
Image-Level 弱监督图像语义分割汇总简析
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来源:知乎 作者:Uno Whoiam 链接:https://zhuanlan.zhihu.com/p/80815225 本文已由作者授权转载,未经允许,不得二次转载。
总结
Learning Pixel-level Semantic Affinity with Image-level Supervision for Weakly Supervised Semantic Segmentation
https://arxiv.org/abs/1803.10464
成绩:
VOC 2012 val:61.7%
VOC 2012 test:63.7%

参考链接:
论文笔记 Learning Pixel-level Semantic Affinity with Image-level Supervisionfor Weakly Supervised Semantic Segmentation - cv module | d
Robert Yang:弱监督语义分割psa算法笔记

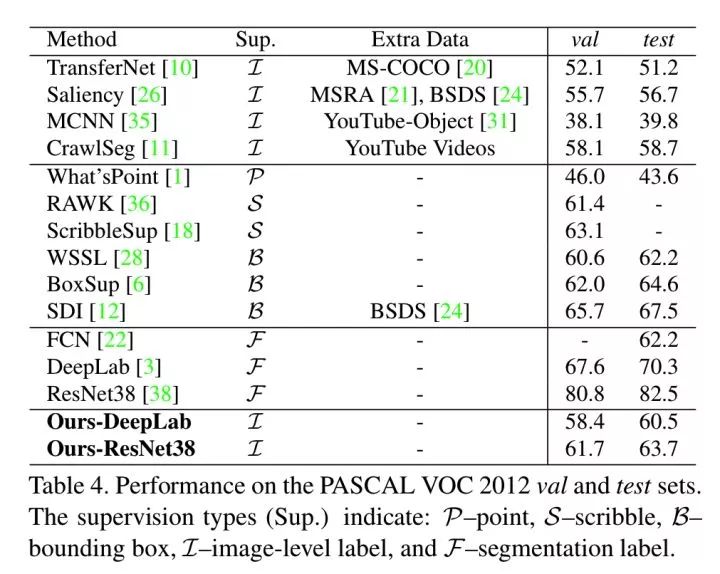
Revisiting Dilated Convolution: A Simple Approach for Weakly- and Semi- Supervised Semantic Segmentation
https://arxiv.org/abs/1805.04574
成绩: VOC 2012 val:60.4 VOC 2012 test:60.8
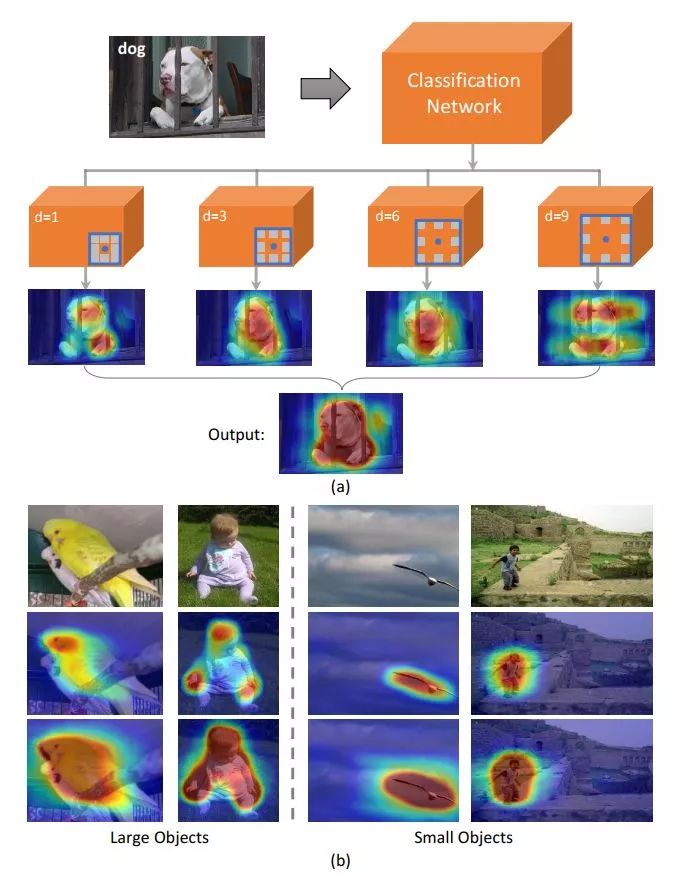

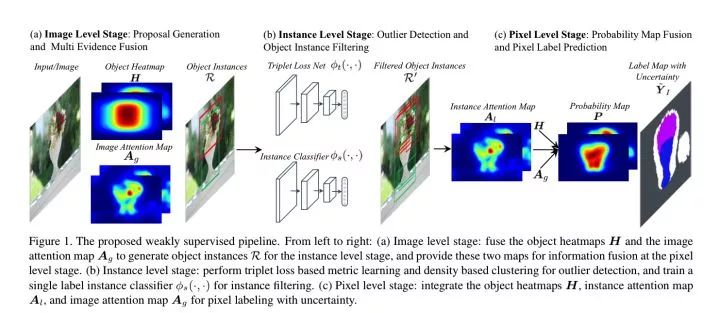
