
深度学习中的优化算法与实现
GiantPandaCV导语:这篇文章的内容主要是参考 沐神的mxnet/gluon视频中,Aston Zhang讲解的优化部分 对深度学习调参背后的数学原理进行讲解。文章有些长,小伙伴们可以耐心读完,相信收获一定会很大。本文同步在我的知乎,地址为:https://zhuanlan.zhihu.com/p/35229268
1. 前言
通过这么长时间的学习,我们应该对于通过深度学习解决问题的大体流程有个宏观的概念了吧?
设计模型 构造loss function 通过优化算法,找到一个某种意义上的optim值
其实在找optim的值过程,就是我们通常所说的调参的过程。
同一个model,一样的loss function,为什么不同的人对于同一个数据集会得到不同的结果?这其实就是调参的魅力了。。。
当然,调参并不是盲目的瞎调,也不是靠着运气乱调参,其背后也是遵循着一定的数学原理的。(本人是调参新手,如果说的不对,请各位评论区拍砖指教)
2. 调参背后的数学原理
通过前面关于深度学习的介绍和沐神的视频教程,我们已经接触到了很多优化算法。比如说,在训练模型的时候,不断迭代参数以最小化损失函数。
在大多数的ML问题中,我们往往都是这样做的:
定义一个损失函数 loss function 通过优化算法来最小化这个loss function 找到使得loss function最大或者最小的optim解作为model的parameter值
其实,这个优化过程中更多是针对训练集上进行的,而实际的ML问题求解过程中,我们更需要的是对于测试集上的表现来衡量,比如前面讲过的各种正则化,weight
decay等手段来应对过拟合现象。
在这里,主要关注loss function在训练集上的得到的结果。又把loss function称作目标函数。
现在,再来看看求解优化问题的challenge,我们知道,绝大数深度学习中的目标函数都很复杂。因此,很多优化问题并不存在解析解,所以,我们就需要通过基于数值方法的优化算法来找到目标函数的近似解。而寻找近似解的过程,我们就需要不断迭代更新解的数值,从而找到那个在某种意义上最optim的解。
3. 从梯度下降说起
有关梯度下降的具体概念这里就不详细展开了。
如果不知道的小伙伴,可以去我的模式识别和机器学习笔记专栏中学习。
首先假设我们要学习的参数是 那么, 这里的和都是一维实数集上的一个映射
那么,我们需要回忆下,大学学过的泰勒展开。
因自百度百科中的概念:
数学中,泰勒公式是一个用函数在某点的信息描述其附近取值的公式。如果函数足够平滑的话,在已知函数在某一点的各阶导数值的情况之下,泰勒公式可以用这些导数值做系数构建一个多项式来近似函数在这一点的邻域中的值。泰勒公式还给出了这个多项式和实际的函数值之间的偏差。
通过数学公式表达出来就是:

上述公式中的 往往被替换成为
那么,此时上述的公式就可以被写成
因为,在定义中,往往就是一个非常小的值,那么,其2次方,3次方,一直到n次方,那就几乎等于0了。所以,我们把从第二次方项开始的所有结果的和定义为,这一项被称作无穷小项。
那么此时的式子就被简化成为了:
注意到是一个大于等于0的数
也是一个大于0的数,那么 也是一个大于等于0的数
可以类比到开始我们讲过的公式
那么,此时式子又可以被简化为:
其实,上面这个被简化的式子就是在做一件事情:不断的修改函数自变量的取值,使得其能够满足左边的数值尽可能都小于右边的值,也就是朝着减少的方向一步一步的走。
我们还记着的定义吗?它是一个非常小的数值且接近0,可以通过来替换。
当固定的时候,如果是一个非常大的数值的时候,那么此时的 就不能满足非常小的定义。那么,这个时候 这一项就不能被drop掉,如果不能被drop掉,就不能满足泰勒展开的基本定义。这也就对应了我们在训练的过程中,如果把learning_rate(此处的对应到learning_rate)调的太大,就出现了NaN的情况。 当是一个固定的很小值的时候,如果的初始值选择了一个很大的数值,比如说,这里,那么此时的, ,这一项的数值也会变得非常大。导致其不能满足 不是一个非常小的数值的条件。此时训练肯定也会出问题。
总结:这里就发现了导致model难以训练的两个问题:
学习率的大小选择 初始化参数值的选择
其实, 这仅仅是从一维空间稍微为小伙伴们介绍了下 “调参和其背后数学原理” 的联系。。。
4. 学习率
上述梯度下降算法中的(取正数)叫做学习率或步长。
我们现在就来讨论下,学习率过大和过小会带来什么问题。
4.1 当我们 学习率太小的时候:
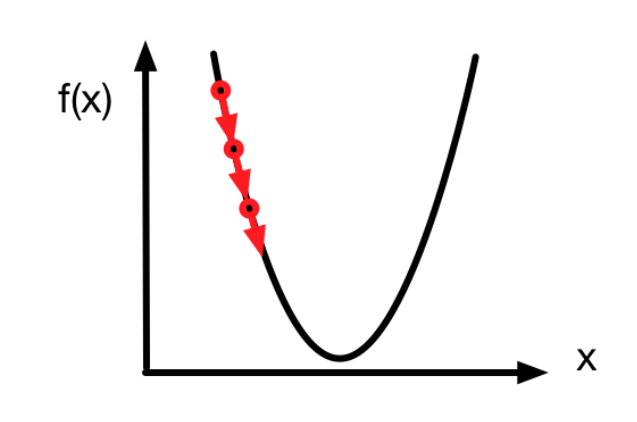
如上图所示,当我们的初始值是从最左边的这个值开始的时候,随着不断迭代,使得不断的增加,我们发现,其一步一步的走向了最低点,如果learning_rate设置的太小,那么走的步数就会相当多,以至于很长时间,loss都没办法收敛。这就是所说的undershoot问题。
试想:如果以相同的学习率走了很多步后,终于走到了上图中的最低点附近,那么是不是很容易就能走到最低点了呢?
