
三种集成学习算法原理及核心公式推导
导读
本文主要介绍3种集成学习算法的原理及重要公式推导部分,包括随机森林(Random Forest)、自适应提升(AdaBoost)、梯度提升(Gradient Boosting)。仅对重点理论和公式推导环节做以简要介绍。
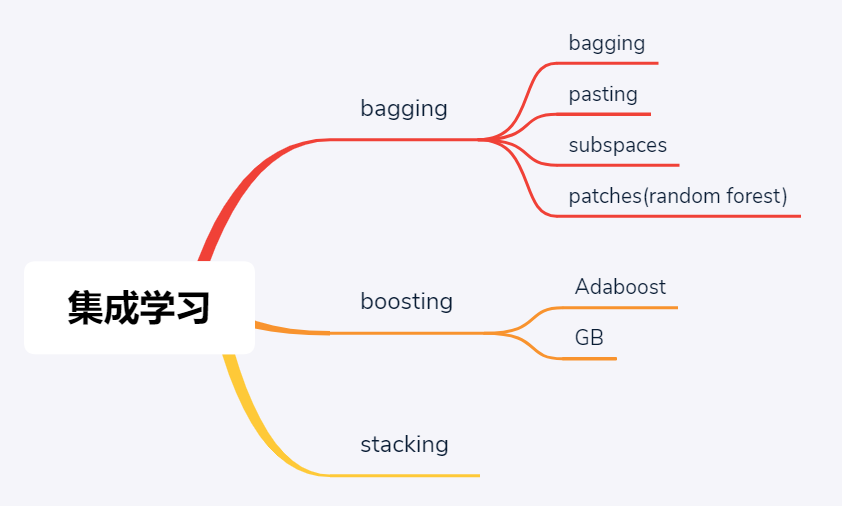
集成学习3大流派
在经典机器学习场景下,当单个学习模型性能不足以有效满足算法精度时,人们开始向集成学习模型发力——其思想和出发点很直观,就是三个臭皮匠赛过诸葛亮。进一步地,根据这三个臭皮匠在致力于赛过诸葛亮期间的协作模式不同,集成学习又细分为bagging和boosting两大学派,其中前者是并行模式,意味着三个臭皮匠各搞各的然后将最后结果进行融合以期带来提升,这里bagging是一个合成词汇,本意为booststrap aggregating;后者是串行模型,先让一个臭皮匠去探探底,根据反馈结果再派第二个、第三个,颇有些车轮战的味道。进一步的,车轮战还可以根据具体战术落脚点的不同,而分为Adaboost和GB,其中AdaBoost算法中各个臭皮匠的迭代重点在于不断弥补自己的过失/错误的地方,而GB算法中各个臭皮匠的迭代重点在于不断弥补自己与诸葛亮/理想型的差距,或者说残差。
当然,除了bagging和boosting两大流派之外,其实集成学习还有第三大流派——stacking,从其名字可以看出端倪是有些堆栈的意味,其实质就是将前一轮学习之后的输出/标签组织变换后作为下一轮学习的输入/特征,然后再次训练。其实就是深度学习那一套……
随机森林是典型的bagging流派集成学习算法,个人非常喜欢这个算法的名字:森林二字可以窥探出这个算法是源于决策树,当以多棵树作为弱学习器,那么组成的集成学习算法自然叫做森林最合适;而随机二字则形象的体现其在构建每棵决策树时,实际上是采取了随机采样的方式来确保各弱学习器结果的多样性。至于为什么要保证多样性,稍后的公式推导可以说明这一点。
这里,既然说随机森林是bagging流派的典型代表,那么言外之意就是还存在其他bagging算法,实际也正是如此。广义来讲,bagging流派集成学习算法可分为4类,主要差别主要源于采样方式的不同:
仅对样本维度(体现为行采样)进行采样,且采样是有放回的,意味着每个弱学习器的K个采样样本中可能存在重复的样本,此时对应bagging算法,这里bagging=bootstrap aggregating。发现,这个具体算法的名字与bagging流派的名字重合,这并不意外,因为这是bagging中一种经典的采样方式,因而以其作为流派的名字。当然,bagging既是一种算法也是流派名,那就要看是狭义还是广义的bagging来加以区分了
仅对样本维度采样,但采样是无放回的,意味着对于每个弱学习器的K个采样样本是完全不同的,由于相当于是每执行一次采样,则该样本就被舍弃掉(pass),所以此时算法叫做pasting
前两者的随机性均来源于样本维度的随机采样,也就是行方向上,那么对于列方向上进行随机采样是否也可以呢?比如说每个弱学习器都选用所有的样本参与训练,但各学习器选取参与训练的特征是不一致的,训练出的算法自然也是具有随机性的,可以满足集成的要求。此时,对应算法叫做subspaces,中文译作子空间,具体说是特征维度的子空间,名字还是比较传神的
