
通俗讲解集成学习算法!
作者:黄星源,Datawhale优秀学习者
本文以图文的形式对模型算法中的集成学习,以及对集中学习在深度学习中的应用进行了详细解读。
数据及背景
集成学习
选定样本(包含正样本和负样本),将所有样本分成训练样本和测试样本两部分。 在训练样本上执行分类器算法,生成分类模型。 在测试样本上执行分类模型,生成预测结果。 根据预测结果,计算必要的评估指标,评估分类模型的性能。
构造这个分类器不需要任何领域的知识,也不需要任何的参数设置。因此它特别适合于探测式的知识发现。此外,这个分类器还可以处理高维数据,而且采用的是类似于树这种形式,也特别直观和便于理解。因此,决策树是许多商业规则归纳系统的基础。
2. 朴素贝叶斯分类器
素贝叶斯分类器是假设数据样本特征完全独立,以贝叶斯定理为基础的简单概率分类器。
3. AdaBoost算法
AdaBoost算法的自适应在于前一个分类器产生的错误分类样本会被用来训练下一个分类器,从而提升分类准确率,但是对于噪声样本和异常样本比较敏感。
4. 支持向量机
支持向量机是用过构建一个或者多个高维的超平面来将样本数据进行划分,超平面即为样本之间的分类边界。
5. K近邻算法
基于k近邻的K个样本作为分析从而简化计算提升效率,K近邻算法分类器是基于距离计算的分类器。
集成学习有许多集成模型,例如自助法、自助聚合(Bagging)、随机森林、提升法(Boosting)、 堆叠法(stacking) 以及许多其它的基础集成学习模型。
我们可以用三种主要的旨在组合弱学习器的元算法:
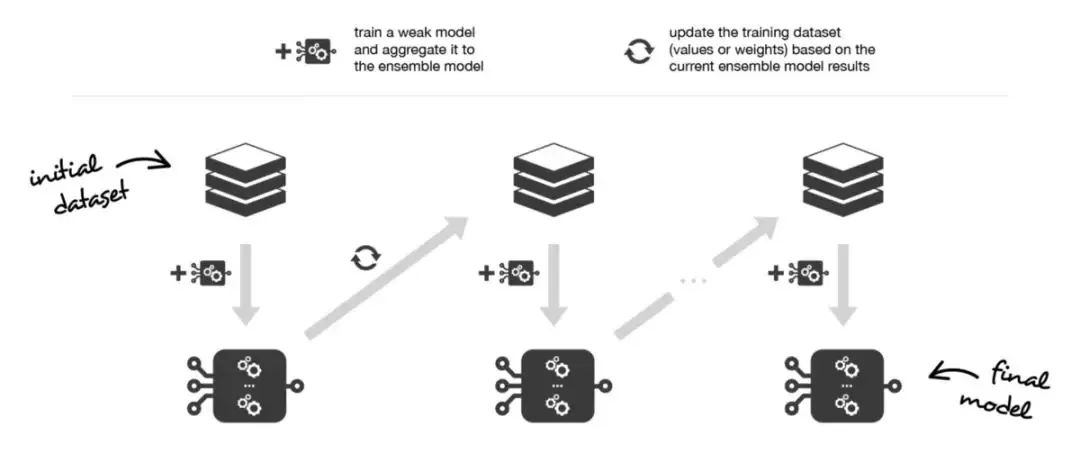
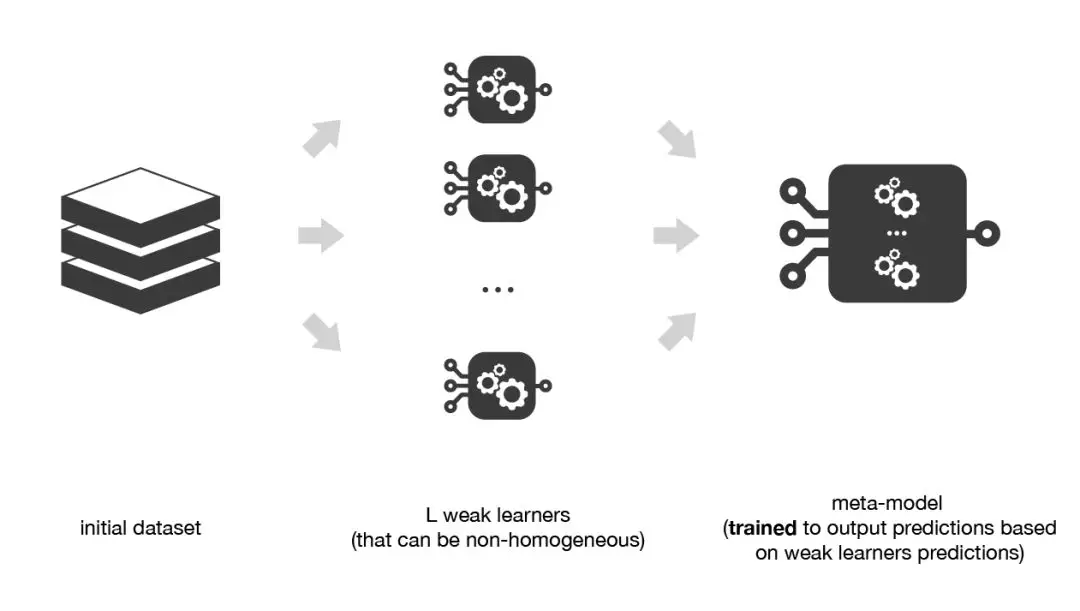