Multi-Evidence Filtering and Fusion for Multi-Label Classification, Object Detection and Semantic Segmentation Based on Weakly Supervised Learning
https://arxiv.org/abs/1802.09129
成绩:
VOC 2012 val:null
VOC 2012 test:55.6
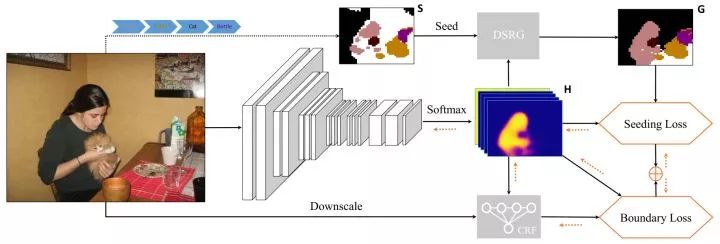
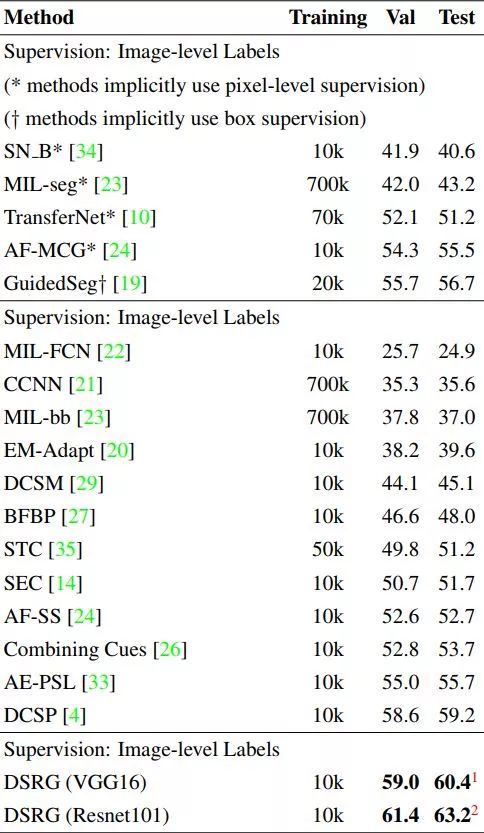
Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing
http://openaccess.thecvf.com/content_cvpr_2018/papers/Huang_Weakly-Supervised_Semantic_Segmentation_CVPR_2018_paper.pdf
成绩:
VOC 2012 val:61.4
VOC 2012 test:63.2

参考链接:
MurphyAC:弱监督下的语义分割:DSRG
《Weakly-Supervised Semantic Segmentation Network with Deep Seeded Region Growing》笔记
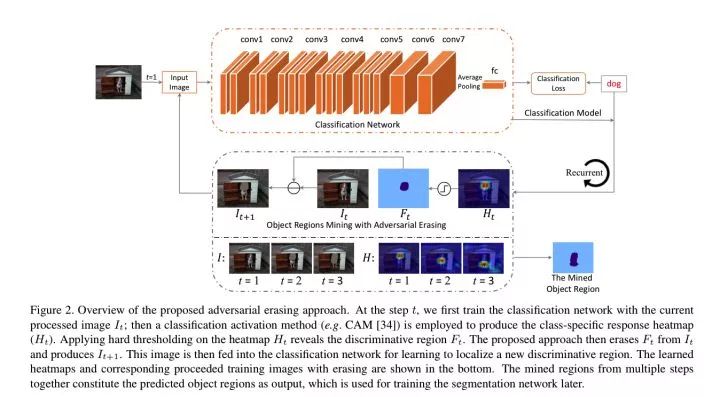
Object Region Mining with Adversarial Erasing: A Simple Classification to Semantic Segmentation Approach
https://arxiv.org/abs/1703.08448
成绩:
VOC 2012 val:55%
VOC 2012 val:55.7%
此论文方法十分魔性:
loop:step 1: 训练好的分类网络,它会找出图片最 discriminative 的部分。step 2: 擦掉分类网络所找出的图片最 discriminative 的部分,用这些图片重新训练分类网络。