发现,既有样本维度的随机,也有特征维度的随机,那么自然想到有没有兼顾二者的随机呢,也就是说每个弱学习器既执行行采样、也有列采样,得到的弱学习器其算法随机性应该更强。当然,这种算法被称作是patches,比如前文已经提到的随机森林就属于这种。实际上,随机森林才是最为广泛使用的bagging流派集成学习算法
发散一下,其实bagging算法无非就是区分到底是行采样、列采样还是行列采样,那为什么会出来4种呢?原来是行采样在采样执行过程中又细分了是否有放回。那既然行采样可以区分是否有放回,列采样是否也可区分一下衍生出两种具体算法呢?实际上是不可以的,因为特征的有放回意味着特征重复,在机器学习训练过程中重复的特征或者说复制特征参与训练不能带来学习效果的改变;但样本的重复或者说复制则能带来学习效果的差异,因为这直接带来算法训练样本的类别平衡性,自然影响训练结果。
bagging算法原理非常简单易懂,算法出发点也非常朴素,其中涉及到的公式推导也不多,主要需要理解以下三个要点:
有放回采样中,预计有36.8%的样本不会被用于训练,也就意味着这些样本可以天然的作为测试集用于评估集成学习模型效果。36.8%是如何而来呢?设样本数量为N,则对任意样本而言在1次采样中不被抽中的概率为 1 - 1/N,在N次采样中均未被抽中的概率则为
bagging流派的各种算法中,一直在强调每个弱学习器训练效果之间的随机性,或者说差异性,那么为什么要保证这种差异性呢?直观来看,把集成学习比作是一次考试,A同学在参考了周边的BCD3名同学答案的基础上做判断,如果BCD3人的答案都是一样的,正确的都正确,错误的都错误,那么A同学的在综合3人答案之后丝毫不会对最终结果带来任何提升,仍然是BCD三人的正确率。而只有当3人擅长的考点不一样得出的答案也不尽相同时,A综合之后才可能带来提升。具体到其中一道题,用数学语言描述就是:设BCD三人答对的概率分别为Pb、Pc、Pd,如果三人答案的正确与否是独立事件,那么A本着少数服从多数的原则,得到正确答案的概率为PbPc(1-Pd) + (1-Pb)PcPd + Pb(1-Pc)Pd + PbPcPd;反之,如果三人答案的正确与否是相关联的事件,即同时正确或错误,那么A的最终正确率其实是不变的。所以,bagging流派要求集成学习各弱学习器之间要求算法尽可能是随机的,同时也有准确率的最低要求,即不能低于50%,否则会对集成效果带来负作用
bagging流派将带来算法的低方差,但不会降低偏差。衡量机器学习模型效果时,往往需要考虑偏差和方差两方面因素,偏差意味着模型训练效果距离理想目标还有很大差距,常常效果很差;方差意味着模型训练效果时好时坏,虽然有时候效果很好,但不够稳定,二者的形象描述示意如下图所示。那么,当我们说bagging集成学习相较于单个弱学习器效果有所提升,具体是指哪方面有所提升呢,换言之是降低了偏差还是方差呢?答案是偏差不变,方差降低。这可以由以下两个公式意会的表达:
当然,以上两个公式也仅可意会的表达集成学习效果的提升,而不能具体刻画。实际中的bagging算法当然是会带来偏差的降低,只是统计意义下的均值与弱学习器效果相当,具体如何降低偏差那就需要具体问题具体调参了!