自助聚合(Bagging),该方法通常考虑的是同质弱学习器,相互独立地并行学习这些弱学习器,并按照某种确定性的平均过程将它们组合起来。 提升法(Boosting),该方法通常考虑的也是同质弱学习器。它以一种高度自适应的方法顺序地学习这些弱学习器(每个基础模型都依赖于前面的模型),并按照某种确定性的策略将它们组合起来。 堆叠法(Stacking),该方法通常考虑的是异质弱学习器,并行地学习它们,并通过训练一个 元模型 将它们组合起来,根据不同弱模型的预测结果输出一个最终的预测结果。
非常粗略地说,我们可以说Bagging的重点在于获得一个方差比其组成部分更小的集成模型,而Boosting和Stacking则将主要生成偏置比其组成部分更低的强模型(即使方差也可以被减小)。
1. 自助聚合(Bagging)
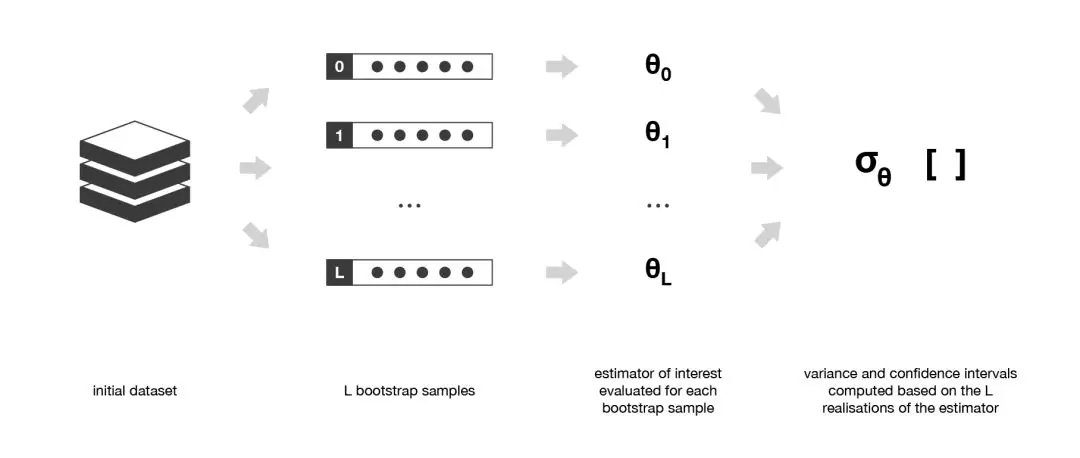
在并行化的方法 中,我们单独拟合不同的学习器,因此可以同时训练它们。最著名的方法是自助聚合(Bagging),它的目标是生成比单个模型更棒的集成模型。Bagging的方法实现。
自助法:这种统计技术先随机抽取出作为替代的 B 个观测值,然后根据一个规模为 N 的初始数据集生成大小为 B 的样本(称为自助样本)。
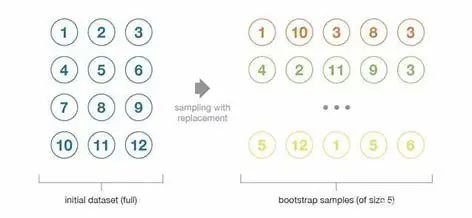
初始数据集的大小N应该足够大,以捕获底层分布的大部分复杂性。这样,从数据集中抽样就是从真实分布中抽样的良好近似(代表性)。 与自助样本的大小B相比,数据集的规模N应该足够大,这样样本之间就不会有太大的相关性(独立性)。注意,接下来我可能还会提到自助样本的这些特性(代表性和独立性),但读者应该始终牢记:这只是一种近似。