循环多次后,把擦除的部分拼在一起,就可以当做 Segmentation Mask 了。
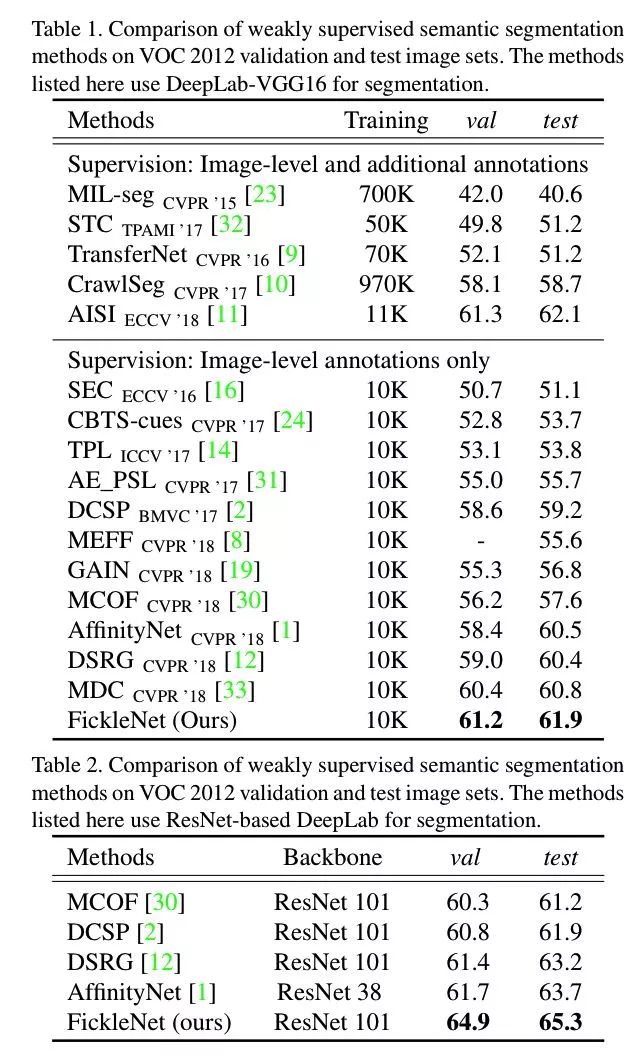
FickleNet: Weakly and Semi-supervised Semantic Image Segmentation using Stochastic Inference
https://arxiv.org/abs/1902.10421
成绩:
VOC 2012 val:64.9
VOC 2012 test:65.3
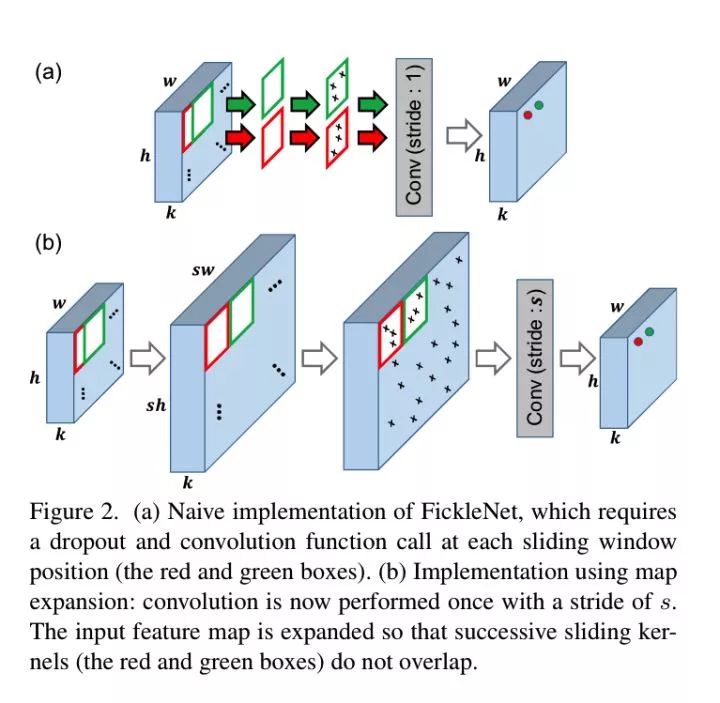
FickleNet 的实现:
在展开特征图,我们在x上应用零填充,这样最终输出的大小就等于输入的大小。补零后的特征图大小为kx(h+s-1)(w+s-1),其中s为卷积核的大小(w方向或者h方向, 需要补充的部分实际上就是卷积核大小减去1的值)。
我们展开零填充的特征图,这样连续的滑动窗口位置就不会重叠,并且展开的特征图 x^expand的大小为kx(sh)x(sw)(相当于在每个wxh平面上的元素都对应着一个sxs大小的映射区域)。
然后,我们使用保留中心的dropout技术来选择x^expand上的隐藏单元。虽然扩展后的特征图需要更多的GPU内存,但是需要训练的参数数量保持不变(因为还是那些卷积权重, 只是跨步大了些),GPU的负载没有明显增加,
训练时的Classifier
为了得到分类分数:
对dropout处理过的特征图,用大小为s和步长为s的核进行卷积。
2. 然后我们得到一个大小为cxwxh的输出特征图,其中c是对象类的数量。
4. 将全局平均池化(会获得一个长为c的向量)和一个sigmoid函数应用到特征图上,得到一个分类得分s(1xc).
5. 然后使用sigmoid交叉熵损失函数更新FickleNet,该函数广泛用于多标签分类。(这里使用的应该是softmax)
