
从Embedding到XLNet:NLP预训练模型简介
深度学习
Author:louwill
Machine Learning Lab
迁移学习和预训练模型不仅在计算机视觉应用广泛,在NLP领域也逐渐成为主流方法。近来不断在各项NLP任务上刷新最佳成绩的各种预训练模型值得我们第一时间跟进。本节对NLP领域的各种预训练模型进行一个简要的回顾,对从初始的Embedding模型到ELMo、GPT、到谷歌的BERT、再到最强NLP预训练模型XLNet。梳理NLP预训练模型发展的基本脉络,对当前NLP发展的基本特征进行概括。
从Embedding到ELMo
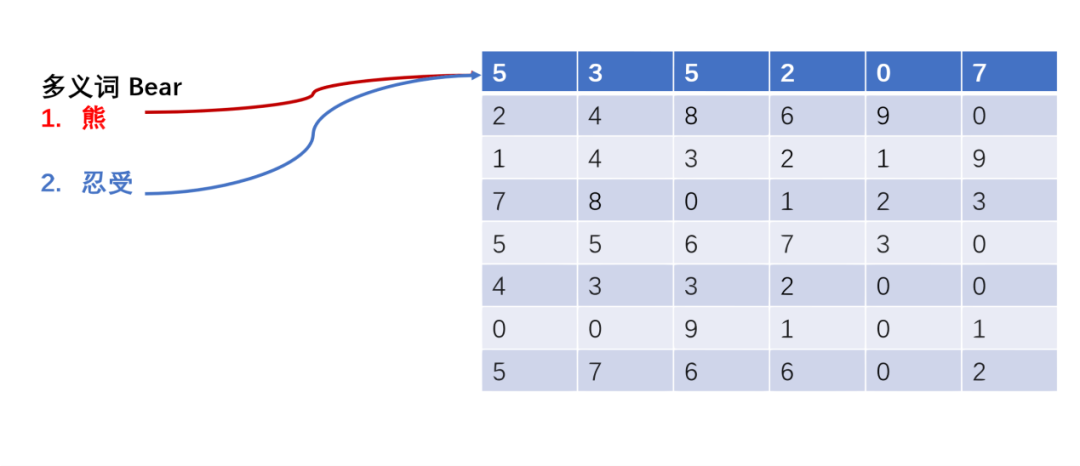
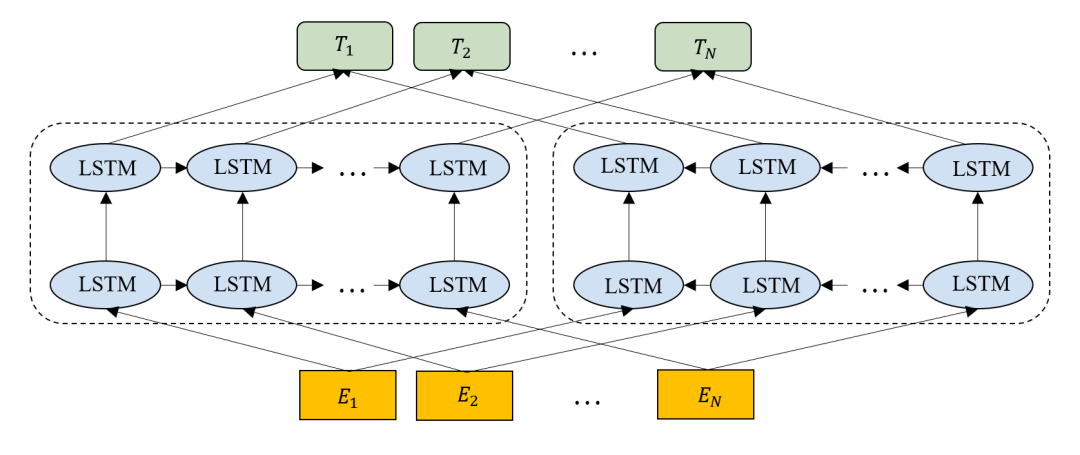
图2 ELMo结构

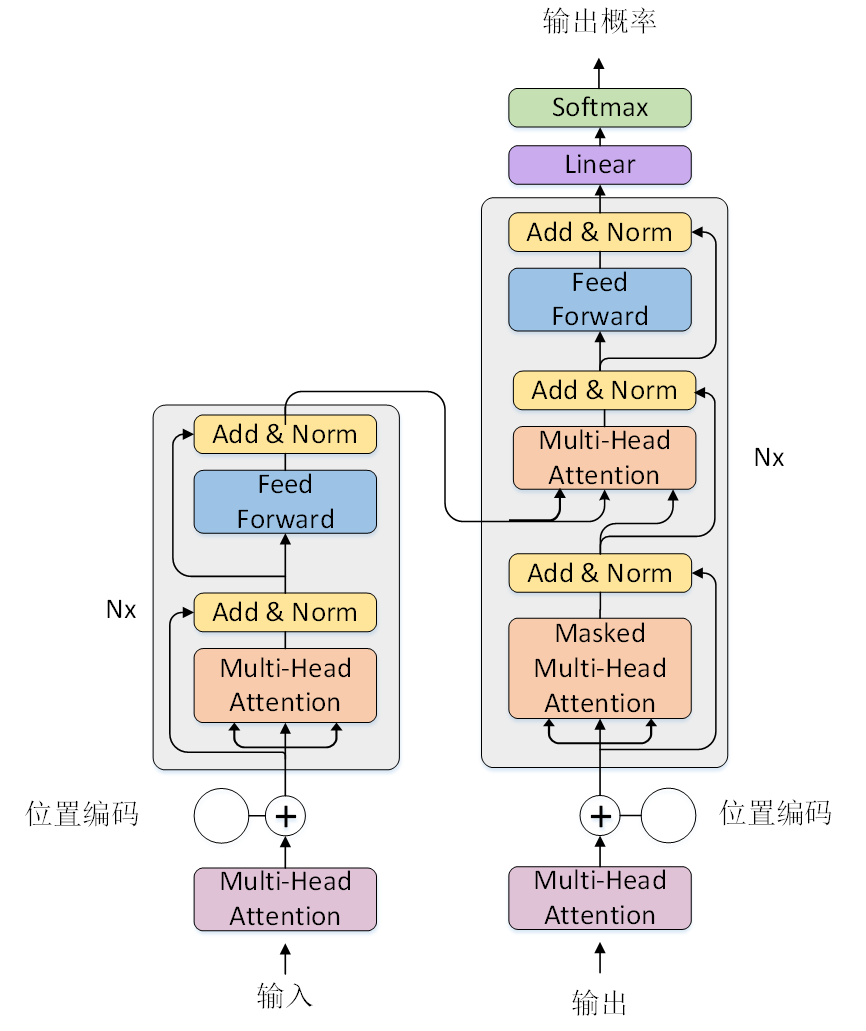
特征提取器:Transformer
低调王者:GPT
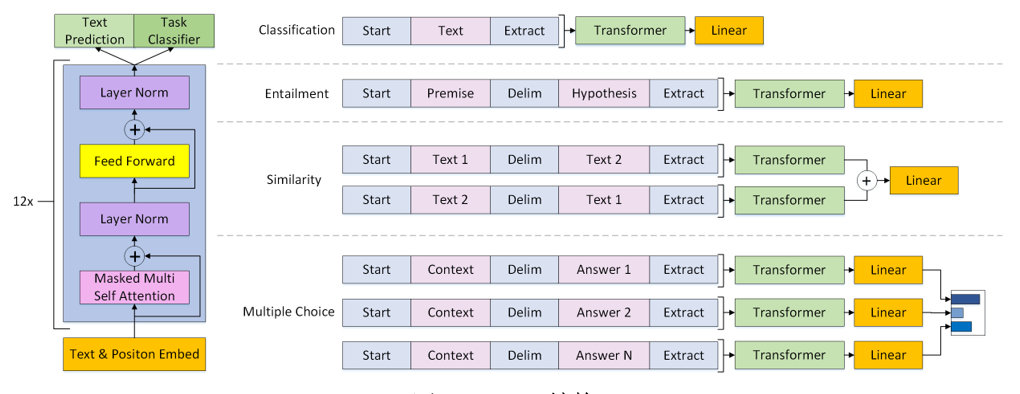
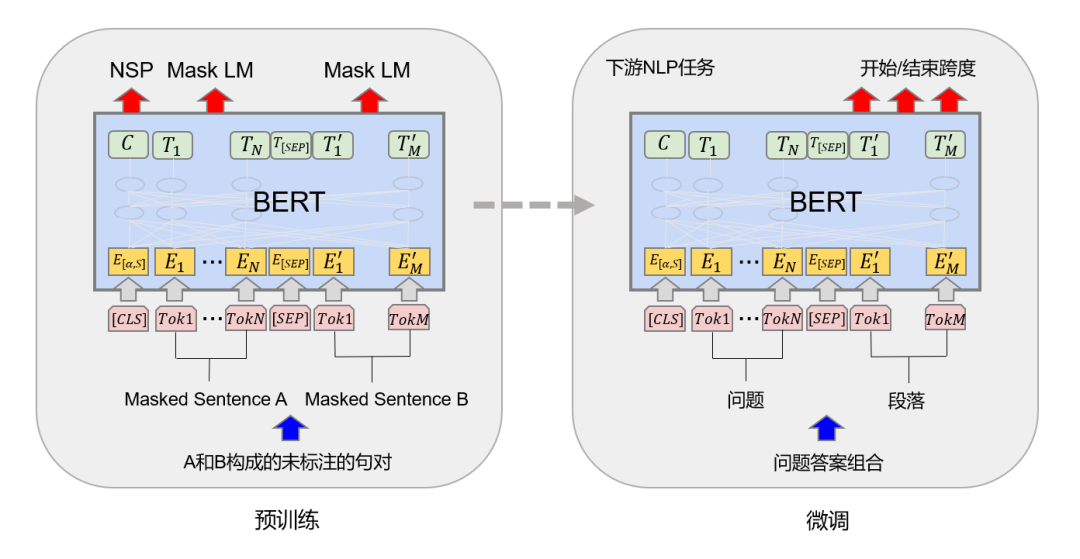
封神之作:BERT
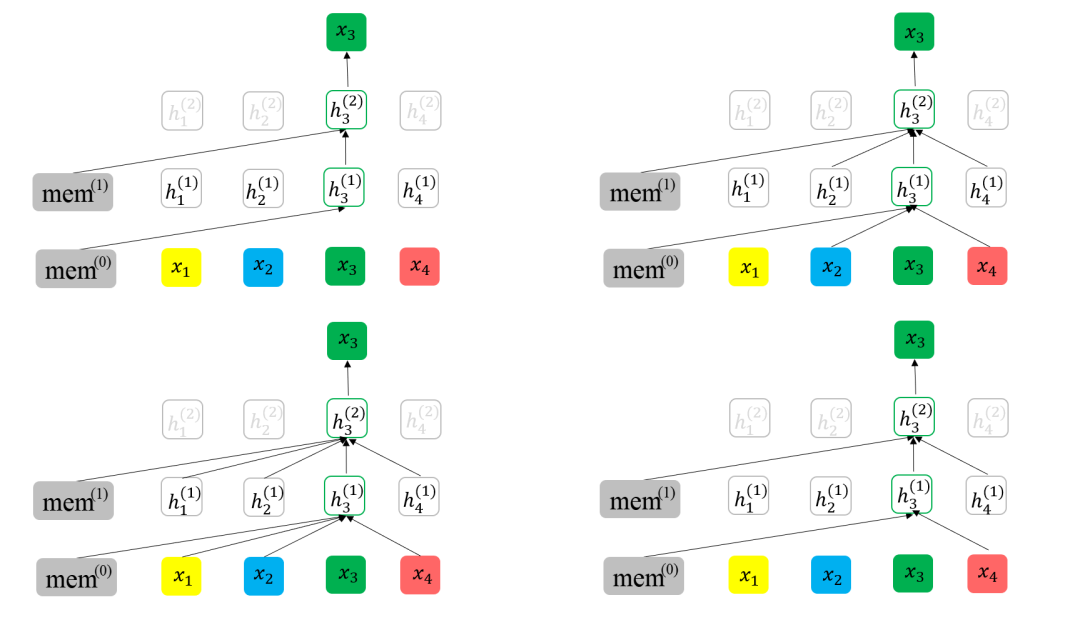
持续创新:XLNet
往期精彩:
求个在看
评论