中,为了防止模型训练过拟合,我们采取了图像增强,调用torchvision.transforms图像预处理包随机改变图像的亮度对比度和饱和度,经过多次训练,发现关键点检测准确率会因此受到影响,我们在最终的模型训练中取消了图像增强。
2.2模型效果的评估 PDL:(PDL is calculated as the percentage of detected landmarks under certain overlapping criterion.)对于大小为512*512的图片,只有当预测出来的关键点与标签所标注的关键点之间的距离小于35个像素值的时才认为该关键点检测正确。NE:图像中所有预测的关键点与标签关键点之间的平均距离的值除以图像的长或宽
代码 获取方式:
分享本文到朋友圈
关注微信公众号 datayx 然后回复 关键点检测 即可获取。
AI项目体验地址 https://loveai.tech
单肩包/双肩包/斜挎包/手提包/胸包/旅行包/上课书包 /个性布袋等各式包饰挑选
https://shop585613237.taobao.com/
3、 模型训练过程 开始的时候,我们使用的模型是VGG16进行对图片的特征的提取,去掉VGG16 的最后两层,加上一个最大池化和一个全连接层,回归输出关键点的位置以及分类输出可见性。
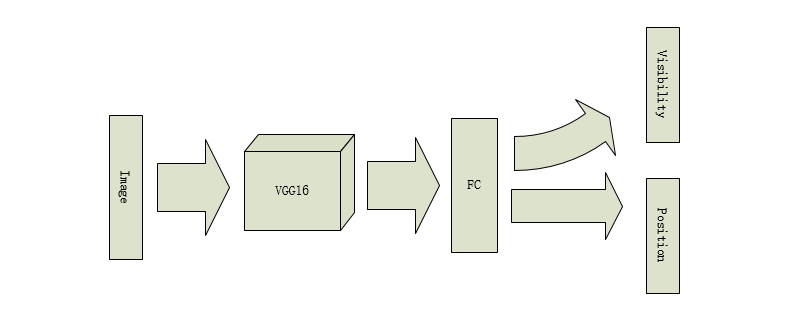
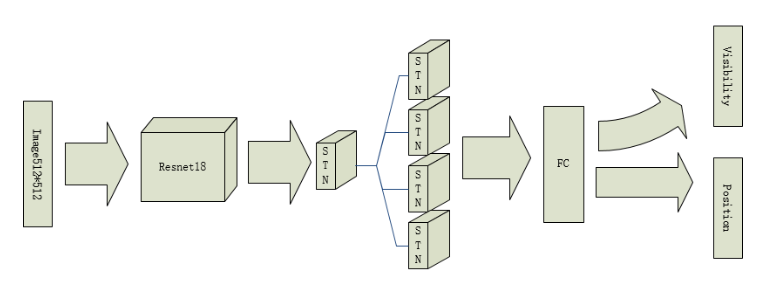
上述的模型对于图像中的背景的影响较为明显,对于在不使用包围盒的情况下的效果并不理想,于是我们采用了STN网络(Spatial Transformer Networks),这个网络的好处是能够使模型能够自己注意到关键检测的目标点的位置,并且这种网络不需要额外的监督,并且不会明显影响网络的运算速度,于是,我们首先使用预训练的Resnet18对处理过的图像进行特征提取,然后使用一个空间变换网络STN在之后并联四个STN用来消除背景的干扰,之后使用全连接层进行对关键点的 可见性以及关键点的位置进行预测。
loss function:
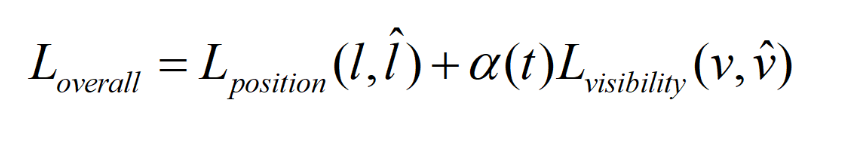
4、 模型训练结果 4.1模型训练数据
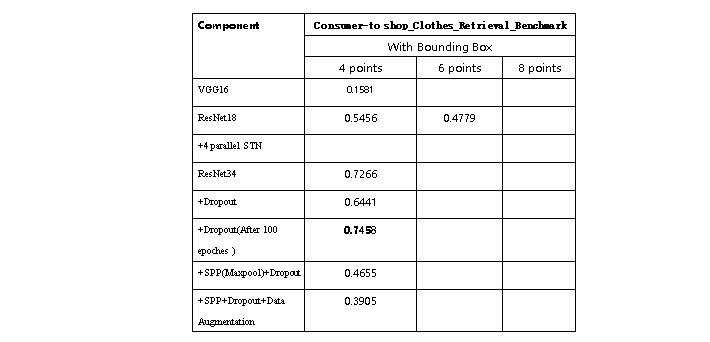
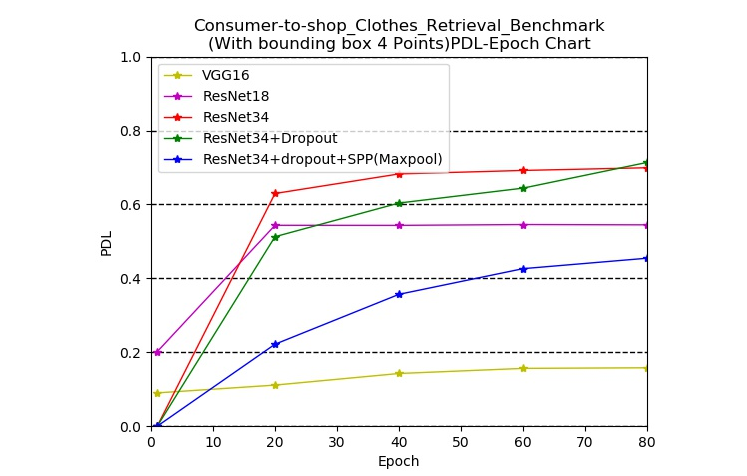
table1:对比各种模型在Consumer-to-shop_Clothes_Retrieval_Benchmark数据集上的效果,主要采PDL指标进行衡量
