
InstanceNorm 梯度公式推导
InstanceNorm 梯度公式推导
【GiantPandaCV导语】本文主内容是推导 InstanceNorm 关于输入和参数的梯度公式,同时还会结合 Pytorch 和 MXNet 里面 InstanceNorm 的代码来分析。
InstanceNorm 与 BatchNorm 的联系
对一个形状为 (N, C, H, W) 的张量应用 InstanceNorm[4] 操作,其实等价于先把该张量 reshape 为 (1, N * C, H, W)的张量,然后应用 BatchNorm[5] 操作。而 gamma 和 beta 参数的每个通道所对应输入张量的位置都是一致的。
而 InstanceNorm 与 BatchNorm 不同的地方在于:
InstanceNorm 训练与预测阶段行为一致,都是利用当前 batch 的均值和方差计算; BatchNorm 训练阶段利用当前 batch 的均值和方差,测试阶段则利用训练阶段通过移动平均统计的均值和方差;
论文[6]中的一张示意图,就很好的解释了两者的联系:
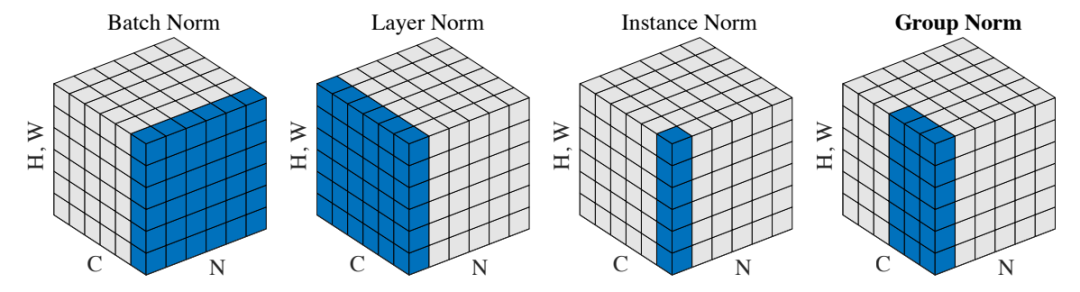
所以 InstanceNorm 对于输入梯度和参数求导过程与 BatchNorm 类似,下面开始进入正题。
梯度推导过程详解
在开始推导梯度公式之前,首先约定输入,参数,输出等符号:
输入张量 , 形状为(N, C, H, W),rehape 为 (1, N * C, M) 其中 M=H*W 参数 ,形状为 (1, C, 1, 1),每个通道值对应 N*M 个输入,在计算的时候首先通过在第0维 repeat N 次再 reshape 成 (1, N*C, 1, 1); 参数 ,形状为 (1, C, 1, 1),每个通道值对应 N*M 个输入,在计算的时候首先通过在第0维 repeat N 次再 reshape 成 (1, N*C, 1, 1);
而输入张量 reshape 成 (1, N * C, M)之后,每个通道上是一个长度为 M 的向量,这些向量之间的计算是不像干的,每个向量计算自己的 normalize 结果。所以求导也是各自独立。因此下面的均值、方差符号约定和求导也只关注于其中一个向量,其他通道上的向量计算都是一样的。
一个向量上的均值 一个向量上的方差 一个向量上一个点的 normalize 中间输出 一个向量上一个点的 normalize 最终输出 ,其中 和 表示这个向量所对应的 gamma 和 beta 参数的通道值。 loss 函数的符号约定为
gamma 和 beta 参数梯度的推导
先计算简单的部分,求 loss 对 和 的偏导:
其中 表示 gamma 和 beta 参数的第 个通道参与了哪些 batch 上向量的 normalize 计算。
因为 gamma 和 beta 上的每个通道的参数都参数与了 N 个 batch 上 M 个元素 normalize 的计算,所以对每个通道进行求导的时候,需要把所有涉及到的位置的梯度都累加在一起。
对于 在具体实现的时候,就是对应输出梯度的值,也就是从上一层回传回来的梯度值。
输入梯度的推导
对输入梯度的求导是最复杂的,下面的推导都是求 loss 相对于输入张量上的一个点上的梯度,而因为上文已知,每个长度是 M 的向量的计算都是独立的,所以下文也是描述其中一个向量上一个点的梯度公式。具体是计算的时候,是通过向量操作(比如 numpy)来完成所有点的梯度计算。
先看 loss 函数对于 的求导:
而从上文约定的公式可知,对于 的计算中涉及到 的有三部分,分别是 、 和 。所以 loss 对于 的偏导可以写成以下的形式:
接下来就是,分别求上面式子最后三项的梯度公式
第一项梯度推导
在求第一项的时候,把 和 看做常量,则有:
然后有:
最后可得第一项梯度公式:
第三项梯度推导
