
纽约大学课程: 深度学习中的优化工具
1梯度下降
我们以所有方法中最基本、最差的(原因后文叙述)的梯度下降法来开始我们对优化方法的学习。
问题:
迭代式:
其中,
是第 次迭代后的更新值, 是第 次迭代前的初始值, 是步长, 是 的梯度。
这里假设函数
迭代更新式中的参数
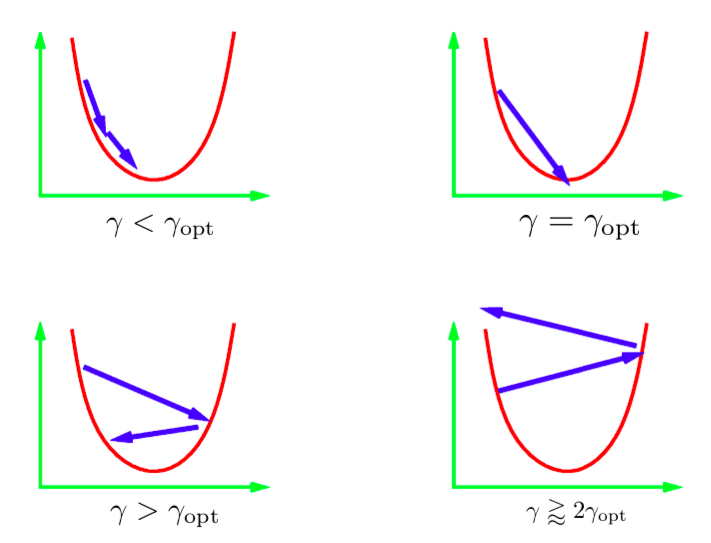
标准的方式是尝试一串呈对数比例的值然后使用最好的值。这里可能会出现一些不同的情况。上面这张图描绘了一元二次函数的情况。如果学习率太小,那么我们将稳定地向最小值前进。但是,这可能会比理想状态更费时。
想得到一个步长值可以直接得到最小值是非常困难的(或者不可能的)。一个比较理想的想法是得到一个比理想步长稍大一点的步长。实际中,这样收敛最快。但是如果我们使用过大的学习率,那么将会迭代至离最小值很远导致不收敛。在实际中,我们想使用稍小于不收敛的学习率。
2随机梯度下降
在随机梯度下降中,我们用梯度向量的随机估计替换实际的梯度向量。专门针对神经网络,随机估计是指单个数据点(单个实例)的损耗梯度。
令
最终我们想最小化的函数是
在SGD中,我们根据
如果
其表达式为:
结果,SGD 的预期第
因此,任何 SGD 更新都与预期的批次更新相同。但是,SGD 不仅具有噪声的更快的梯度下降。除了更快之外,SGD 还可以比全批次梯度下降获得更好的结果。SGD 中的噪声可以帮助我们避免浅的局部最小值,并找到更好的(较深)最小值。这种现象称为 退火.
总的来说,随机梯度下降的优点如下:
1、跨实例有很多冗余信息,SGD 可以防止很多此类冗余计算。 2、在初期,与梯度中的信息相比,噪声较小。因此,SGD 的一步和 GD 的一步实际上一样好 . 3、退火 - SGD 更新中的噪声可阻止收敛到坏的(浅)局部最小值。 4、随机梯度下降计算的成本大大降低(因为您无需遍历所有数据点)。
Ξ小批次处理
在小批次处理中,我们考虑多个随机选择的实例上的损失,而不是仅计算一个实例上的损失。这样可以减少步进更新中的噪声。
通常,我们可以通过使用小型批处理而不是单个实例来更好地利用我们的硬件。例如,当我们使用单实例训练时,GPU使用率很低。分布式网络训练技术将大型微型批处理在群集的机器之间进行分割,然后汇总生成的梯度。Facebook 最近使用分布式训练在一个小时内对 ImageNet 数据上的网络进行了训练。
重要的是要注意,梯度下降绝对不能用于全尺寸批次。如果您想以完整的批次大小进行训练,请使用一种称为 LBFGS 的优化技术。PyTorch 和 SciPy 都提供了该技术的实现。
3动量
在动量中, 我们有两个迭代 (
替代形式: 随机重球法
该形式在数学上与先前的形式等价。在这里,下一步是上一步的方向(
Ξ直观
SGD 动量类似于物理学中的动量概念。优化过程就像一个沉重的球滚下山坡,动量使球保持与已经移动的方向相同的方向,梯度可以认为是沿其他方向推动球的力。

Source:distill.pub[1]
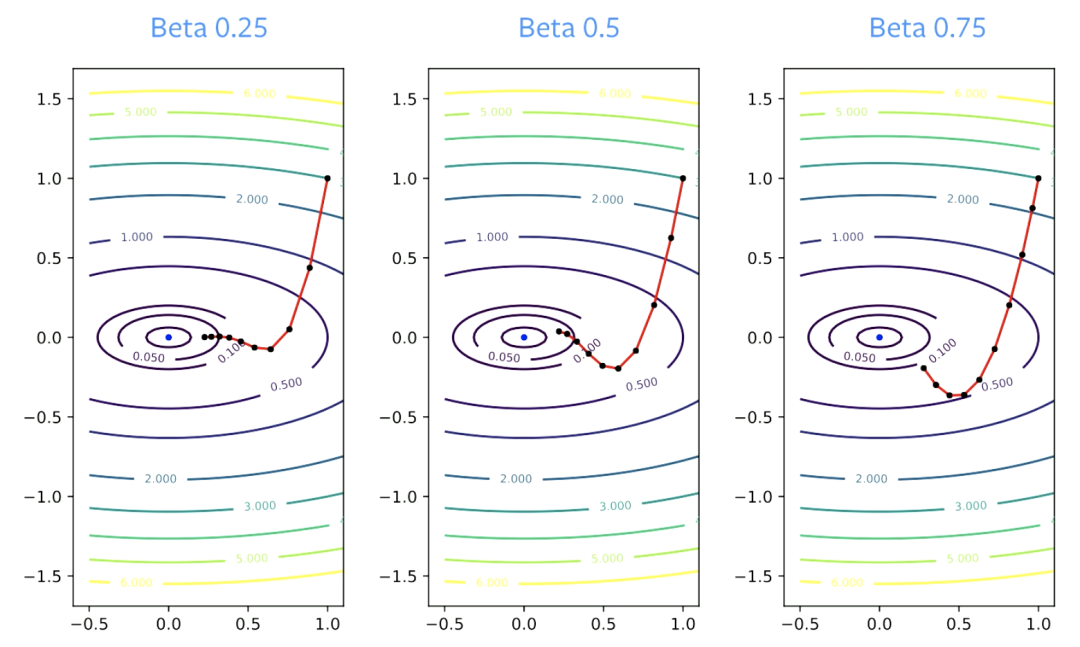
动量并没有使行进方向发生巨大变化(如左图所示),而是产生了适度的变化。动量可减轻仅使用SGD时常见的振荡。
Ξ实用指南
动量必须总是与随机梯度下降一起使用。
当增加动量参数以保持收敛时,通常需要减小步长参数。如果
Ξ为什么动量有用?