下图为Consumer-to-shop_Clothes_Retrieval_Benchmark 数据集上检测4个关键点任务中采用VGG6、ResNet18、ResNet34、ResNet34+Dropout正则化以及ResNet+dropout+SPP五种网络结构之间的关键点检测率PDL的对比,其中SPP(空间金字塔池化)中的池化为最大池化,用于替代从最后一个卷积层到第一个全连接层之间的池化层。可以看出随着模型的复杂程度不断地增加, 最终的准确率不断的提升,其中ResNet34+Dropout在最后取得了最高的准确率。其中ResNet34+Dropout+SPP的效果不太理想可能是因为采用了最大池化层以及只选用了11,22,33,44的输出尺寸,相比于ResNet34最后一层的7*7的平均池化较为不佳,关于在第一层全连接层之前采用较大尺寸的平均池化可以取得较好的效果也有许多的研究。
由于之前采用的Consumer-to-shop_Clothes_Retrieval_Benchmark 数据集主要用于卖家与买家的图像检索匹配任务,因此以下的实验我们采用了Fashion Landmark Detection Benchmark数据集进行后续的实验。在之前的实验中我们将BoundingBox作为一个已知的量进行模型的训练,即训练和预测模型的效果的图片都是通过BoundingBox裁剪所得到的,这样会导致需要人为地标注BoundingBox才能利用模型进行预测,这样会导致模型的实际应用价值大打折扣。而在下面Fashion Landmark Detection Benchmark数据集上我们不再利用BoundingBox作为已知条件,以此来增加模型的实用性。
表2为我们的实验结果,其中STN分为参数共享和并行两种结构。
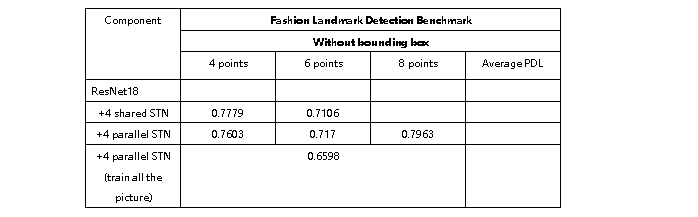
table2:对比各种模型在Fashion Landmark Detection Benchmark数据集上的效果,主要采用PDL指标进行衡量
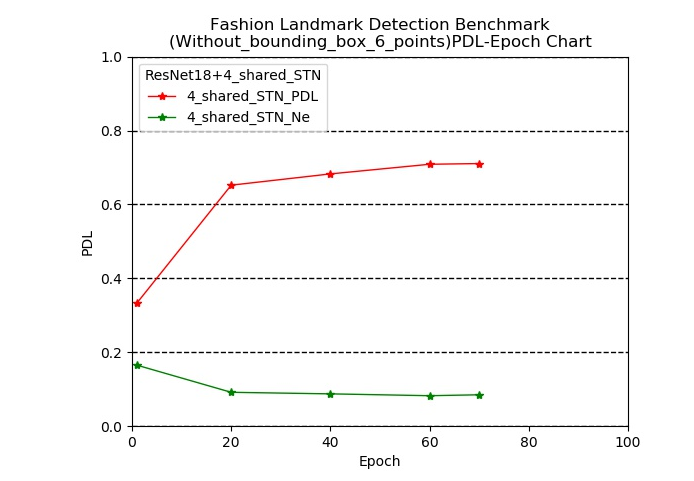
下图为采用ResNet18+4个共享权重的STN下模型训练过程中测试集的PDL以及NE.
4.2 部分图片效果展示
以下为Consumer-to-shop_Clothes_Retrieval_Benchmark数据集4、 6和8个点的部分图片预测效果展示。

以下为Fashion Landmark Detection Benchmark数据集4、 6和8个点的部分图片预测效果展示。
