
使用Python进行图像处理—图像分割的无监督学习
来源:深度学习与计算机视觉

import pandas as pd
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import colors
from skimage.color import rgb2gray, rgb2hsv, hsv2rgb
from skimage.io import imread, imshow
from sklearn.cluster import KMeans
plt.figure(num=None, figsize=(8, 6), dpi=80)
imshow(dog);

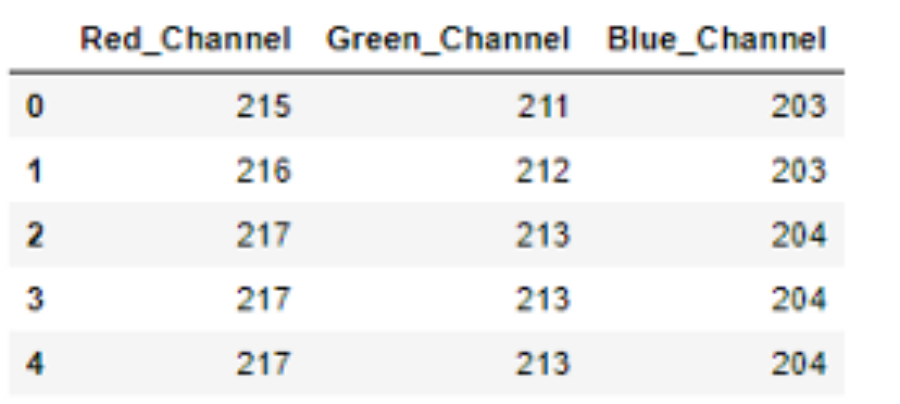
df = pd.DataFrame([image[:,:,0].flatten(),
image[:,:,1].flatten(),
image[:,:,2].flatten()]).T
df.columns = [‘Red_Channel’,’Green_Channel’,’Blue_Channel’]
return df
df_doggo = image_to_pandas(dog)
df_doggo.head(5)
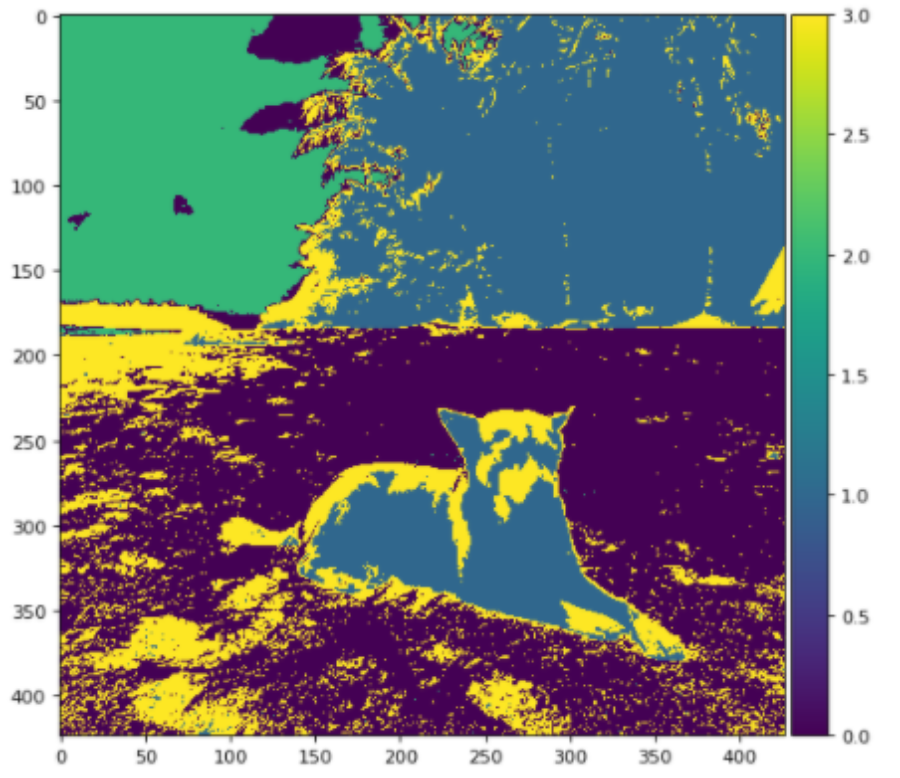
kmeans = KMeans(n_clusters= 4, random_state = 42).fit(df_doggo)
result = kmeans.labels_.reshape(dog.shape[0],dog.shape[1])
imshow(result, cmap='viridis')
plt.show()
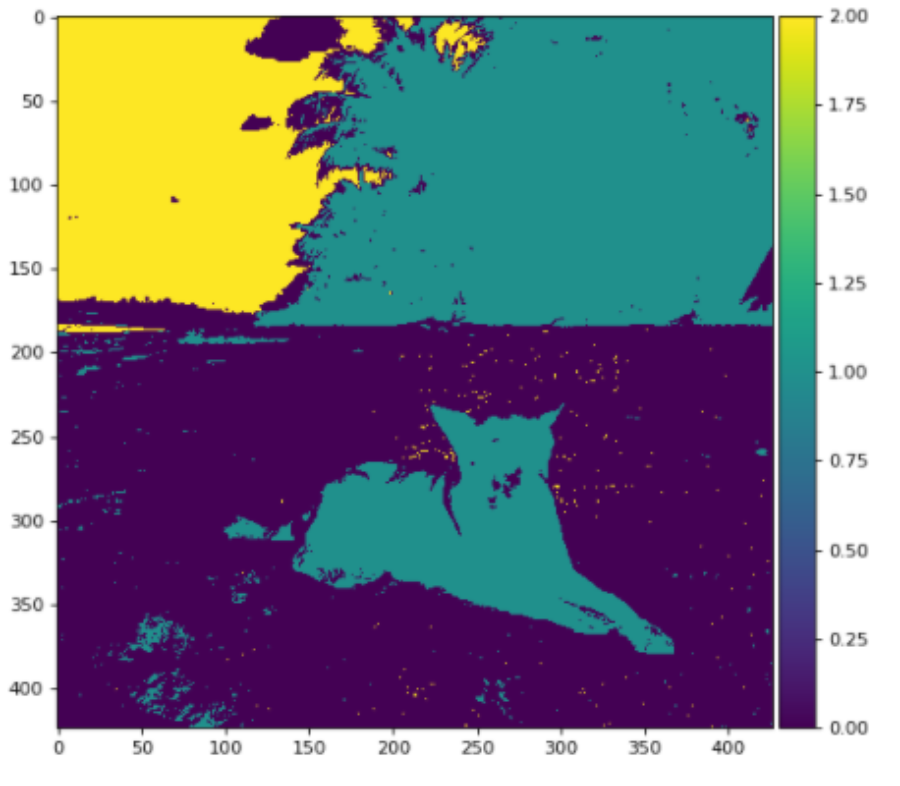
for n, ax in enumerate(axes.flatten()):
ax.imshow(result==[n], cmap='gray');
ax.set_axis_off()
fig.tight_layout()