接着先看第三项梯度 ,因为第三项的推导形式简单一些。
先计算上式最后一项 ,把 看做常量:
然后计算 ,等价于求 。而因为每个长度是 M 的向量都会计算一个方差 ,而计算出来的方差又会参数到所有 M 个元素的 normalize 的计算,所以 loss 对于 的偏导需要把所有 M 个位置的梯度累加,所以有:
接着计算 ,
最后可得:
第二项梯度推导
最后计算第二项的梯度 ,一样先计算最后一项 :
接着计算 ,等价于是求 。而因为每个长度是 M 的向量都会计算一个均值 ,而计算出来的均值又会参与到所有 M 个元素的 normalize 的计算,所以 loss 对于 的偏导需要把所有 M 个位置的梯度累加,所以有:
接着计算 ,
最后可得:
输入梯度最终的公式
分别计算完上面三项,就能得到对于输入张量每个位置上梯度的最终公式了:
观察上式可以发现,loss 对 的求导公式包括了 loss 对 求导的公式,所以这也是为什么先计算第三项的原因,在下面代码实现上也可以体现。
而在具体实现的时候就是直接套公式计算就可以了,下面来看下在 Pytroch 和 MXNet 框架中对 InstanceNorm 的实现。
主流框架实现代码解读
Pytroch 前向传播实现
前向代码链接:https://github.com/pytorch/pytorch/blob/fa153184c8f70259337777a1fd1d803c7325f758/aten%2Fsrc%2FATen%2Fnative%2FNormalization.cpp#L506
为了可读性简化了些代码:
Tensor instance_norm(
const Tensor& input,
const Tensor& weight/* optional */,
const Tensor& bias/* optional */,
const Tensor& running_mean/* optional */,
const Tensor& running_var/* optional */,
bool use_input_stats,
double momentum,
double eps,
bool cudnn_enabled) {
// ......
std::vector<int64_t> shape =
input.sizes().vec();
int64_t b = input.size(0);
int64_t c = input.size(1);
// shape 从 (b, c, h, w)
// 变为 (1, b*c, h, w)
shape[1] = b * c;
shape[0] = 1;
// repeat_if_defined 的解释见下文
Tensor weight_ =
repeat_if_defined(weight, b);
Tensor bias_ =
repeat_if_defined(bias, b);
Tensor running_mean_ =
repeat_if_defined(running_mean, b);
Tensor running_var_ =
repeat_if_defined(running_var, b);
// 改变输入张量的形状
auto input_reshaped =
input.contiguous().view(shape);
// 计算实际调用的是 batchnorm 的实现
// 所以可以理解为什么 pytroch
// 前端 InstanceNorm2d 的接口
// 与 BatchNorm2d 的接口一样
auto out = at::batch_norm(
input_reshaped,
weight_, bias_,
running_mean_,
running_var_,
use_input_stats,
momentum,
eps, cudnn_enabled);
// ......
return out.view(input.sizes());
}
repeat_if_defined 的代码:
https://github.com/pytorch/pytorch/blob/fa153184c8f70259337777a1fd1d803c7325f758/aten%2Fsrc%2FATen%2Fnative%2FNormalization.cpp#L27
static inline Tensor repeat_if_defined(
const Tensor& t,
int64_t repeat) {
if (t.defined()) {
// 把 tensor 按第0维度复制 repeat 次
return t.repeat(repeat);
}
return t;
}
从 pytorch 前向传播的实现上看,验证了本文开头说的关于 InstanceNorm 与 BatchNorm 的联系。还有对于参数 gamma 与 beta 的处理方式。
MXNet 反向传播实现
因为我个人感觉 MXNet InstanceNorm 的反向传播实现很直观,所以选择解读其实现:
https://github.com/apache/incubator-mxnet/blob/4a7282f104590023d846f505527fd0d490b65509/src%2Foperator%2Finstance_norm-inl.h#L112
同样为了可读性简化了些代码:
template<typename xpu>
void InstanceNormBackward(
const nnvm::NodeAttrs& attrs,
const OpContext &ctx,
const std::vector &inputs,
const std::vector &req,
const std::vector &outputs) {
using namespace mshadow;
using namespace mshadow::expr;
// ......
const InstanceNormParam& param =
nnvm::get(
attrs.parsed);
Stream *s =
ctx.get_stream();
// 获取输入张量的形状
mxnet::TShape dshape =
inputs[3].shape_;
// ......
int n = inputs[3].size(0);
int c = inputs[3].size(1);
// rest_dim 就等于上文的 M
int rest_dim =
static_cast<int>(
inputs[3].Size() / n / c);
Shape<2> s2 = Shape2(n * c, rest_dim);
Shape<3> s3 = Shape3(n, c, rest_dim);
// scale 就等于上文的 1/M
const real_t scale =
static_cast<real_t>(1) /
static_cast<real_t>(rest_dim);
// 获取输入张量
Tensor2> data = inputs[3]
.get_with_shape2, real_t>(s2, s);
// 保存输入梯度
Tensor2> gdata = outputs[kData]
.get_with_shape2, real_t>(s2, s);
// 获取参数 gamma
Tensor1> gamma =
inputs[4].get1, real_t>(s);
// 保存参数 gamma 梯度计算结果
Tensor1> ggamma = outputs[kGamma]
.get1, real_t>(s);
// 保存参数 beta 梯度计算结果
Tensor1> gbeta = outputs[kBeta]
.get1, real_t>(s);
// 获取输出梯度
Tensor2> gout = inputs[0]
.get_with_shape2, real_t>(
s2, s);
// 获取前向计算好的均值和方差
Tensor1> var =
inputs[2].FlatTo1Dreal_t>(s);
Tensor1> mean =
inputs[1].FlatTo1Dreal_t>(s);
// 临时空间
Tensor2> workspace = //.....
// 保存均值的梯度
Tensor1> gmean = workspace[0];
// 保存方差的梯度
Tensor1> gvar = workspace[1];
Tensor1> tmp = workspace[2];
// 计算方差的梯度,
// 对应上文输入梯度公式的第三项
// gout 对应输出梯度
gvar = sumall_except_dim<0>(
(gout * broadcast<0>(
reshape(repmat(gamma, n),
Shape1(n * c)), data.shape_)) *
(data - broadcast<0>(
mean, data.shape_)) * -0.5f *
F(
broadcast<0>(
var + param.eps, data.shape_),
-1.5f)
);
// 计算均值的梯度,
// 对应上文输入梯度公式的第二项
gmean = sumall_except_dim<0>(
gout * broadcast<0>(
reshape(repmat(gamma, n),
Shape1(n * c)), data.shape_));
gmean *=
-1.0f / F(
var + param.eps);
tmp = scale * sumall_except_dim<0>(
-2.0f * (data - broadcast<0>(
mean, data.shape_)));
tmp *= gvar;
gmean += tmp;
// 计算 beta 的梯度
// 记得s3 = Shape3(n, c, rest_dim)
// 那么swapaxis<1, 0>(reshape(gout, s3))
// 就表示首先把输出梯度 reshape 成
// (n, c, rest_dim),接着交换第0和1维度