答案
:不行的。因为如果我们不对learning_rate进行一个自适应的decay,比如说,随着epoch的增多,learning_rate不断的减小。是很难保证其最终能走到这个真正意义上的最低点的。
4.2 当我们的学习率设置的过大
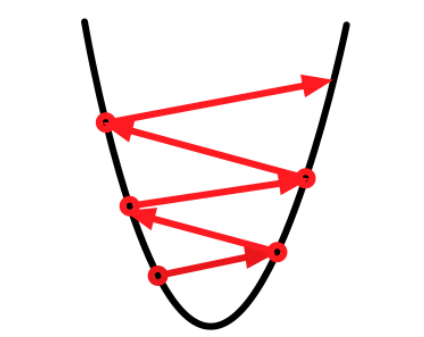
此时,就会产生一个走“之”字型的现象。
假设此时的初始值点是图中左下角的点,那么根据,第一步就走到图中右下角的这个点,然后不断这样迭代,有可能最后整个结果都没办法收敛下来。。。
这也就是在我们调参的过程中,设定太大的learning_rate会导致NaN的情况。
5. 随机梯度下降
然而, 当训练数据集很大的时候,梯度下降法可能会难以使用。
接下来,我们从数学原理方面来解释下为什么数据量变大的时候,往往不去采用梯度下降法
先来看看我们优化问题的目标函数 其中表示的是第个样本所带来的损失 可以观察到,梯度下降每次进行迭代的开销随着n的增长呈线性增长。 因此,如果我们的训练样本个数非常多,那么一次迭代的开销也将非常大
针对这个问题,我们就引入了随机梯度下降(sgd)方法,该方法从所有训练样本中随机均匀采样i,然后计算
。实际上,随机梯度是对梯度
的一个无偏估计,也就是说6. Mini-Batch的随机梯度下降
虽然已经有了梯度下降和随机梯度下降,在实际的训练过程中,我们还是更倾向于使用带有mini-batch的sgd。
它就是说,随机均匀采样一个由训练数据构成的小的batch。然后,通过这个batch上的所有样本点的损失得到最终的损失,更新x的公式都和前面一样,这里就不写了。。。
同样,也可以通过数学来证明mini-batch的sgd对于原始梯度来说,也是无偏估计,证明方法同上。
6.1 算法实现
其实,我们只要实现一个mini-batch的sgd就行了。
当batch_size == 1的时候,就是sgd
当batch_size == 整个训练集大小的时候,就是梯度下降
def sgd( params, lr, batch_size ):
for param in params:
param[:] = param-lr*param.grad/batch_size
实验中,我们以最简单的线性回归为例,完整代码如下:
from mxnet import gluon
from mxnet.gluon import nn
from mxnet import ndarray as nd
from mxnet import autograd
import mxnet as mx
from time import time
from mxnet import sym
import matplotlib.pyplot as plt
import numpy as np
import random
mx.random.seed(1)
random.seed(1)
def sgd( params, lr, batch_size ):
for param in params:
param[:] = param-lr*param.grad/batch_size
# 生成数据集
num_inputs = 2
num_examples = 1000
true_w = [2,-3.4]
true_b = 4.2
X = nd.random_normal(scale = 1,shape = (num_examples,num_inputs))