for n, ax in enumerate(axes.flatten()):
dog = imread('beach_doggo.png')
dog[:, :, 0] = dog[:, :, 0]*(result==[n])
dog[:, :, 1] = dog[:, :, 1]*(result==[n])
dog[:, :, 2] = dog[:, :, 2]*(result==[n])
ax.imshow(dog);
ax.set_axis_off()
fig.tight_layout()

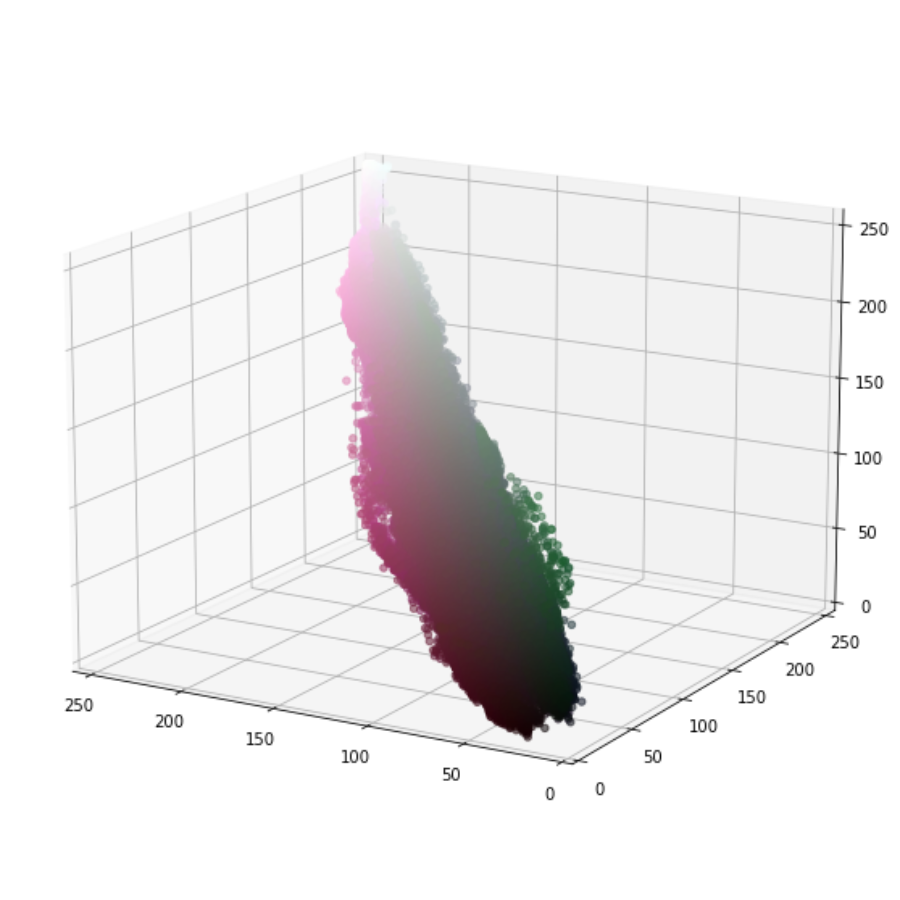
x_3d = df['Red_Channel']
y_3d = df['Green_Channel']
z_3d = df['Blue_Channel']
color_list = list(zip(df['Red_Channel'].to_list(),
df['Blue_Channel'].to_list(),
df['Green_Channel'].to_list()))
norm = colors.Normalize(vmin=0,vmax=1.)
norm.autoscale(color_list)
p_color = norm(color_list).tolist()
fig = plt.figure(figsize=(12,10))
ax_3d = plt.axes(projection='3d')
ax_3d.scatter3D(xs = x_3d, ys = y_3d, zs = z_3d,