在大多数情况下,相较于实际可用的数据量来说,考虑真正独立的样本所需要的数据量可能太大了。然而,我们可以使用自助法生成一些自助样本,它们可被视为最具代表性以及最具独立性(几乎是独立同分布的样本)的样本。这些自助样本使我们可以通过估计每个样本的值,近似得到估计量的方差。
2. 提升法(Boosting)
简而言之,这两种元算法在顺序化的过程中创建和聚合弱学习器的方式存在差异。自适应提升算法会更新附加给每个训练数据集中观测数据的权重,而梯度提升算法则会更新这些观测数据的值。这里产生差异的主要原因是:两种算法解决优化问题(寻找最佳模型——弱学习器的加权和)的方式不同。
在自适应adaboost中,我们将集成模型定义为L个弱学习器的加权和:
另外,我们将弱学习器逐个添加到当前的集成模型中,在每次迭代中寻找可能的最佳组合(系数、弱学习器)。换句话说,我们循环地将 定义如下:
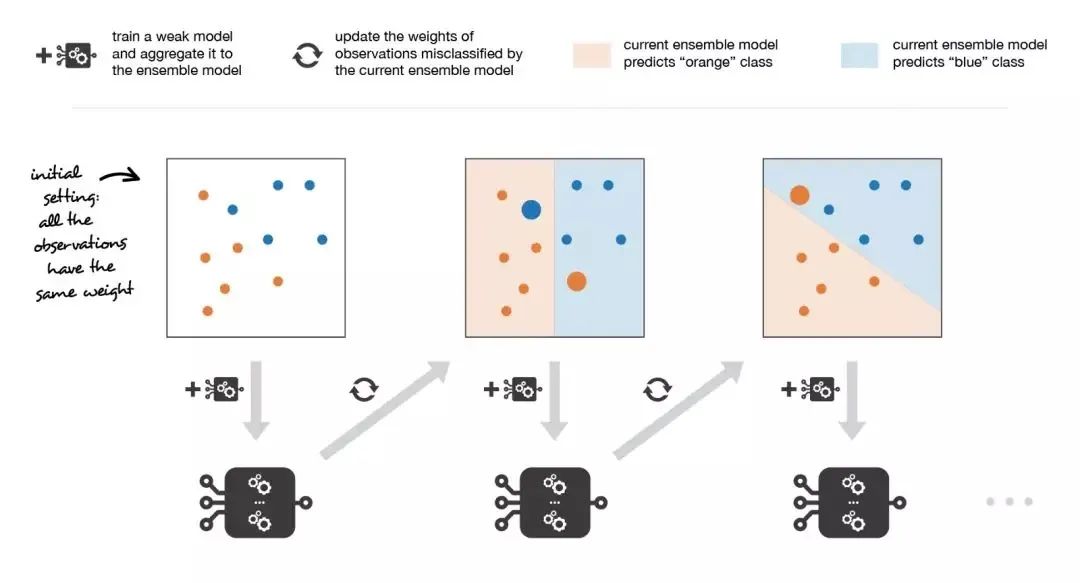
因此,假设我们面对的是一个二分类问题:数据集中有N个观测数据,我们想在给定一组弱模型的情况下使用adaboost算法。在算法的起始阶段(序列中的第一个模型),所有的观测数据都拥有相同的权重1/N。然后,我们将下面的步骤重复L次(作用于序列中的L个学习器):
用当前观测数据的权重拟合可能的最佳弱模型 计算更新系数的值,更新系数是弱学习器的某种标量化评估指标,它表示相对集成模型来说,该弱学习器的分量如何 通过添加新的弱学习器与其更新系数的乘积来更新强学习器计算新观测数据的权重,该权重表示我们想在下一轮迭代中关注哪些观测数据(聚和模型预测错误的观测数据的权重增加,而正确预测的观测数据的权重减小)
重复这些步骤,我们顺序地构建出L个模型,并将它们聚合成一个简单的线性组合,然后由表示每个学习器性能的系数加权。注意,初始adaboost算法有一些变体,比如LogitBoost(分类)或L2Boost(回归),它们的差异主要取决于损失函数的选择。
3. 堆叠法(Stacking)
将训练数据分为两组 选择 L 个弱学习器,用它们拟合第一组数据 使 L 个学习器中的每个学习器对第二组数据中的观测数据进行预测 在第二组数据上拟合元模型,使用弱学习器做出的预测作为输入
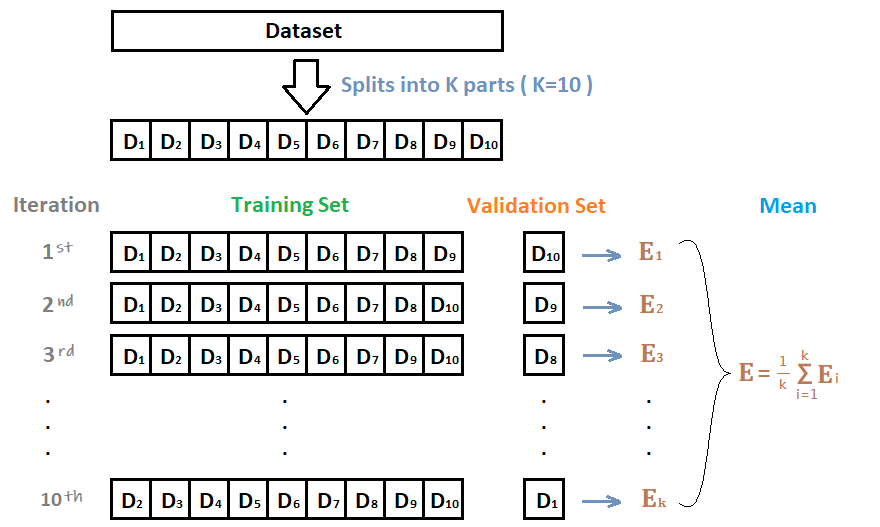
为了克服这种限制,我们可以使用某种k-折交叉训练方法(类似于 k-折交叉验证中的做法)。这样所有的观测数据都可以用来训练元模型:对于任意的观测数据,弱学习器的预测都是通过在k-1折数据(不包含已考虑的观测数据)上训练这些弱学习器的实例来完成的。换句话说,它会在k-1折数据上进行训练,从而对剩下的一折数据进行预测。迭代地重复这个过程,就可以得到对任何一折观测数据的预测结果。这样一来,我们就可以为数据集中的每个观测数据生成相关的预测,然后使用所有这些预测结果训练元模型。
十折交叉验证
那么在十个CNN模型可以使用如下方式进行集成:
对预测的结果的概率值进行平均,然后解码为具体字符 对预测的字符进行投票,得到最终字符
深度学习中的集成学习
丢弃法Dropout 测试集数据扩增TTA Snapshot
1. 丢弃法Dropout
Dropout可以作为训练深度神经网络的一种技巧。在每个训练批次中,通过随机让一部分的节点停止工作。同时在预测的过程中让所有的节点都其作用。
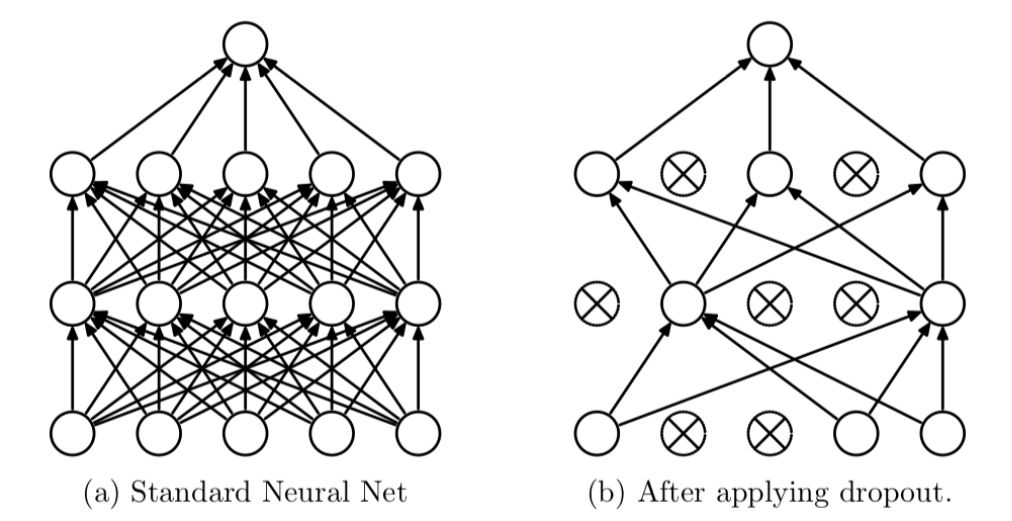
Dropout经常出现在在先有的CNN网络中,可以有效的缓解模型过拟合的情况,也可以在预测时增加模型的精度。加入Dropout后的网络结构如下:
# 定义模型class SVHN_Model1(nn.Module):def __init__(self):super(SVHN_Model1, self).__init__()# CNN提取特征模块self.cnn = nn.Sequential(nn.Conv2d(3, 16, kernel_size=(3, 3), stride=(2, 2)),nn.ReLU(),nn.Dropout(0.25),nn.MaxPool2d(2),nn.Conv2d(16, 32, kernel_size=(3, 3), stride=(2, 2)),nn.ReLU(),nn.Dropout(0.25),nn.MaxPool2d(2),)#self.fc1 = nn.Linear(32*3*7, 11)self.fc2 = nn.Linear(32*3*7, 11)self.fc3 = nn.Linear(32*3*7, 11)self.fc4 = nn.Linear(32*3*7, 11)self.fc5 = nn.Linear(32*3*7, 11)self.fc6 = nn.Linear(32*3*7, 11)def forward(self, img):feat = self.cnn(img)feat = feat.view(feat.shape[0], -1)c1 = self.fc1(feat)c2 = self.fc2(feat)c3 = self.fc3(feat)c4 = self.fc4(feat)c5 = self.fc5(feat)c6 = self.fc6(feat)return c1, c2, c3, c4, c5, c6
2. 测试集数据扩增TTA

def predict(test_loader, model, tta=10):model.eval()test_pred_tta = None# TTA 次数for _ in range(tta):test_pred = []with torch.no_grad():for i, (input, target) in enumerate(test_loader):c0, c1, c2, c3, c4, c5 = model(data[0])output = np.concatenate([c0.data.numpy(), c1.data.numpy(),c2.data.numpy(), c3.data.numpy(),c4.data.numpy(), c5.data.numpy()], axis=1)test_pred.append(output)test_pred = np.vstack(test_pred)if test_pred_tta is None:test_pred_tta = test_predelse:test_pred_tta += test_predreturn test_pred_tta
Snapshot
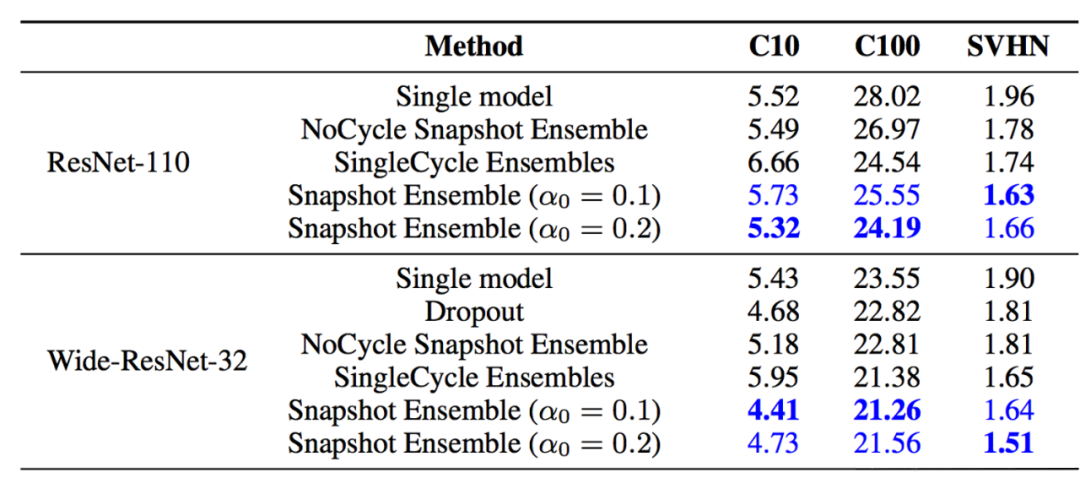
在论文Snapshot Ensembles中,作者提出使用cyclical learning rate进行训练模型,并保存精度比较好的一些checkopint,最后将多个checkpoint进行模型集成。
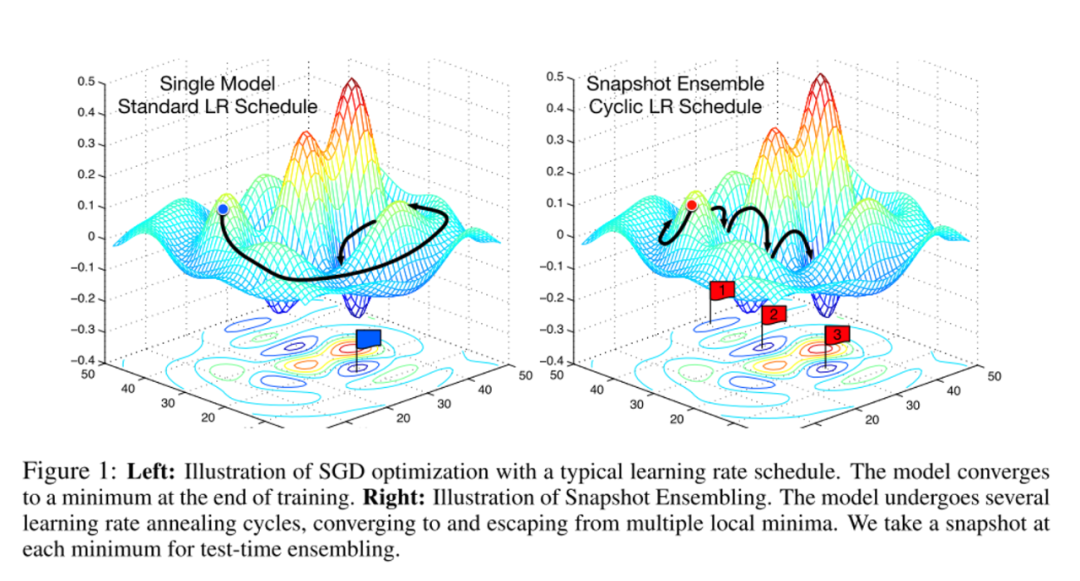
由于在cyclical learning rate中学习率的变化有周期性变大和减少的行为,因此CNN模型很有可能在跳出局部最优进入另一个局部最优。在Snapshot论文中作者通过使用表明,此种方法可以在一定程度上提高模型精度,但需要更长的训练时间。
写到最后
统计图片中每个位置字符出现的频率,使用规则修正结果; 单独训练一个字符长度预测模型,用来预测图片中字符个数,并修正结果。