y = true_w[0]*X[:,0] + true_w[1]*X[:,1] + true_b
y += 0.01*nd.random_normal(scale = 1, shape = y.shape)
dataset = gluon.data.ArrayDataset(X,y)
def data_iter(batch_size):
idx = list(range(num_examples))
random.shuffle(idx)
for batch_i, i in enumerate(range(0,num_examples,batch_size)):
j = nd.array(idx[i:min(i+batch_size,num_examples)])
yield batch_i,X.take(j),y.take(j)
def init_params():
w = nd.random_normal(scale = 1,shape = (num_inputs,1))
b = nd.zeros(shape = (1,))
params = [w,b]
for param in params:
param.attach_grad()
return params
def net(X,w,b):
return nd.dot(X,w)+b
def square_loss(yhat,y):
return (yhat-y.reshape(yhat.shape))**2/2
def train(batch_size, lr, epochs, period):
assert period >= batch_size and period % batch_size == 0
w, b = init_params()
total_loss = [np.mean(square_loss(net(X, w, b), y).asnumpy())]
# 注意epoch从1开始计数。
for epoch in range(1, epochs + 1):
# 学习率自我衰减。
if epoch > 2:
lr *= 0.1
for batch_i, data, label in data_iter(batch_size):
with autograd.record():
output = net(data, w, b)
loss = square_loss(output, label)
loss.backward()
sgd([w, b], lr, batch_size)
if batch_i * batch_size % period == 0:
total_loss.append(
np.mean(square_loss(net(X, w, b), y).asnumpy()))
print("Batch size %d, Learning rate %f, Epoch %d, loss %.4e" %
(batch_size, lr, epoch, total_loss[-1]))
print('w:', np.reshape(w.asnumpy(), (1, -1)),
'b:', b.asnumpy()[0], '\n')
x_axis = np.linspace(0, epochs, len(total_loss), endpoint=True)
