
CVPR 2022 | 武大&京东提出:使用Transformer的端到端弱监督语义分割

极市导读
在基于图像级别标注的弱监督语义分割问题中,CNN分类模型中卷积操作的局部信息感知会导致不完全的语义区域激活。为解决这个问题,本文引入视觉Transformer结构,并探索了适合视觉Transformer的初始伪标签生成方法。 >>加入极市CV技术交流群,走在计算机视觉的最前沿
在基于图像级别标注的弱监督语义分割问题中,CNN分类模型中卷积操作的局部信息感知会导致不完全的语义区域激活。为解决这个问题,本文引入视觉Transformer结构,并探索了适合视觉Transformer的初始伪标签生成方法。同时,受视觉Transformer中学习到的自注意力与图像中的语义Affinity的一致性启发,本文提出了一个Affinity from Attention(AFA)模块,从Transformer的注意力矩阵中学习高质量的语义Affinity信息,用于对初始伪标签进行改善。为了进一步补充伪标签的局部细节信息,同时保证端到端训练的效率,本文基于像素自适应卷积设计了一个高效的处理模块。本文提出的方法在两个数据集上超过了当前的端到端方法,以及部分多阶段方法。
本工作是由京东探索研究院、武汉大学、悉尼大学联合完成,已经被CVPR 2022接收。

Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers
论文链接:https://arxiv.org/abs/2203.02664
代码链接:https://github.com/rulixiang/afa
01 研究背景及动机
弱监督语义分割(WSSS)的目标在于基于仅有弱标注(如image-level类别标签)的数据训练模型生成像素级的预测。目前主流的弱监督语义分割方法通常首先训练分类模型,基于类别激活图(CAM)或其变种生成初始伪标签;然后对伪标签进行细化作为监督信息训练一个独立的语义分割网络作为最终模型。其中,分类模型一般基于卷积网络,无法准确感知图像中的全局特征关联,导致初始伪标签通常只覆盖语义物体中最具有判别性的部分,显著影响了最终语义分割的效果。

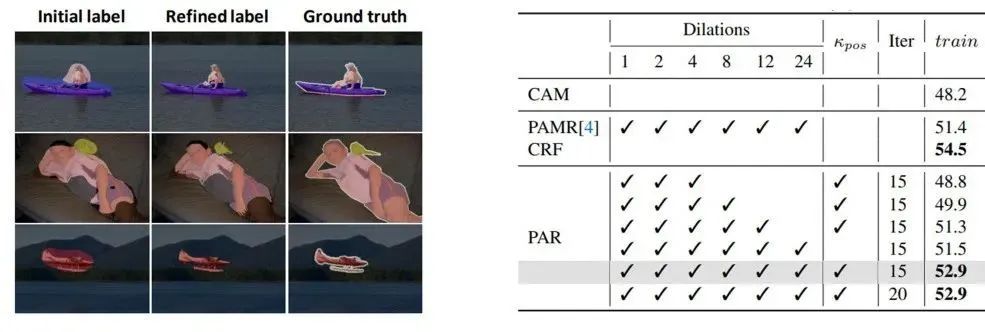
本文引入视觉Transformer结构来解决这个问题。首先,视觉Transformer中的自注意力机制天然保证了全局特征感知,解决了CNN的局部性缺陷,因而能提高初始伪标签的准确性。同时如图1所示,自注意力图和像素之间的semantic affinity也存在天然的一致性,而语义affinity可以被进一步用于对初始伪标签进行细化。然而,如图2所示,由于自然学习到的自注意力矩阵缺乏监督信息,直接将原始自注意力矩阵作为affinity信息对伪标签进行细化并不能取得令人满意的效果。

基于(c)多头注意力、(d)学习到的affinity的伪标签细化结果
我们提出了Affinity from Attention(AFA)模块,以初始伪标签作为监督信息指导自注意力的训练,从而学习到高质量的affinity信息,用于伪标签的改善。
02 方法介绍

