
3种常见的集成学习决策树算法及原理

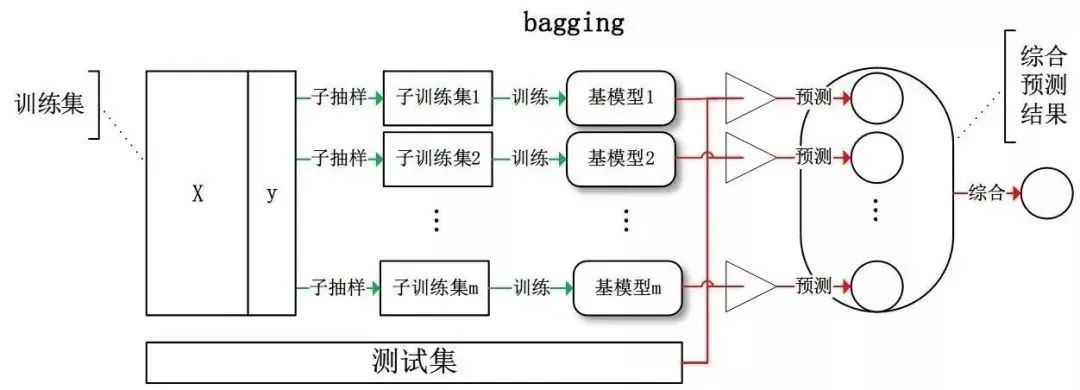
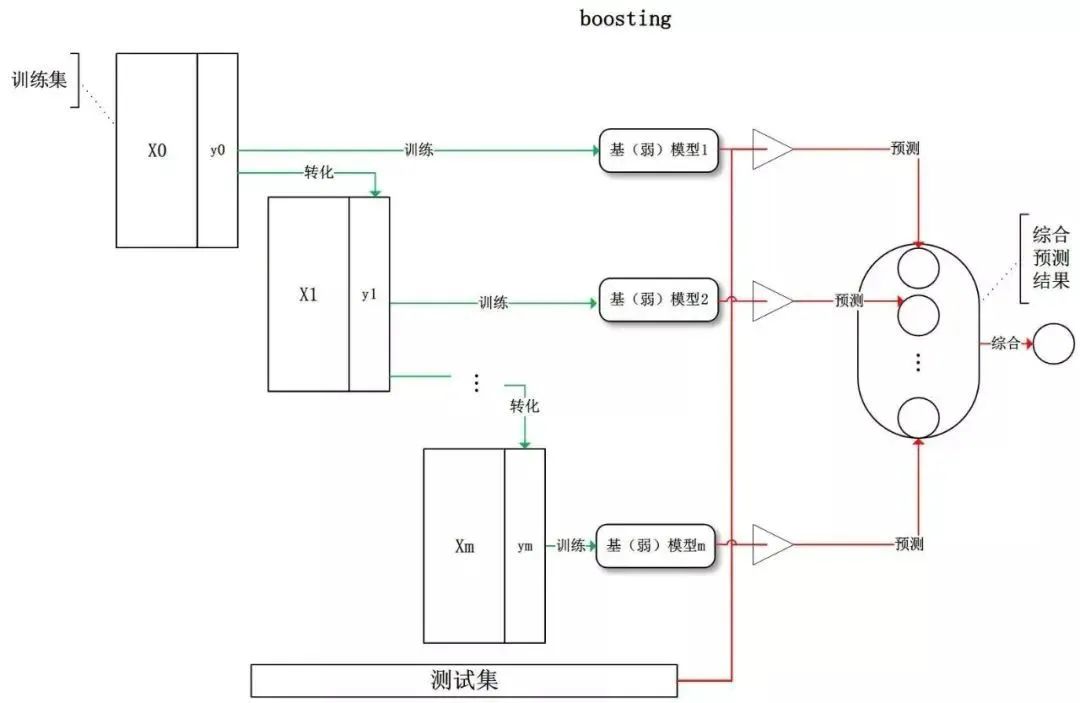
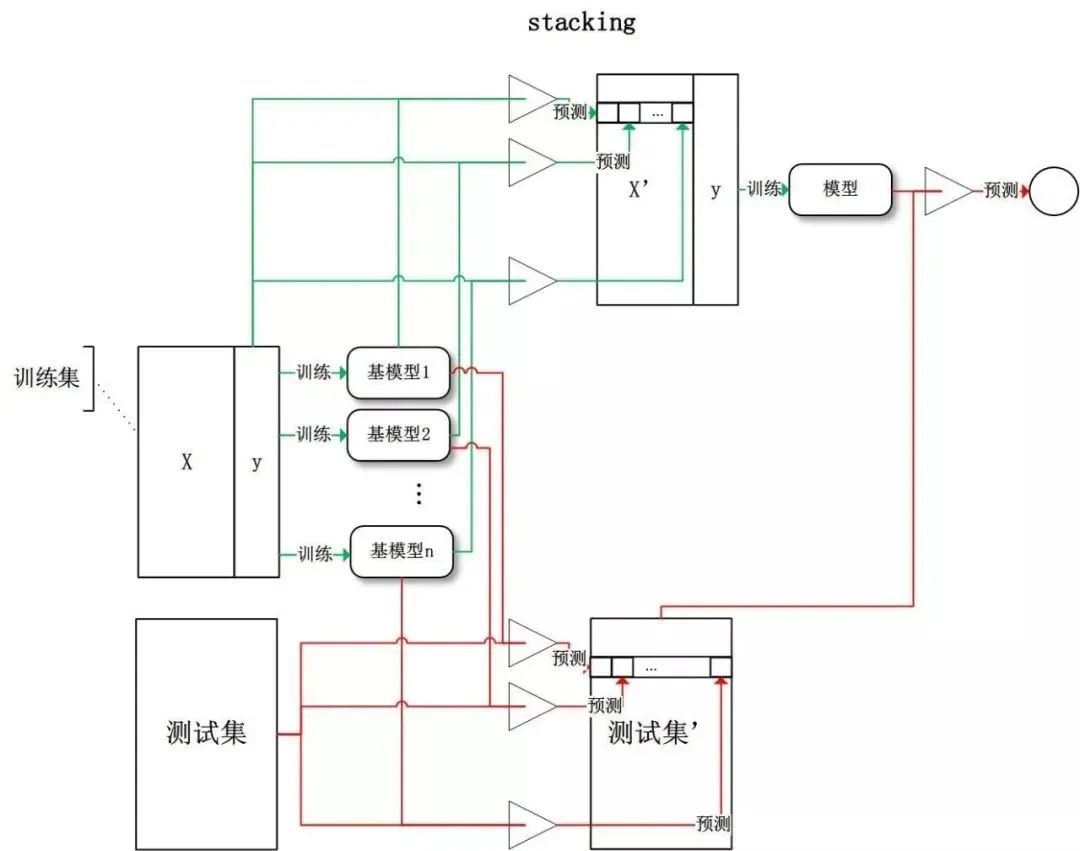
集成学习

那么,为什么集成学习会好于单个学习器呢?原因可能有三:
训练样本可能无法选择出最好的单个学习器,由于没法选择出最好的学习器,所以干脆结合起来一起用;
假设能找到最好的学习器,但由于算法运算的限制无法找到最优解,只能找到次优解,采用集成学习可以弥补算法的不足;
可能算法无法得到最优解,而集成学习能够得到近似解。比如说最优解是一条对角线,而单个决策树得到的结果只能是平行于坐标轴的,但是集成学习可以去拟合这条对角线。
偏差与方差
上节介绍了集成学习的基本概念,这节我们主要介绍下如何从偏差和方差的角度来理解集成学习。
2.1 集成学习的偏差与方差
偏差(Bias)描述的是预测值和真实值之差;方差(Variance)描述的是预测值作为随机变量的离散程度。放一场很经典的图:
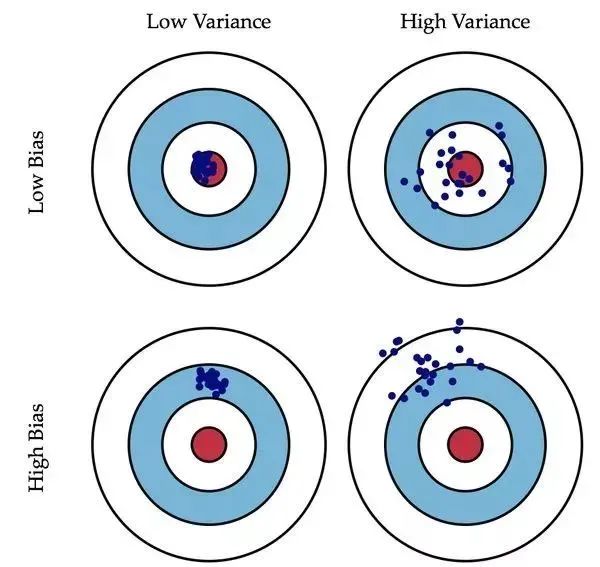
偏差:描述样本拟合出的模型的预测结果的期望与样本真实结果的差距,要想偏差表现的好,就需要复杂化模型,增加模型的参数,但这样容易过拟合,过拟合对应上图的 High Variance,点会很分散。