c = p_color, alpha = 0.55);
ax_3d.set_xlim3d(0, x_3d.max())
ax_3d.set_ylim3d(0, y_3d.max())
ax_3d.set_zlim3d(0, z_3d.max())
ax_3d.invert_zaxis()
ax_3d.view_init(-165, 60)
pixel_plotter(df_doggo)
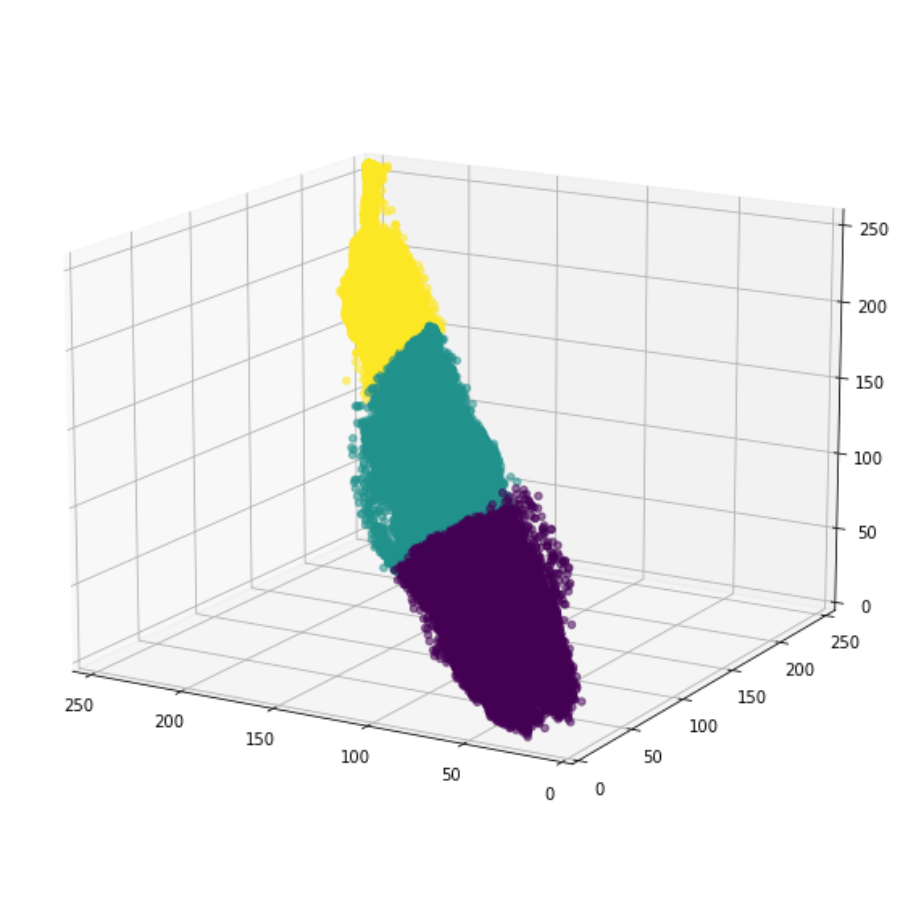
def pixel_plotter_clusters(df):
x_3d = df['Red_Channel']
y_3d = df['Green_Channel']
z_3d = df['Blue_Channel']
fig = plt.figure(figsize=(12,10))
ax_3d = plt.axes(projection='3d')
ax_3d.scatter3D(xs = x_3d, ys = y_3d, zs = z_3d,
c = df['cluster'], alpha = 0.55);
ax_3d.set_xlim3d(0, x_3d.max())
ax_3d.set_ylim3d(0, y_3d.max())
ax_3d.set_zlim3d(0, z_3d.max())
ax_3d.invert_zaxis()
ax_3d.view_init(-165, 60)
pixel_plotter_clusters(df_doggo)
结论

评论