如图3所示,本文使用Transformer作为基础编码器。初始伪标签由CAM方法生成,然后使用提出的像素自适应细化模块(PAR)进行修正。在affinity学习模块(AFA)中,从Transformer中的多头自注意力(MHSA)生成语义affinity预测。AFA使用基于细化初始伪标签的伪affinity标签进行监督。然后,利用学习到的affinity通过随机游走方法对初始伪标签进行改善。在经过PAR的进一步修正后,作为分割分支的监督信息。
1、 视觉Transformer网络
如上所示, 本文的方法使用视觉Transformer作为基础网络。在视觉Transformer网络中, 对于输入图像, 首先将其划分成 个patch, 然后经过线性层得到相同数量的patch token。在每个block中, Transformer使用多头自注意力 (MHSA)学习token之间的特征关联。具体而言, 用 分别表示注意力中的query, key和value, 其中 表示MHSA的序号, 对应注意力矩阵和输出分别计算为:
多头注意力的输出会进行拼接,然后输入到FFN层作为Transformer block的输出。
2、初始伪标签
考虑到生成伪标签的简洁性和效率,我们采用CAM作为初始的伪标签,其计算方法为使用分类层的权重对特征图进行加权,使用ReLu函数消除负激活值后进行归一化,再选取合适的背景阈值得到初始的伪标签。
3、AFA模块
我们注意到Transformer中的MHSA和语义affinity之间的一致性。然而,由于在训练过程中没有对MHSA施加明确的约束,因此在MHSA中学习到的affinity通常是不准确的,这意味着直接应用MHSA来细化初始标签并不能很好得到令人满意的效果。因此,我们提出了AFA模块学习准确的affinity信息。
假设一个Transformer block中的多头注意力表示为,在AFA中我们直接用简单的MLP层对其进行映射输出affinity矩阵的预测。本质上,自注意力结构是一种像素间有向的建模方式(即自注意力矩阵是不对称的),而语义affinity的关联应当是无向的,因此我们简单地将和其转置进行相加来达到这种转换:
为了学习到可靠的affinity矩阵 , 关键的一步是生成可靠的伪affinity标签对其进行监督。为了得到可靠的伪标签, 我们选取两个背景阈值将初始伪标签分为可靠的前景、背景和不确定区域, 根据可靠区域的标签关系得到可靠的伪affinity标签 。然后计算affinity损失为:
根据上式,一方面网络能从MHSA中学习到可靠的affinity关系;另一方面,由于affinity是MHSA的线性组合,上式又能够保证注意力矩阵中更好的特征交互。在得到可靠的affinity矩阵之后,我们通过随机游走算法对初始的伪标签进行修正:
通过随机游走算法,可以对初始伪标签中的高affinity区域进行激活,并抑制低affinity的错误激活区域,从而使得伪标签更好的贴合图像中的语义边界。
4、 PAR模块