plt.semilogy(x_axis, total_loss)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
关于上述代码中参数的说明,当epoch大于2的时候,学习率会有一个自我衰减的过程,也就是lr = lr *0.1。
period参数:每次采用到与period相同数目的数据点后,记录当前目标函数值用于作图。
比如,当batch_size = 10, period = 10,那么,每次迭代一个batch后,都会记录loss的值用于作图。
6.2 调参
现在,我们来分析下不同参数对于loss变化的影响。
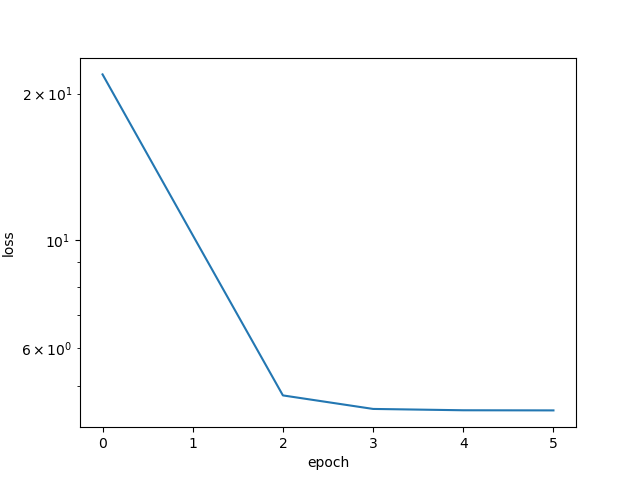
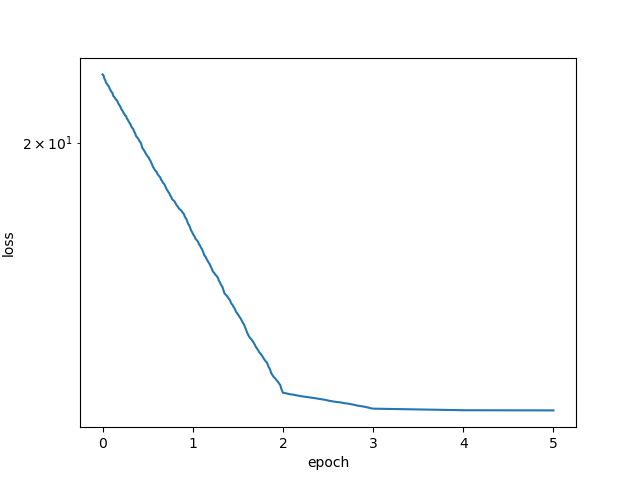
当batch_size = 1时,该训练方式就是sgd,当前lr的情况下,loss function在前期快速减少,当epoch > 2的时候,lr会出现自我衰减,loss function下降后基本收敛,最终学习到的parameter和真实parameter相当。
train(batch_size = 1,lr = 0.1, epochs = 5, period = 10)
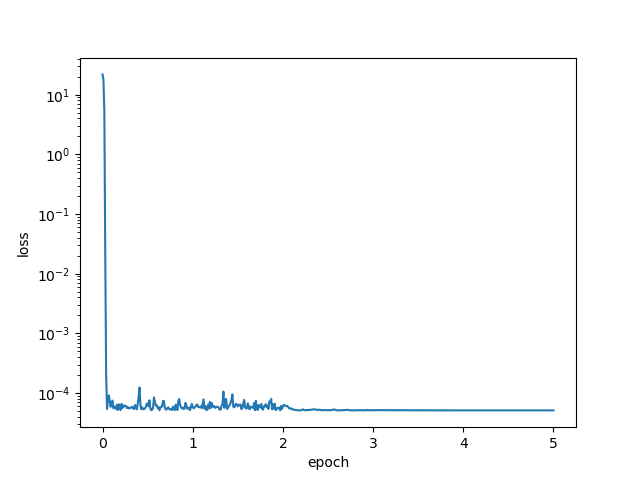
当batch_size = 1000时,由于训练数据集包含1000个样本,此时训练使用的是标注的梯度下降算法。loss function还是在前两个epoch的时候下降较快。当epoch > 2的时候,lr自我衰减。loss function下降缓慢。最终学习到的parameter和真实parameter相当
当batch_size = 10时,由于训练样本中含有1000个样本,此时训练使用mini-batch的sgd来进行。最终学到的parameter与真实parameter相当
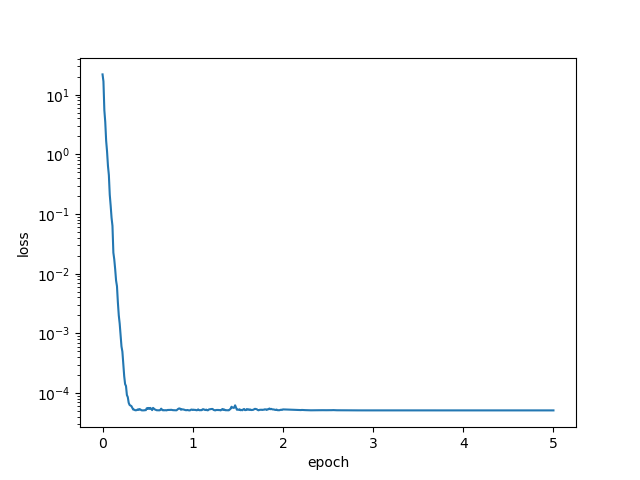
还是针对mini-batch的sgd,当我们把lr调大,那么loss就会出现了nan的情况,也就是前面所分析的由于lr太大,导致loss不断上升。
train(batch_size = 10, lr = 3, epochs = 5, period = 10)
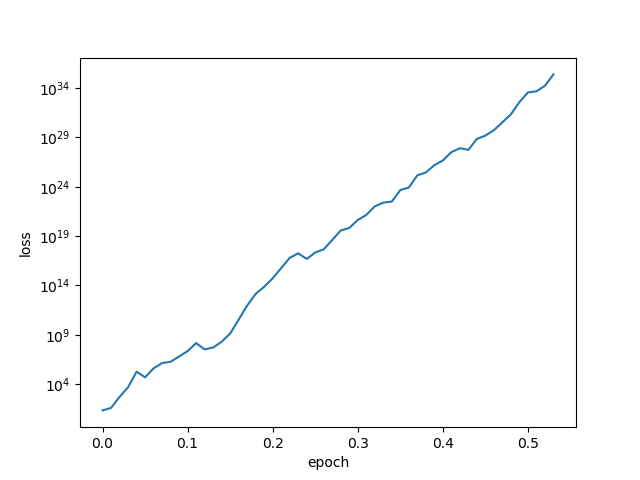
还是针对mini-batch的sgd,当我们把lr调的非常小,那么此时,已经经过了两个epoch,loss下降还是非常缓慢的,这就是前面分析的lr太小,导致收敛过慢
7. 动量法 momentum
动量法在前面的学习中应该有所接触,但是理解的不深。通过Aston Zhang的讲解,我对于为什么要发明这个方法,
以及这个方法所能带来的好处有了更进一步的认识。
先来看下面的图:
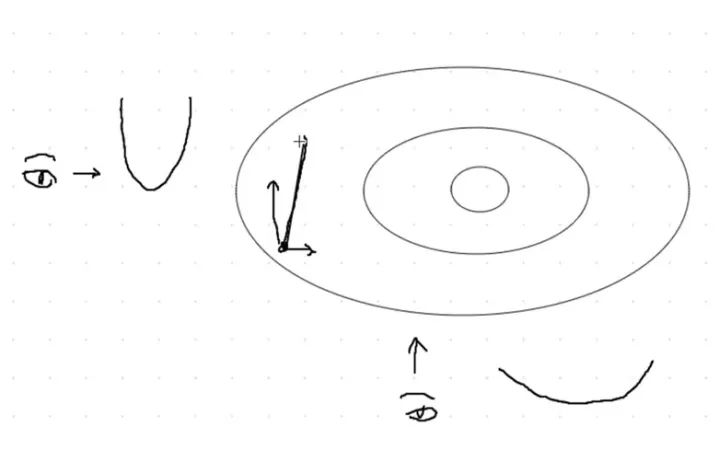
如果我们是从最左边的眼睛看,那么会看到一个变化非常“陡峭”的部分 如果我们是从最下面的眼睛看,那么会看到一个相对“平缓”的部分
那么,结合前面讲过的sgd中lr的选择问题
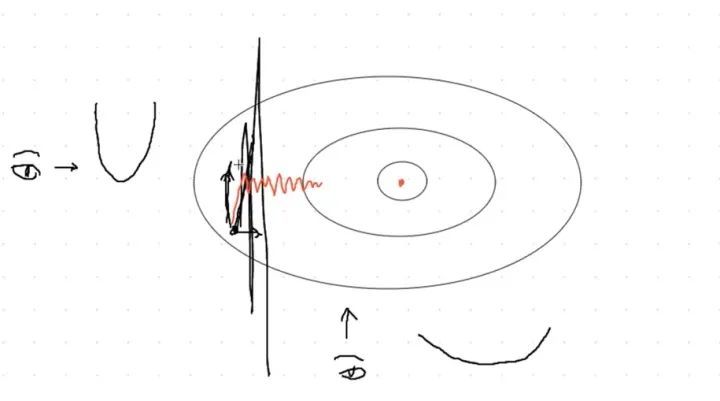
如果lr选择的过大,就会出现overshot问题,模型loss出现nan,黑色线条部分 如果lr选择的过小,就会出现undershot问题,迭代多步仍不收敛,红色线条部分