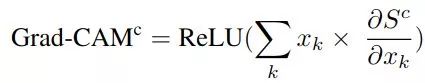
参考链接:
FickleNet: Weakly and Semi-supervised Semantic Image Segmentationusing Stochastic Inference · 语雀
凭什么相信你,我的CNN模型?(篇一:CAM和Grad-CAM)
spytensor.com/index.php
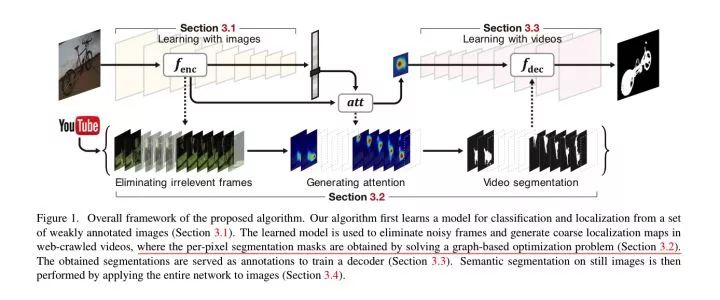
Weakly Supervised Semantic Segmentation using Web-Crawled Videos
http://zpascal.net/cvpr2017/Hong_Weakly_Supervised_Semantic_CVPR_2017_paper.pdf
成绩:
VOC 2012 val:58.1
VOC 2012 test:58.7
1. 使用 VOC 2012 的 Image-Level label 训练VGG。
参考链接: 论文笔记 Weakly Supervised Semantic Segmentation using Web-Crawled Videos - cv module | d
Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation
https://arxiv.org/abs/1506.04924
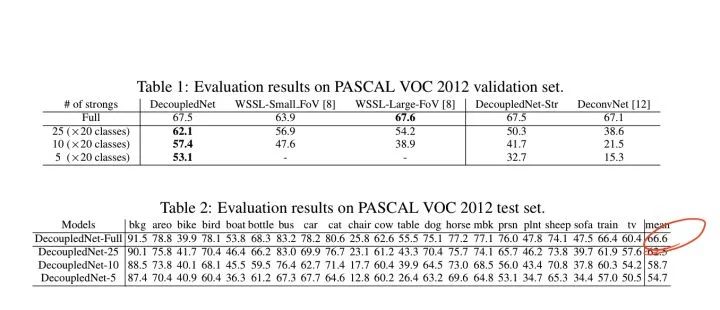
成绩 (0.5k mask+10k label):
VOC 2012 val:62.1
VOC 2012 test:62.5
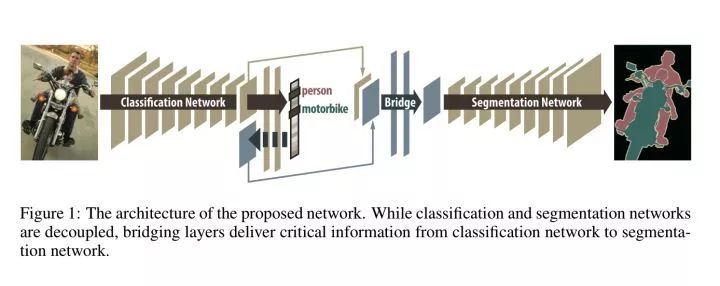
参考链接:论文阅读笔记十四:Decoupled Deep Neural Network for Semi-supervised Semantic Segmentation(CVPR2015)
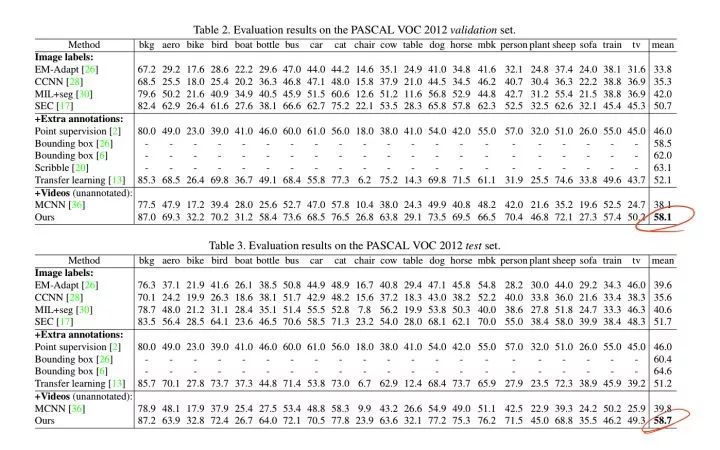
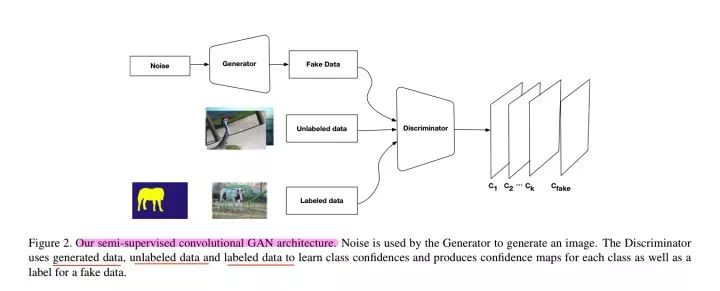
Semi and Weakly Supervised Semantic Segmentation Using Generative Adversarial Network
https://arxiv.org/abs/1703.09695
成绩(1.4k mask + 10k label):
VOC 2012 on val:65.8
VOC 2012 on val:null
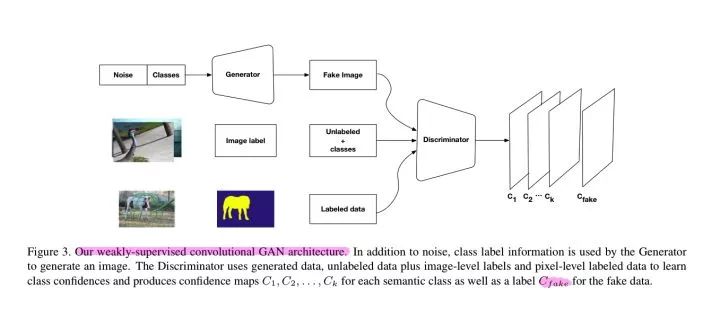
在 VOC 上的实验,使用 1.4K 的强标签,其它将近 10K 张图作为带 Image-Level label 的数据,以及 Generator 产生的假数据进行训练,这次输入 Generator 的不止是 noise,还有 label。根据作者的意思,这样可以提高 Discriminator 发现图片与label 之间的关联。
The rationale of exploiting weak supervision in our framework lies on the assumption that when image classes are provided to the generator, it is forced to learn co- occurrences between labels and images resulting in higher quality generated images, which, in turn, help our multi- classifier to learn more meaningful features for pixel-level classification and true relationships between labels.
