
经典的图像语义分割模型
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
来源:人工智能感知信息处理算法研究院
经典的基于 CNN 的图像语义分割模型有 FCN、SegNet、U-Net、PSPNet 和 DeepLab,主要针对 FCN、SegNet 和 DeepLab 三个经典模型进行简要介绍。
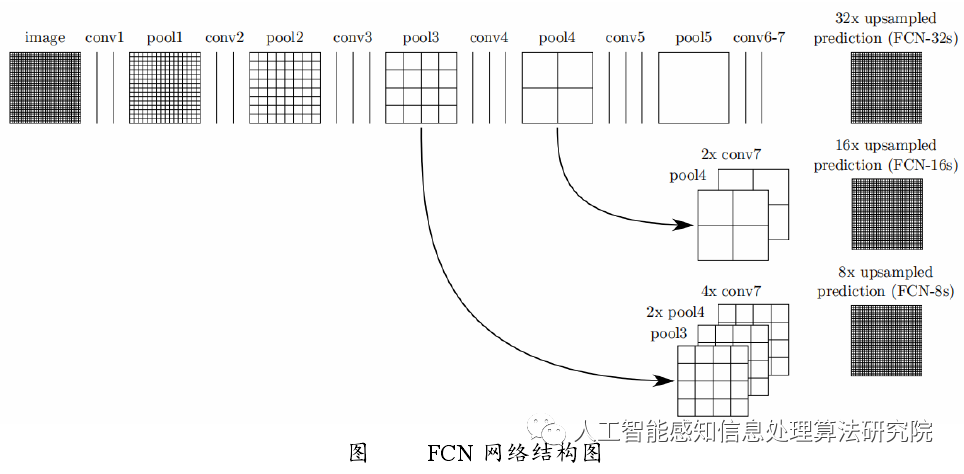
FCN 之所以称为全卷积神经网络模型,是因为 FCN 去掉了图像分类网络中的全连接层,全连接层得到的是整张图像的分类结果,而图像语义分割是实现对每一个像素点的分类,因此去掉全连接层,且去掉全连接层后可使模型适应不同尺寸图像的输入,由于最后的特征图在提取特征过程中会丢失图像位置信息,即得到的特征图像素小于原图像,基于该问题,FCN 利用反卷积(Deconvolution)的方法对特征图进行上采样操作,将其恢复到原始图像尺寸,同时采用跳跃(Skip)结构对不同深度层的特征图进行融合,然后利用监督函数不断进行反向传播,调整学习参数,最后得到最优的参数模型。FCN 的网络结构图如下:
SegNet 是在 FCN 的基础上进行的改进,同时引入了预训练模型 VGG-16 提取图像特征,SegNet 不同于 FCN,SegNet 采用的是对称的编码器-解码器结构,这种结构主要分为编码器和解码器两个部分,编码器采用 VGG-16 模型对图像进行特征提取,如上图所示,每个编码器包含多层卷积操作、BN、ReLU 以及池化层,其中卷积操作采用的是 same padding 方式,即图像大小不会发生改变,而池化层采用的是步长为 2 的2 × 2的最大池化,会降低图像分辨率,如图中所示,每一层编码器得到的特征图除了传入下一层编码器进行特征提取外,同时要传入对应层的解码器进行上采样,如此一来,有多少层编码器就会对应地有多少层解码器,最终解码器得到的特征图会输入到 SoftMax 分类器中,继而得到最后的预测图。

DeepLab 模型是图像语义分割领域中非常经典的一个模型,包括 DeepLab V1、V2和 V3 三个版本,由于 DeepLab V3 是在 DeepLab V2 的基础上进行的改进,因此,本小节只简单介绍 DeepLab V1 和 DeepLab V2。
DeepLab V1 借鉴了 FCN 的核心思想,以 VGG-16 作为主干网络,去掉了最后的全连接层,同时也剪掉了两个池化层,池化层是的主要作用是快速地扩大感受野,最大程度地利用上下文信息,但池化层的缺点是会导致图像尺寸缩小,丢失空间位置信息,影响上采样过程中信息的恢复。为了解决这个问题,DeepLab V1 引入空洞卷积,总结来说就是空洞卷积可以在保证参数不增加的前提下扩大感受野,弥补了剪掉池化层导致的感受野变小的问题,同时 DeepLab V1 也引入了条件随机场来增加分割精准性。
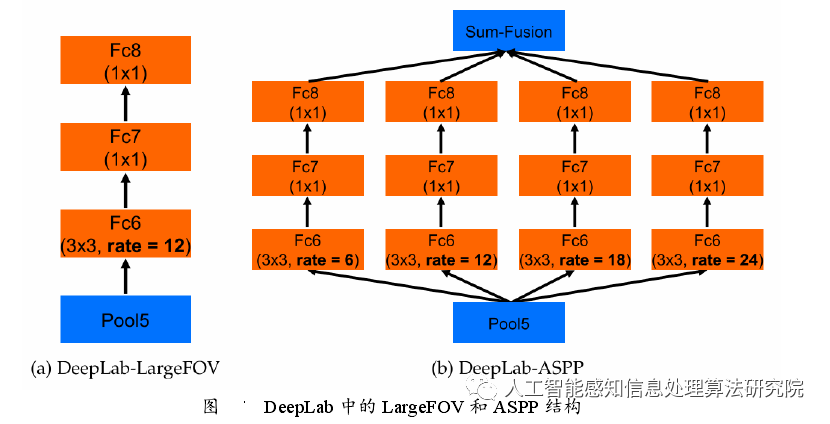
由于 ResNet 相对于 VGG-16 来说具有更好的表现力,因此 DeepLab V2 利用ResNet101 预训练模型替换了 DeepLab V1 中的 VGG-16 模型,同时提出了空洞空间金字塔池化(简称 ASPP),并将该结构融入到了 ResNet101 中,ASPP 的每个分支处设置了不同的空洞率,可以提取到一张图像中大小不同的同种目标。DeepLab V1 和 DeepLabV2 的主要模块分别是 Deep Lab-LargeFOV 和 DeepLab-ASPP,如下图所示。


—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!
—THE END—
评论