低偏差对应的点都打在靶心附近,所以喵的很准,但不一定很稳; 方差:描述样本上训练出来的模型在测试集上的表现,要想方差表现的好,需要简化模型,减少模型的复杂度,但这样容易欠拟合,欠拟合对应上图 High Bias,点偏离中心。低方差对应就是点都打的很集中,但不一定是靶心附近,手很稳,但不一定瞄的准。
整体模型的期望等于基模型的期望,这也就意味着整体模型的偏差和基模型的偏差近似。
整体模型的方差小于等于基模型的方差,当且仅当相关性为 1 时取等号,随着基模型数量增多,整体模型的方差减少,从而防止过拟合的能力增强,模型的准确度得到提高。但是,模型的准确度一定会无限逼近于 1 吗?并不一定,当基模型数增加到一定程度时,方差公式第一项的改变对整体方差的作用很小,防止过拟合的能力达到极限,这便是准确度的极限了。
整体模型的方差等于基模型的方差,如果基模型不是弱模型,其方差相对较大,这将导致整体模型的方差很大,即无法达到防止过拟合的效果。因此,Boosting 框架中的基模型必须为弱模型。
此外 Boosting 框架中采用基于贪心策略的前向加法,整体模型的期望由基模型的期望累加而成,所以随着基模型数的增多,整体模型的期望值增加,整体模型的准确度提高。
我们可以使用模型的偏差和方差来近似描述模型的准确度;
对于 Bagging 来说,整体模型的偏差与基模型近似,而随着模型的增加可以降低整体模型的方差,故其基模型需要为强模型;
对于 Boosting 来说,整体模型的方差近似等于基模型的方差,而整体模型的偏差由基模型累加而成,故基模型需要为弱模型。
Random Forest
随机选择样本(放回抽样); 随机选择特征; 构建决策树; 随机森林投票(平均)。
在数据集上表现良好,相对于其他算法有较大的优势 易于并行化,在大数据集上有很大的优势; 能够处理高维度数据,不用做特征选择。
AdaBoost
初始化训练样本的权值分布,每个样本具有相同权重; 训练弱分类器,如果样本分类正确,则在构造下一个训练集中,它的权值就会被降低;反之提高。用更新过的样本集去训练下一个分类器; 将所有弱分类组合成强分类器,各个弱分类器的训练过程结束后,加大分类误差率小的弱分类器的权重,降低分类误差率大的弱分类器的权重。
分类精度高; 可以用各种回归分类模型来构建弱学习器,非常灵活; 不容易发生过拟合。
对异常点敏感,异常点会获得较高权重。
GBDT

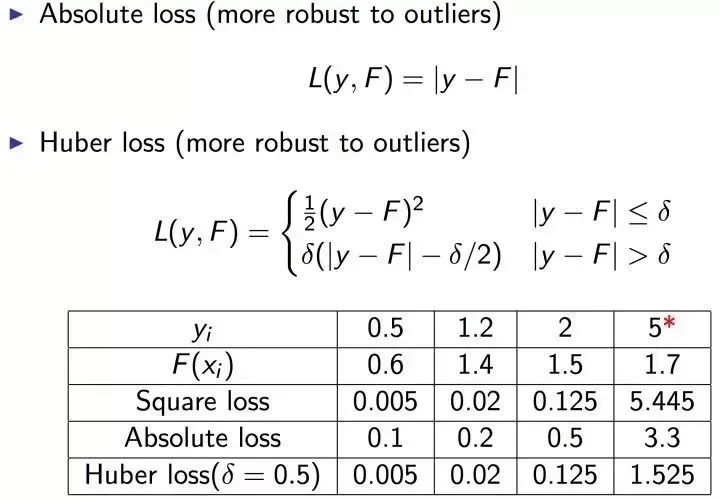
可以自动进行特征组合,拟合非线性数据; 可以灵活处理各种类型的数据。
对异常点敏感。
都是 Boosting 家族成员,使用弱分类器; 都使用前向分布算法;
迭代思路不同:Adaboost 是通过提升错分数据点的权重来弥补模型的不足(利用错分样本),而 GBDT 是通过算梯度来弥补模型的不足(利用残差); 损失函数不同:AdaBoost 采用的是指数损失,GBDT 使用的是绝对损失或者 Huber 损失函数;