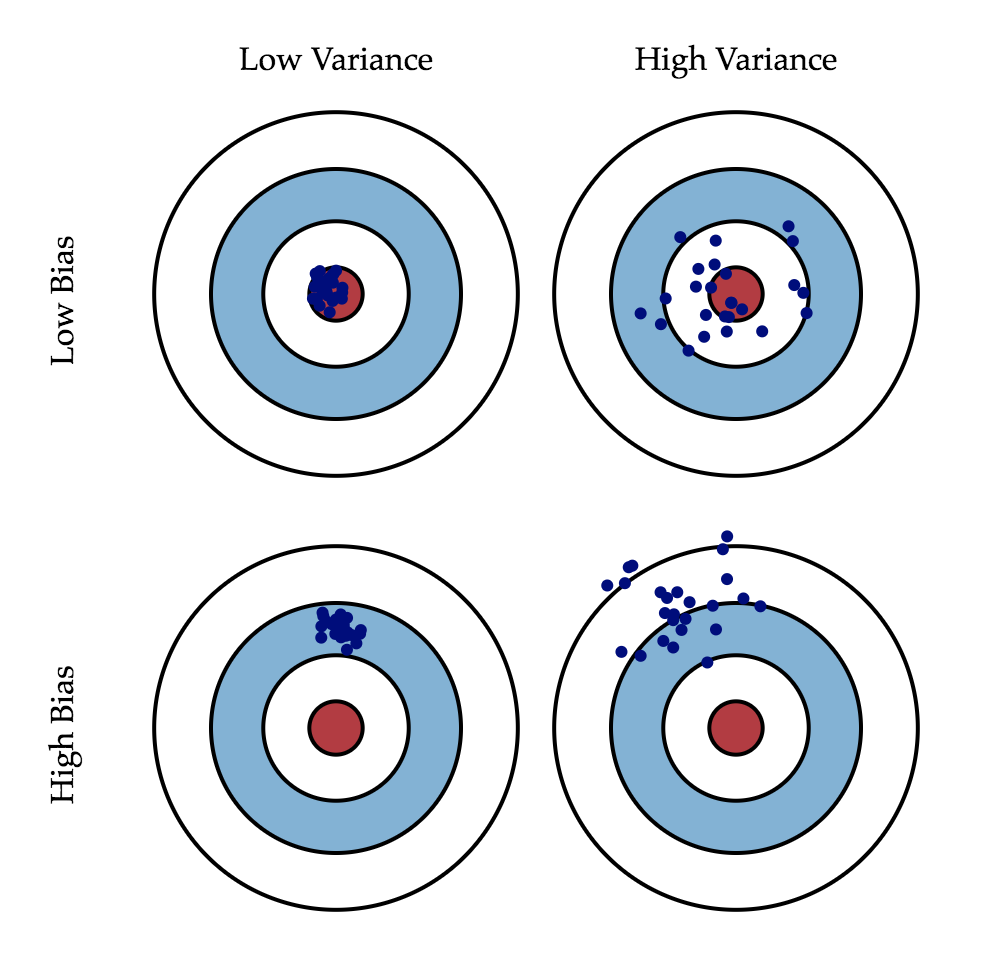
理解机器学习方差和偏差
图片源于《Understanding the Bias-Variance Tradeoff 2012》一文
原文链接:http://scott.fortmann-roe.com/docs/BiasVariance.html
此外,bagging流派由于是并行训练多个模型,而后综合各个弱学习器的效果进行综合决策,那么综合决策的方式其实也是一个值得探讨的问题。简言之,就是hard voting和soft voting两种方式,以二分类问题为例,前者是直接统计所有弱学习器的结果,然后取其中结果最多的那一类作为最终结果;而后者则不是直接统计结果,而是统计各弱学习器的分类概率,并分别计算所有弱学习器中两类的概率之和,以概率之和较大者作为最终结果。具体不再赘述。
与bagging流派集成学习思想不同,boosting流派侧重于后人站在前人的肩膀上看问题,Adaboost和GB概莫能外。当然,虽然理论上最后一个弱学习器在综合了所有前人的经验基础上可能会具有最好的性能,但Adaboost也不是简单的以最后的弱学习器结果为准,而是仍然加权考虑所有弱学习器的结果。
前文提到,Adaboost算法在吸取前一个弱学习器训练效果的基础上,重点关注错误的样本从而针对性的执行后续训练过程,具体说就是加大前一轮训练错的样本权重。
以二分类为例,Adaboost算法核心算法原理(公式推导):
损失函数:指数函数,当训练结果与真实标签一致时(乘积为正)损失较小,不一致时(乘积为负)损失较大
m轮训练后的集成学习模型:前m个弱学习器的加权求和
m轮训练后的模型损失
其中em表示第m轮弱学习器的模型训练错误率,根据错误样本的权重之和与总样本的权重之和比值得出。当然在样本权重和进行归一化的基础上,分母为1。
然后分析每轮训练弱学习器时的样本权重迭代方式。再看损失函数,每个样本的损失可看做是两部分的乘积形式,其中前一部分与第m轮训练的弱学习器Gm(X)无关,而后一轮与其直接相关,因而可将前一部分看做是样本加权系数——这也正是不断调整每一轮训练模型的样本权重的根源所在。记第m轮训练弱学习器的第i个样本的权重系数为:
则可进一步发现权重的更新策略为:
也就是说,下一轮的样本权重由前一轮样本权重和前一轮的弱学习器训练结果有关,进一步地,当前一轮训练结果与真实标签一致时样本权重前的系数为小于1的值,体现为样本权重降低;否则权重增大。当然,在每轮更新后还需对样本权重加和进行归一化处理。
与Adaboost算法类似,GB(梯度提升)集成学习算法也是基于多个弱学习器的训练效果的加权进行最终判决,且每轮训练也基于前一轮训练效果进行针对性的更新迭代。但与Adaboost聚焦于前一轮训练错误的样本机制不同,GB聚焦于前一轮训练后的残差,相当于是通过集成学习来了个算法接力,以使得最终学习效果不断逼近真实水平。
对比fm(X)的梯度和其迭代公式,可知第m轮训练的弱学习器实际上即为拟合当前残差的弱学习器,这也正是GB的核心思想。实际上,GB也被称作是函数空间的梯度下降法。
这是GB集成学习算法的出发点,也是理解不断拟合残差的核心。后续相关公式推导不再给出。
相关阅读: