CV之后,纯MLP架构又来搞NLP了,性能媲美预训练大模型
搞不起大模型,试一下超高性能的纯 MLP 架构?

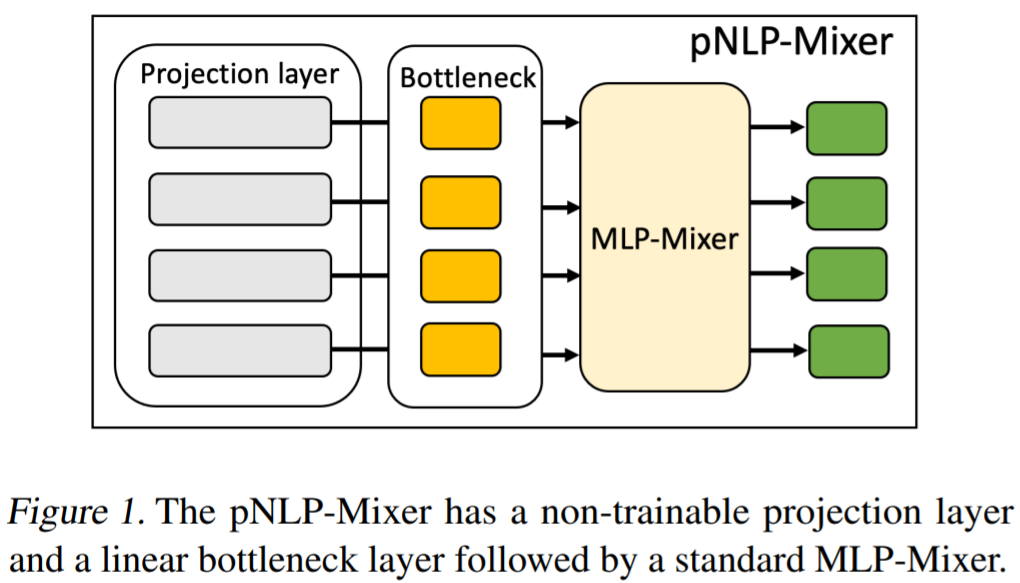
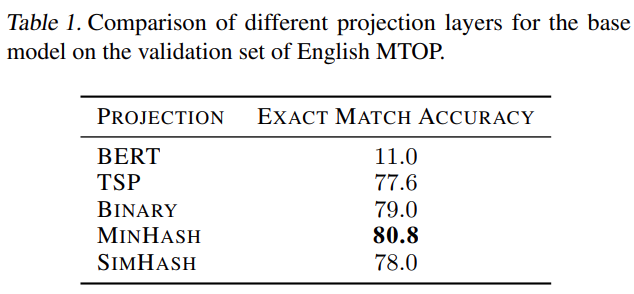
BERT 嵌入
二进制
TSP
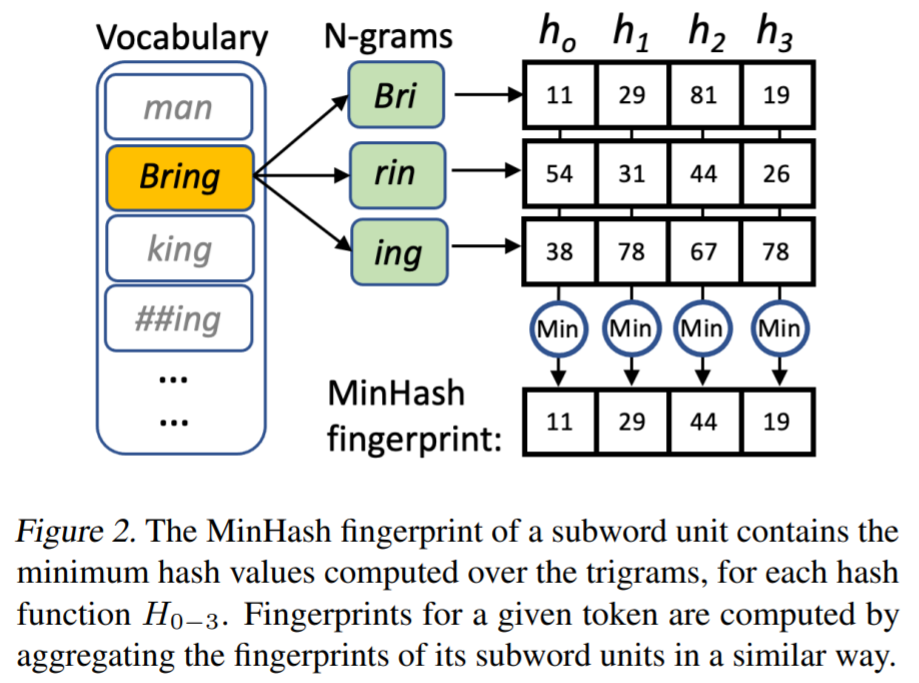
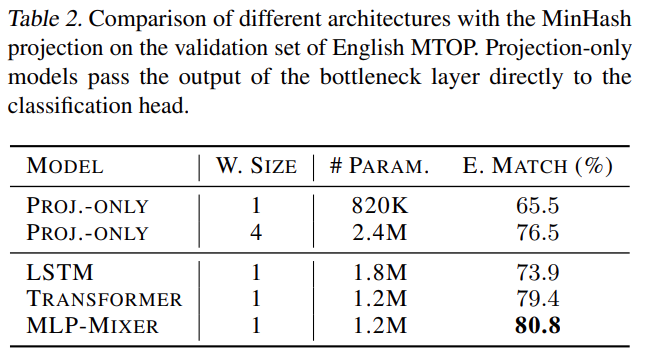
MinHash
SimHash
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com

点个在看 paper不断!
评论
 下载APP
下载APP搞不起大模型,试一下超高性能的纯 MLP 架构?
BERT 嵌入
二进制
TSP
MinHash
SimHash
© THE END
转载请联系原公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
点个在看 paper不断!