如图3所示,伪affinity标签是根据伪标签生成的。然而,初始伪标签通常是粗糙的并且局部不一致,即具有相似low-level图像信息的相邻像素可能不具有相同的语义。为保证局部一致性,之前有工作采用Dense CRF来细化初始伪标签。然而,CRF在端到端框架中并不是一个有益的选择,因为它显著降低了训练效率。受PAMR的启发,它利用像素自适应卷积提取局部像素的RGB信息以对伪标签进行细化,我们结合 RGB 和空间信息来定义低级的pairwise affinity并构建我们的像素自适应细化模块(PAR)。首先,我们定义任意两个像素的RGB信息和位置信息的kernel分别为:
根据定义的位置和RGB信息kernel函数计算像素之间的low-level affinity值为:
与CRF中计算全局像素的low-level affinity不同,我们根据像素的8个邻居像素进行计算,该过程可以使用33的像素自适应卷积实现,从而能够高效的插入到端到端的训练框架中。同时为了扩大感受野,使用多个空洞卷积进行多个邻居像素信息的提取。得到像素之间的low-level affinity之后,通过多次迭代进行伪标签的修正:
5、网络训练损失
如图3所示,训练损失函数包括分类损失、分割损失和前文介绍的affinity损失。其中分类损失采用常见的多分类软间隔损失,分割损失采用常见的交叉熵损失:
03 实验结果
我们在弱监督语义分割领域常用的VOC 2012和COCO 2014数据集上对我们的方法进行了实现。在CNN中,分类层前的池化方法对CAM生成效果有显著的影响,我们实验了对transformer结构的合适池化方式,并且发现:和CNN中全局平均池化(GAP)效果更好不同,对于transformer结构,全局最大池化(GMP)能够得到更好的类别激活图。
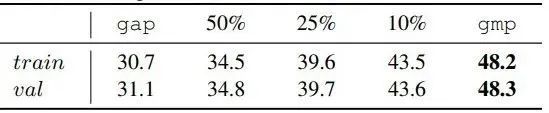
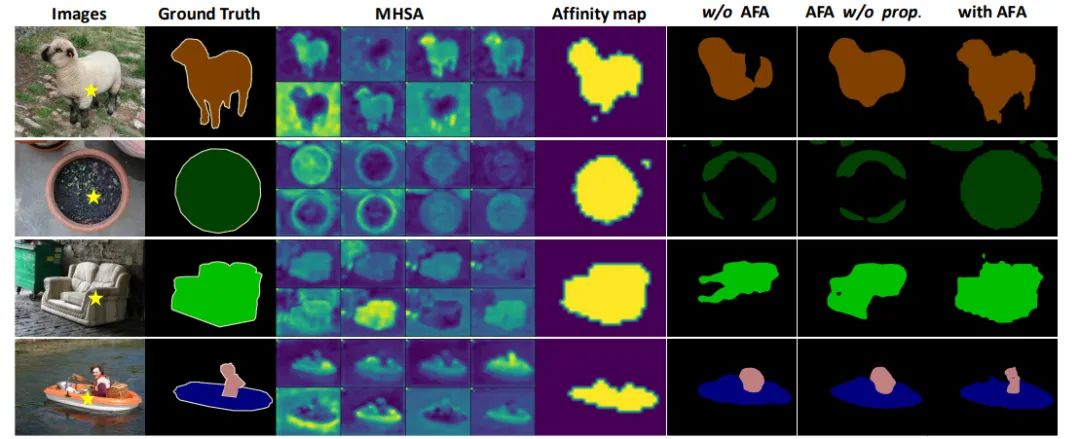
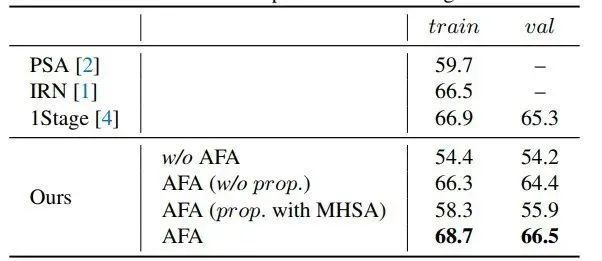
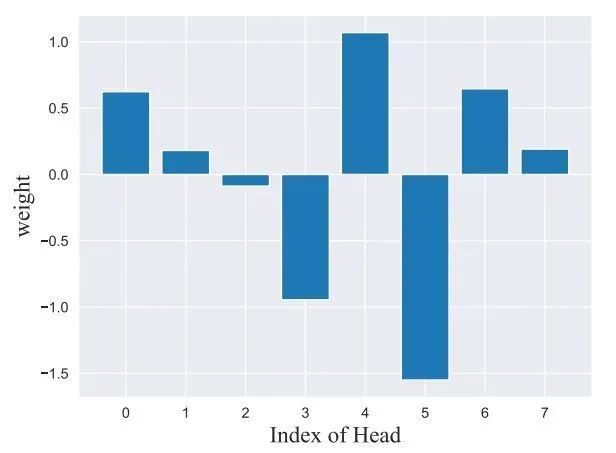
图4和表2中展示了AFA模块中的多头注意力和语义affinity可视化图,以及在不同设置下的伪标签的定量和定性结果。我们注意到AFA损失以及随后的随机游走传播过程都能够有效的提高伪标签的效果,以及直接使用MHSA作为affinity信息并不能带来效果的提升。下图中展示了AFA的affinity预测层不同head 的注意力的权重,说明不同head的attention的差别,也证明了将MHSA直接作为affinity信息并不是合理的做法。
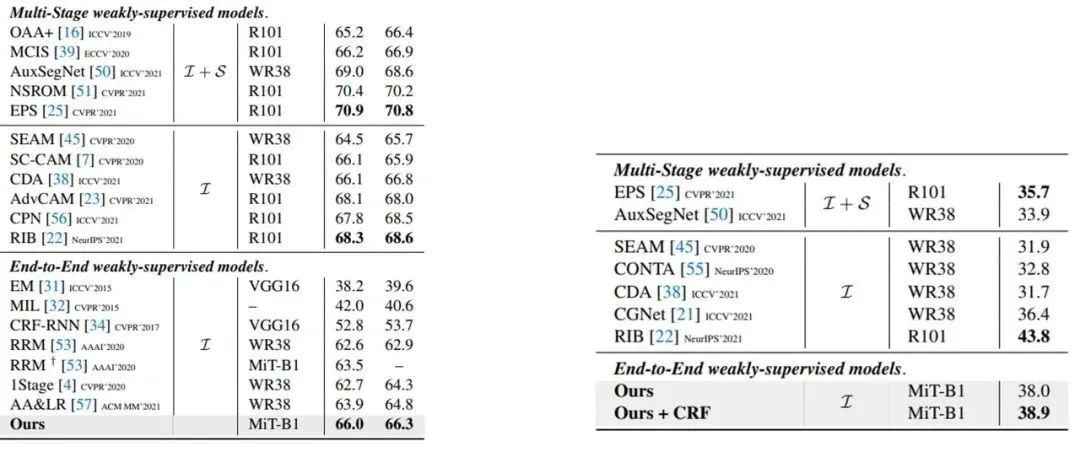
在VOC和COCO数据集上的实验都显示AFA超过了最近的端到端语义分割方法,并且同时超过了部分多阶段的方法以及一些引入了额外显著性监督的方法。
04 结论