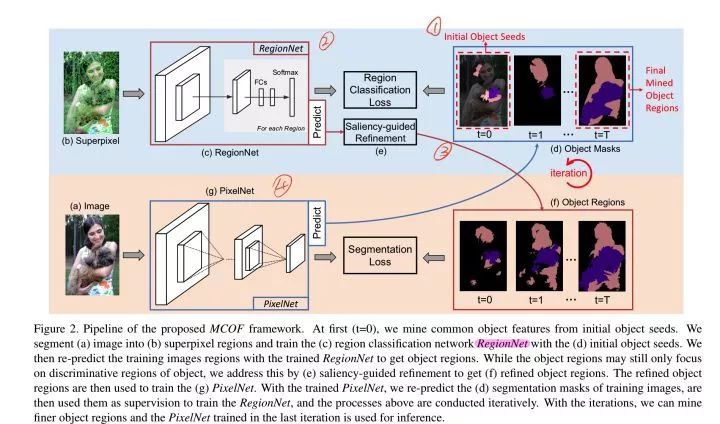
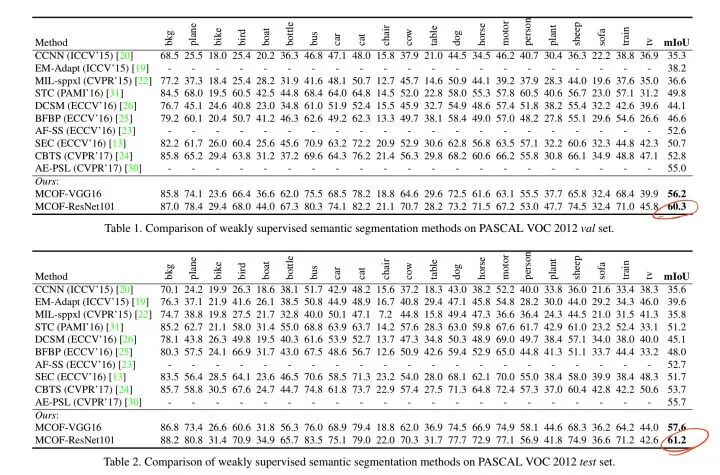
Weakly-Supervised Semantic Segmentation by Iteratively Mining Common Object Features
https://arxiv.org/abs/1806.04659
成绩:
VOC 2012 val:60.3
VOC 2012 val:61.2
同样是 CAM 为起点,然后迭代优化 Segmentation Mask,算法简要流程如下:
以 CAM 为初始 Object Seeds,训练 RegionNet。
RegionNet 的输出经过 Saliency-Guided Refinement (反正就是一种人为设计的先验)优化后得到 Segmentation Mask。
用得到的 Segmentation Mask 训练分割网络 PixelNet。
将 PixelNet 的输出作为 Object Seeds。
参考链接:《Weakly-Supervised Semantic Segmentation by Iteratively Mining Common Object Features》笔记
Weakly Supervised Instance Segmentation using Class Peak Response
https://arxiv.org/abs/1804.00880
成绩:
VOC 2012 val:53.4


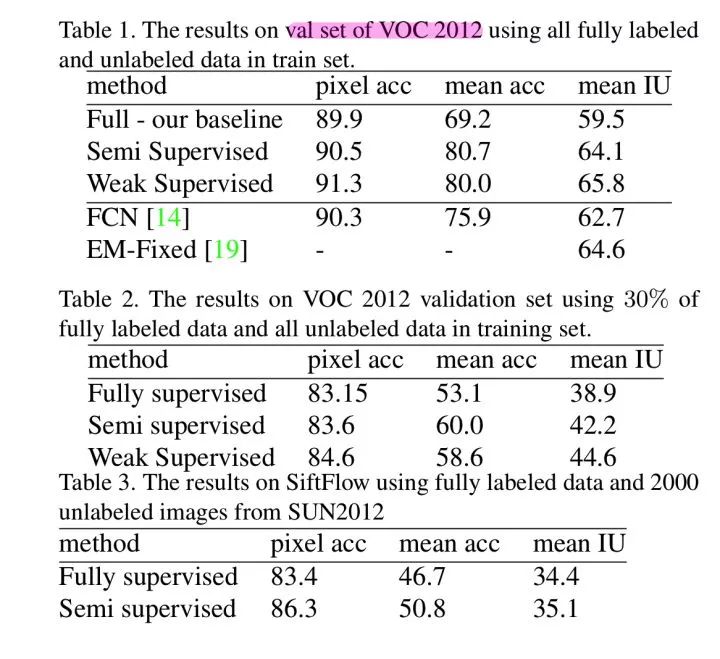
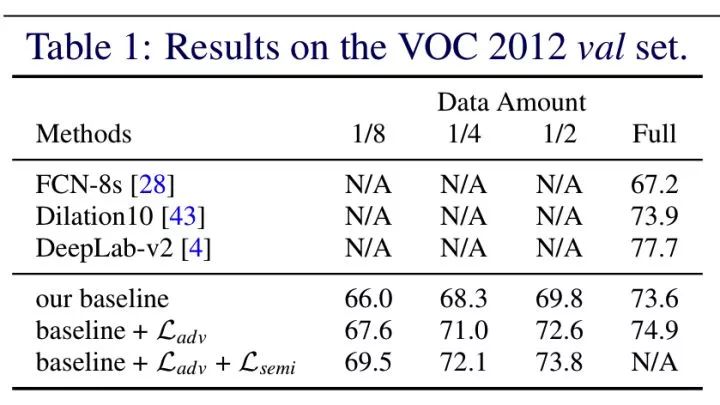
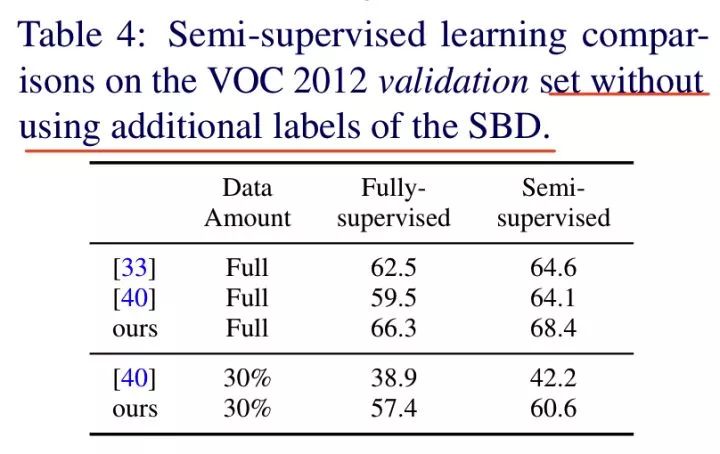
Adversarial Learning for Semi-Supervised Semantic Segmentation
https://arxiv.org/abs/1802.07934
成绩:
VOC 2012 val:68.4% (1.4k mask + 9k unlabeled)

带segmentation mask 标注的数据
没有标注的数据
生成网络为 FCN-style 的网络,输入图像生成 mask
判别网络输入 mask 生成 confidence map
Cross Entropy Loss
Adversarial Loss
Semi-Supervised Loss
好消息!
小白学视觉知识星球
开始面向外开放啦👇👇👇
下载1:OpenCV-Contrib扩展模块中文版教程 在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。 下载2:Python视觉实战项目52讲 在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。 下载3:OpenCV实战项目20讲 在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。 交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~