那么,我们就需要找到一个处于红色部分和黑色部分的折中方式,使得其前进的方向朝着我们的optim值(红色的点)能够更快,更准的移动。
基于这个问题,就出现了 动量法
知道了问题产生的背景,那么我们接下里定义一些符号化的表示。
注意到,当的时候,那么就退化成为了前面讲过的梯度下降方法
现在,我们在对上面有关 的公式进行改写:
我们在引入一个叫做EMA(Estimation Moving Average)的东西,可以把上面这个有关的式子以另外一种更加优美的方式来表示
其实这两种表示在某种意义上是等价的。。。
关于EMA,Aston Zhang通过虚拟货币交易市场中的例子来解释的
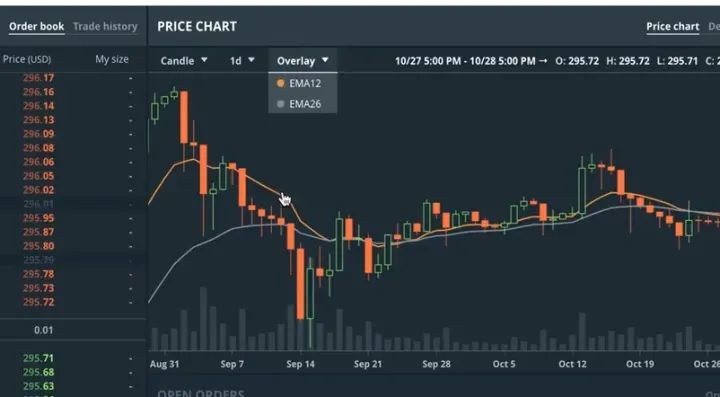
就是说,在一个时时刻刻都在发生频繁交易的市场中,我们想尽可能的通过一条光滑的曲线来模拟这种频繁的抖动和变化。。。类似于moving average的思想。
此时,我们通过对式子中的参数赋予具体的值来达到更加具体化的学习。
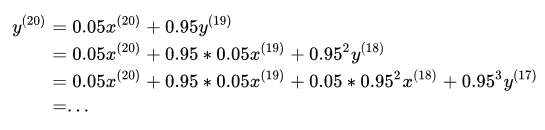 通过这样一步一步的迭代下去。我们可以发现:
通过这样一步一步的迭代下去。我们可以发现:
随着迭代的进行,的指数越大,那么前面的系数就越小 的指数越接近20的项,其前面的系数就越大
那么,再来把上面涉及到的数学公式放在一起看:
就相当于对变成了原来的的倍数。
通过图来形象的解释就是:

其实,就是说,对于:
出现overshot的问题的时候,momentum方法可以对其进行一个裁剪。使得其在方差过大的走偏情况下,能够尽量削弱这种情况,得到尽可能小的方差 出现undershot的问题的时候,momentum方法可以对其进行一个加速,使得这种趋势能够加强。
总结一下:加入momentum能够加速达到optim的值。
现在用代码实现下:
import mxnet as mx
from mxnet import autograd
from mxnet import gluon
from mxnet import ndarray as nd
import numpy as np
import random
mx.random.seed(1)
random.seed(1)
# 生成数据集。
num_inputs = 2
num_examples = 1000
true_w = [2, -3.4]
true_b = 4.2
X = nd.random_normal(scale=1, shape=(num_examples, num_inputs))
y = true_w[0] * X[:, 0] + true_w[1] * X[:, 1] + true_b
y += .01 * nd.random_normal(scale=1, shape=y.shape)
dataset = gluon.data.ArrayDataset(X, y)
net = gluon.nn.Sequential()
net.add(gluon.nn.Dense(1))
square_loss = gluon.loss.L2Loss()
%matplotlib inline
import matplotlib as mpl
mpl.rcParams['figure.dpi']= 120
import matplotlib.pyplot as plt
def train(batch_size, lr, mom, epochs, period):