本文中,我们探索了视觉transformer在弱监督语义分割任务上的合适做法,证实了transformer结构能够比CNN生成更好的伪标签。受自注意力图和像素的affinity关系的启发,我们提出了从注意力中学习语义affinity,从而同时对初始伪标签进行改善和监督注意力的训练保证更好的特征交互。我们设计了一个像素自适应细化模块,在不影响端到端训练效率的同时修正伪标签的局部细节信息。提出的方法在两个数据集上取得了当前最佳的效果。
参考文献
[1] Lixiang Ru, Yibing Zhan, Baosheng Yu and Bo Du, Learning Affinity from Attention: End-to-End Weakly-Supervised Semantic Segmentation with Transformers, CVPR 2022.
[2] Ahn, Jiwoon and Kwak, Suha, Learning Pixel-Level Semantic Affinity with Image-Level Supervision for Weakly Supervised Semantic Segmentation, CVPR 2018.
[3] Nikita Araslanov and Stefan Roth, Single-stage Semantic Segmentation from Image Labels, CVPR 2020.
[4] Bolei Zhou, Aditya Khosla, Agata Lapedriza, Aude Oliva, Antonio Torralba, Learning deep features for discriminative localization, CVPR 2016.
[5] Alexey Dosovitskiy, Lucas Beyer, Alexander Kolesnikov, Dirk Weissenborn, Xiaohua Zhai, Thomas Unterthiner, Mostafa Dehghani, Matthias Minderer, Georg Heigold, Sylvain Gelly, Jakob Uszkoreit, Neil Houlsby, An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale, ICLR 2021.
公众号后台回复“CVPR 2022”获取论文合集打包下载~

# CV技术社群邀请函 #

备注:姓名-学校/公司-研究方向-城市(如:小极-北大-目标检测-深圳)
即可申请加入极市目标检测/图像分割/工业检测/人脸/医学影像/3D/SLAM/自动驾驶/超分辨率/姿态估计/ReID/GAN/图像增强/OCR/视频理解等技术交流群
每月大咖直播分享、真实项目需求对接、求职内推、算法竞赛、干货资讯汇总、与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度等名校名企视觉开发者互动交流~