加速
以下是涅斯捷罗夫动量的更新规则。
使用涅斯捷罗夫动量,如果你非常仔细地选择常数,则可以加快收敛速度。但这仅适用于凸问题,不适用于神经网络。
许多人说,正常的动量也是一种加速的方法。但实际上,它仅对二次方加速。此外,由于 SGD 带有噪音,加速不适用于 SGD,因此不适用于 SGD。因此,尽管 Momentum SGD 有一些加速作用,但仅凭它并不能很好地解释该技术的高性能。
噪声平滑
可能一个更实际和更可能动量效果很好的原因是噪声平滑。动量均衡了梯度。这是我们用于每个步骤更新的渐变的平均值。从理论上讲,为了使 SGD 能够正常工作,我们应该对所有步骤进行平均。
SGD 具有动量的优点在于,不再需要进行平均。动量为优化过程增加了平滑度,从而使每次更新都很好地接近解。使用 SGD,你需要平均所有的更新,然后朝这个方向前进一步。
加速和噪声平滑都有助于提高动量性能。
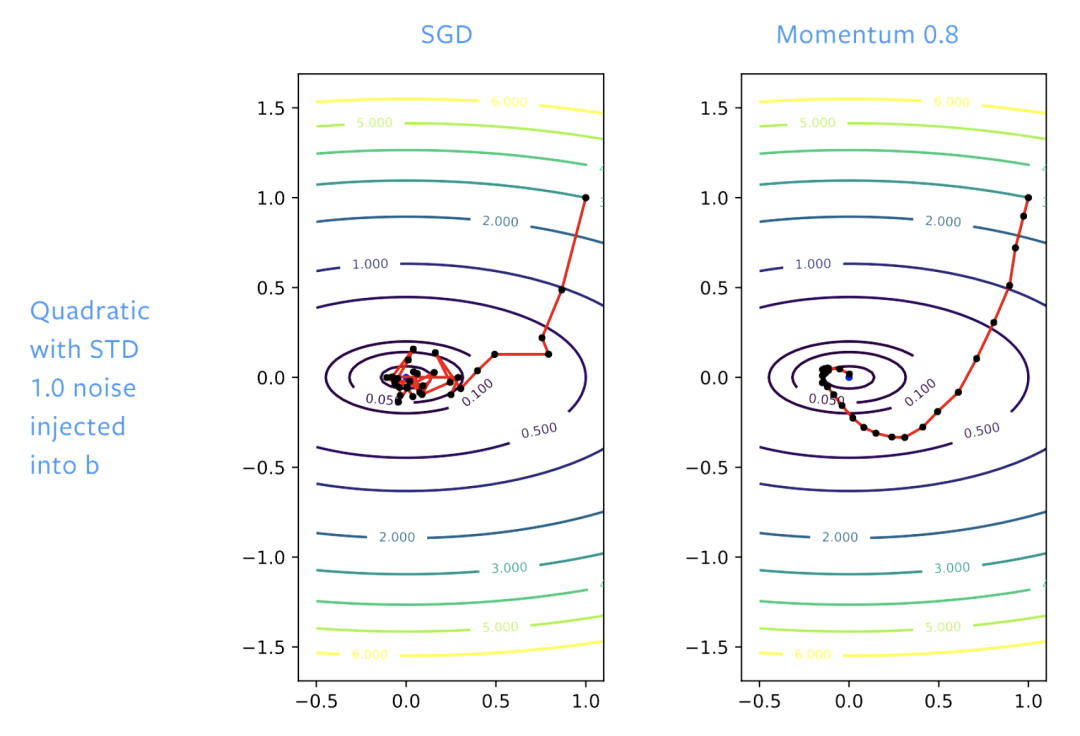
使用 SGD,在求解初期取得良好的进展,但是当到达函数最低区域(谷底)时,会在此反弹。如果我们调整学习率,我们的反弹速度将会变慢。有了动量,就会使步伐变得平稳,以至于没有反弹发生。
https://atcold.github.io/pytorch-Deep-Learning/
⟳参考资料⟲
distill.pub: https://distill.pub/2017/momentum/
[2]原文: https://atcold.github.io/pytorch-Deep-Learning/zh/week05/05-1/