// (c, n, rest_dim),最后求除了第0维度
// 之外其他维度的和,
// 也就和 beta 的求导公式对应上了
Assign(gbeta, req[kBeta],
sumall_except_dim<0>(
swapaxis<1, 0>(reshape(gout, s3))));
// 计算 gamma 的梯度
// swapaxis<1, 0> 的作用与上面 beta 一样
Assign(ggamma, req[kGamma],
sumall_except_dim<0>(
swapaxis<1, 0>(
reshape(gout *
(data - broadcast<0>(mean,
data.shape_))
/ F(
broadcast<0>(
var + param.eps,
data.shape_
)
), s3
)
)
)
);
// 计算输入的梯度,
// 对应上文输入梯度公式三项的相加
Assign(gdata, req[kData],
(gout * broadcast<0>(
reshape(repmat(gamma, n),
Shape1(n * c)), data.shape_))
* broadcast<0>(1.0f /
F(
var + param.eps), data.shape_)
+ broadcast<0>(gvar, data.shape_)
* scale * 2.0f
* (data - broadcast<0>(
mean, data.shape_))
+ broadcast<0>(gmean,
data.shape_) * scale);
}
可以看到基于 mshadow 模板库的反向传播实现,看起来很直观,基本是和公式能对应上的。
InstanceNorm numpy 实现
最后看下 InstanceNorm 前向计算与求输入梯度的 numpy 实现
import numpy as np
import torch
eps = 1e-05
batch = 4
channel = 2
height = 32
width = 32
input = np.random.random(
size=(batch, channel, height, width)).astype(np.float32)
# gamma 初始化为1
# beta 初始化为0,所以忽略了
gamma = np.ones((1, channel, 1, 1),
dtype=np.float32)
# 随机生成输出梯度
gout = np.random.random(
size=(batch, channel, height, width))\
.astype(np.float32)
# 用numpy计算前向的结果
mean_np = np.mean(
input, axis=(2, 3), keepdims=True)
in_sub_mean = input - mean_np
var_np = np.mean(
np.square(in_sub_mean),
axis=(2, 3), keepdims=True)
invar_np = 1.0 / np.sqrt(var_np + eps)
out_np = in_sub_mean * invar_np * gamma
# 用numpy计算输入梯度
scale = 1.0 / (height * width)
# 对应输入梯度公式第三项
gvar =
gout * gamma * in_sub_mean *
-0.5 * np.power(var_np + eps, -1.5)
gvar = np.sum(gvar, axis=(2, 3),
keepdims=True)
# 对应输入梯度公式第二项
gmean = np.sum(
gout * gamma,
axis=(2, 3), keepdims=True)
gmean *= -invar_np
tmp = scale * np.sum(-2.0 * in_sub_mean,
axis=(2, 3), keepdims=True)
gmean += tmp * gvar
# 对应输入梯度公式三项之和
gin_np =
gout * gamma * invar_np
+ gvar * scale * 2.0 * in_sub_mean
+ gmean * scale
# pytorch 的实现
p_input_tensor =
torch.tensor(input, requires_grad=True)
trans = torch.nn.InstanceNorm2d(
channel, affine=True, eps=eps)
p_output_tensor = trans(p_input_tensor)
p_output_tensor.backward(
torch.Tensor(gout))
# 与 pytorch 对比结果
print(np.allclose(out_np,
p_output_tensor.detach().numpy(),
atol=1e-5))
print(np.allclose(gin_np,
p_input_tensor.grad.numpy(),
atol=1e-5))
# 命令行输出
# True
# True
总结
本文对于 InstanceNorm 的梯度公式推导大部分参考了博客[1][2]的内容,然后在参考博客的基础上,按自己的理解具体推导了一遍,很多时候是从结果往回推,在推导过程中会有不太严谨的地方,如果有什么疑惑或意见,欢迎交流。
参考资料:
[1] https://medium.com/@drsealks/batch-normalisation-formulas-derivation-253df5b75220 [2] https://kevinzakka.github.io/2016/09/14/batch_normalization/ [3] https://www.zhihu.com/question/68730628 [4] https://arxiv.org/pdf/1607.08022.pdf [5] https://arxiv.org/pdf/1502.03167v3.pdf [6] https://arxiv.org/pdf/1803.08494.pdf