assert period >= batch_size and period % batch_size == 0
net.collect_params().initialize(mx.init.Normal(sigma=1), force_reinit=True)
# 动量法。
trainer = gluon.Trainer(net.collect_params(), 'sgd',
{'learning_rate': lr, 'momentum': mom})
data_iter = gluon.data.DataLoader(dataset, batch_size, shuffle=True)
total_loss = [np.mean(square_loss(net(X), y).asnumpy())]
for epoch in range(1, epochs + 1):
# 重设学习率。
if epoch > 2:
trainer.set_learning_rate(trainer.learning_rate * 0.1)
for batch_i, (data, label) in enumerate(data_iter):
with autograd.record():
output = net(data)
loss = square_loss(output, label)
loss.backward()
trainer.step(batch_size)
if batch_i * batch_size % period == 0:
total_loss.append(np.mean(square_loss(net(X), y).asnumpy()))
print("Batch size %d, Learning rate %f, Epoch %d, loss %.4e" %
(batch_size, trainer.learning_rate, epoch, total_loss[-1]))
print('w:', np.reshape(net[0].weight.data().asnumpy(), (1, -1)),
'b:', net[0].bias.data().asnumpy()[0], '\n')
x_axis = np.linspace(0, epochs, len(total_loss), endpoint=True)
plt.semilogy(x_axis, total_loss)
plt.xlabel('epoch')
plt.ylabel('loss')
plt.show()
通过momentum的方法,我们先将momentum/设置为0.9,此时正常,并且epoch>2后快速收敛了
train(batch_size=10, lr=0.2, mom=0.9, epochs=5, period=10)
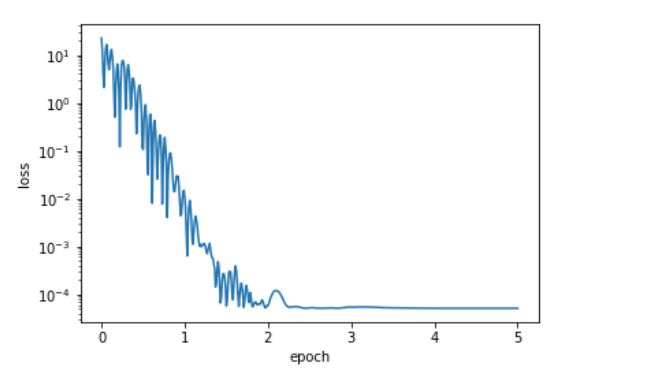
再把 设置的更大,0.99,此时梯度应该变为100倍,已经训练飞了
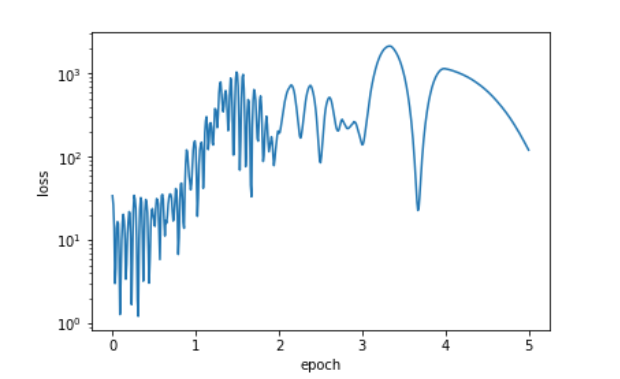
8. Adagrad
在前面讲过的这些优化算法中,基本都是使用同一个learning_rate来更新所有的参数。
举个二元函数的例子 ,假设学习率为 ,那么参数的更新过程就是:
那么,Adagrad要做的,就是对于不同的parameter,使用不同的learning_rate进行更新,并且其在迭代的过程中,能够不断自我调整learning_rate。
Adagrad算法具体是这样操作的:
使用一个梯度按元素平方的累加变量 其中就是通过mini-batch的计算得到的梯度 然后通过下面的式子对模型中每个参数的学习率通过按照元素重新调整 其中 是初始学习率,是为了维持数值稳定性而添加的元素,防止分母除以0 然后再通过对相应的parameter进行了更新
Adagrad算法的核心思想:我们注意到其实是一个累加项的过程,
如果loss function相对于某一个parameter的偏导数一直都很大,那么就让他下降的快一点。 如果loss function相对于某一个parameter的偏导数一直都比较小,那么就让他下降的慢一点。
关于Adagrad的实现,我们只要将上述数学公式翻译成python代码即可:
def adagrad( params, sqrs, lr, batch_size):
eps_stable = 1e-7
for param, sqr in zip(params,sqrs):
g = param.grad/batch_size
sqr[:] += nd.square(g)
div = lr*g/nd.sqrt(sqr+eps_stable)
param[:] -= div
整个程序的实现代码和上述相似,这里就不写了,具体可以看看沐神的gluon教程。
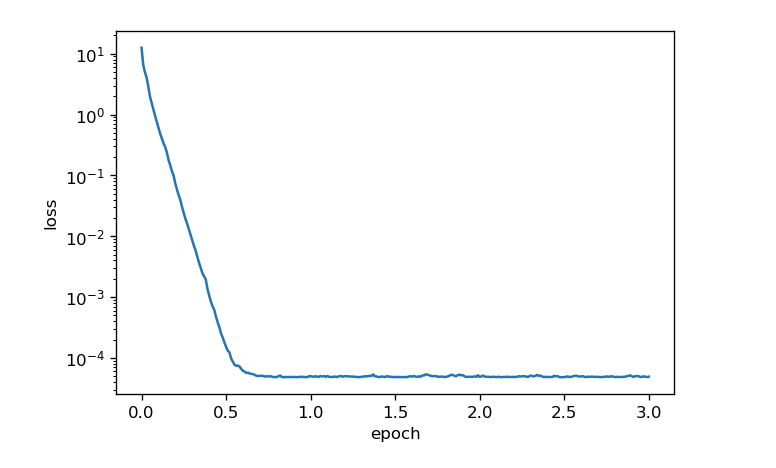
9. RMSProp
在前面刚刚讲过的Adagrad中,每个参数都有一个适应自己的learning_rate去更新,但是,当学习率在迭代早起降得比较快且这个时候的解依然比较不理想的时候,那么有可能在就找不到一个更加理想的解了,也就是early
stopping到了一个并不是我们认为最optim的点。
所以,RMSProp是对adagrad的一个改进。。。
其实,看到RMSProp的第一个式子,我就相当了Aston将的EMA的例子。看下面的公式
相比adagrad算法,RMSProp增加了一个衰减系数来控制对历史信息的获取多少。
剩下的公式和adagrad是一样的。。。
写成代码:
def rmsprop(params, sqrs, lr, gamma, batch_size):
eps_stable = 1e-8
for param, sqr in zip(params, sqrs):
g = param.grad / batch_size
sqr[:] = gamma * sqr + (1. - gamma) * nd.square(g)
div = lr * g / nd.sqrt(sqr + eps_stable)
param[:] -= div
当我们把这个系数设置为0.9,得到下面的曲线
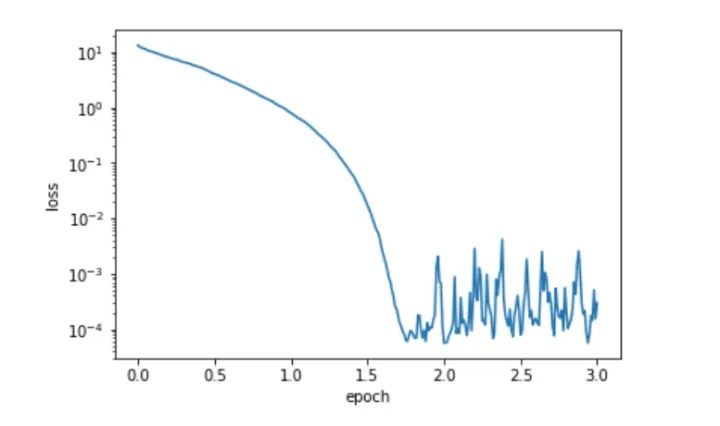
再将设置的大一些,比如0.999,发现后期的曲线就比较平滑了
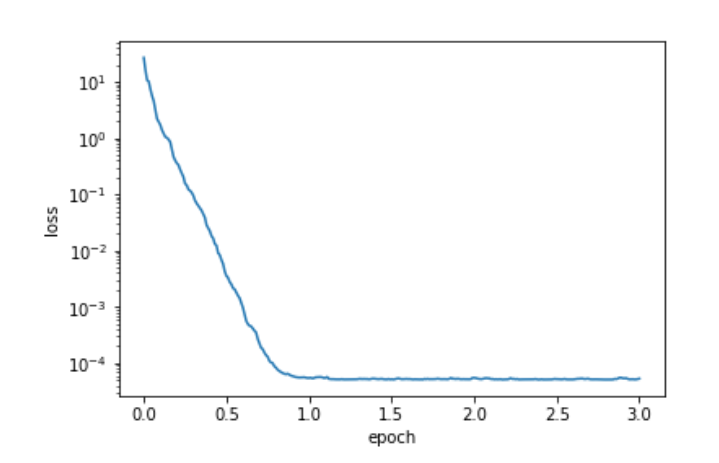
10. Adam
Adam算法其实是前面讲过的momentum方法和RMSProp方法的组合。
它使用了一个动量变量 和一个RMSProp中梯度安装元素平方的指数加权移动平均变量
每次的迭代
在Adam算法里,为了减轻 和被初始化为0,在迭代初期对于计算指数加权移动平均的影响,进行了如下的修正:
在教程中讲到,,并且他们都在之间。当我们随着迭代的进行,比较大的时候,其对于和将不会有太大的影响。
接下来通过:
Adam的实现:
def adam(params, vs, sqrs, lr, batch_size, t):
beta1 = 0.9
beta2 = 0.999
eps_stable = 1e-8
for param, v, sqr in zip(params, vs, sqrs):
g = param.grad / batch_size
v[:] = beta1 * v + (1. - beta1) * g
sqr[:] = beta2 * sqr + (1. - beta2) * nd.square(g)
v_bias_corr = v / (1. - beta1 ** t)
sqr_bias_corr = sqr / (1. - beta2 ** t)
div = lr * v_bias_corr / (nd.sqrt(sqr_bias_corr) + eps_stable)
param[:] = param - div
当学习率为0.1的时候,曲线图如下
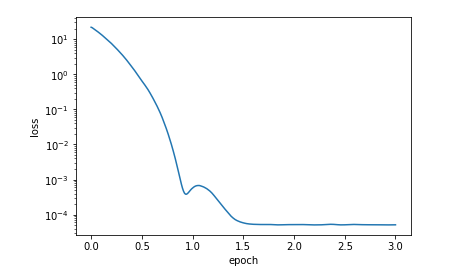
11. Adadelta
前面,我们已经介绍了有关momentum,RMSProp,Adagrad,Adam算法,这些算法有一个共性就是都带有学习率,这一部分介绍的Adadelta算法是没有learning_rate这个参数的。
其计算过程和RMSProp一样:
首先 然后计算需要更新的parameter的变化量: 这里相比前面的算法出现了 ,初始化为零张量。 且其计算表达式为 的取值一般在0.9~0.999范围内,当然也可以根据情况来调
代码实现:
def adadelta(params, sqrs, deltas, rho, batch_size):
eps_stable = 1e-5
for param, sqr, delta in zip(params, sqrs, deltas):
g = param.grad / batch_size
sqr[:] = rho * sqr + (1. - rho) * nd.square(g)
cur_delta = nd.sqrt(delta + eps_stable) / nd.sqrt(sqr + eps_stable) * g
delta[:] = rho * delta + (1. - rho) * cur_delta * cur_delta
param[:] -= cur_delta
当,batch_size = 10时候的loss曲线图
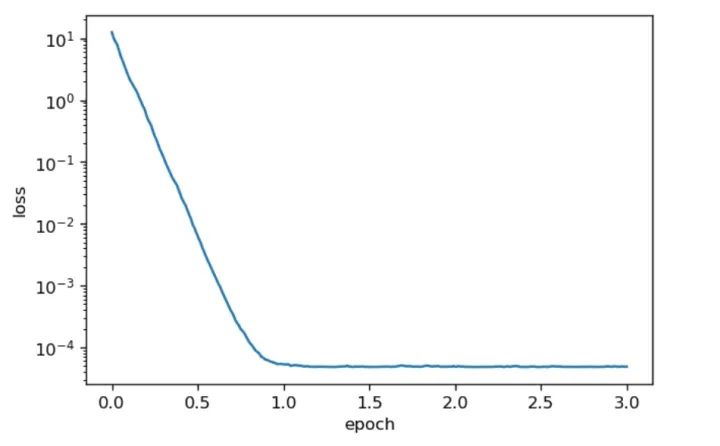
可以发现,整个过程中,没有出现有关learning_rate的任何信息,同样做到了很好地优化。。
12. 总结
有关优化的算法,大体上就按照Aston zhang的讲解介绍这么多,希望大家在理解了基本的概念以及每一个优化算法背后的原理后,在使用gluon的时候,就能“自信”的在trainer中设置自己想要的优化算法了。
- END -欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:
为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。