
NLP和CV的双子星,注入Mask的预训练模型BERT和MAE
从BERT和MAE的形态上来说,都引入了mask机制来做无监督预训练,但是又因为vision和language两种模态上本质的不同,导致mask的设计上和整体框架上有所区别。从NLP的Transformer到BERT,然后到CV的ViT、BEiT,CV领域的无监督预训练经历了漫长的探索,直到MAE的出现,才逐渐感觉到CV的大规模无监督预训练开始走向正轨。
本文先捋顺NLP和CV相关文章之间的关系脉络,然后探讨一下BEiT和MAE的关系,最后探讨一下BERT和MAE的关系。
双子星BERT和MAE
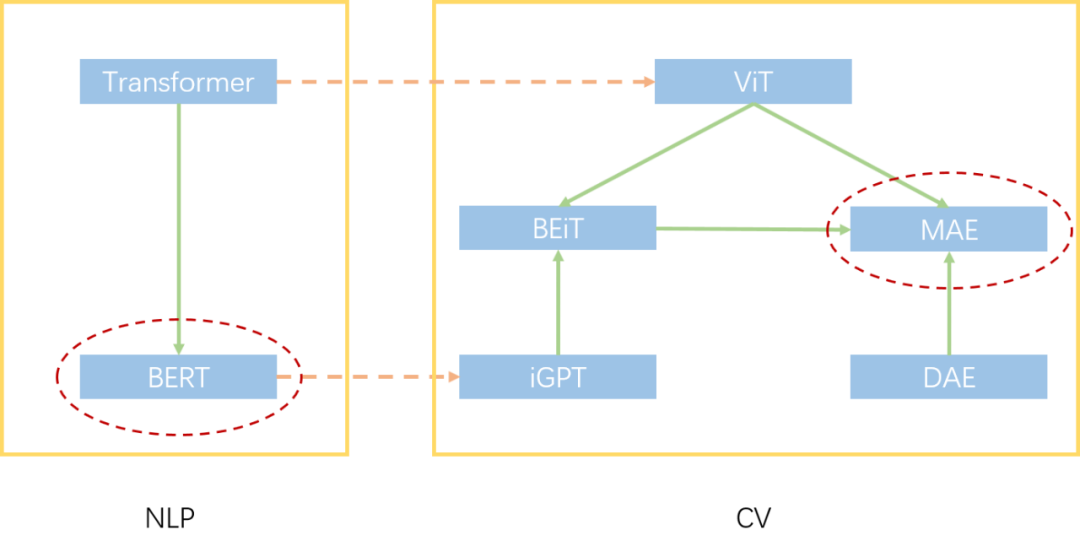
BERT和MAE的关系图。橙色虚线表示NLP和CV跨领域启发,绿色实线表示领域内启发。
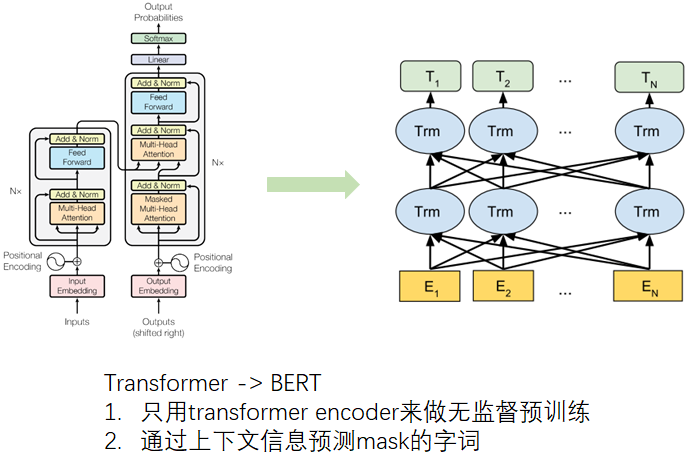
Transformer是整个大规模无监督预训练的开端,Transformer改变了原有Seq2Seq的串行计算的方式,通过矩阵并行计算大幅度提升了长距离依赖的计算效率,并且由于整个框架完全采用attention,Transformer的拟合能力空前绝后。
BERT得益于Transformer强大的计算效率,构造一种类似完形填空的proxy task,可以将不同NLP任务的语料一起拿来做无监督预训练,然后将预训练好的transformer encoder应用于下游任务。
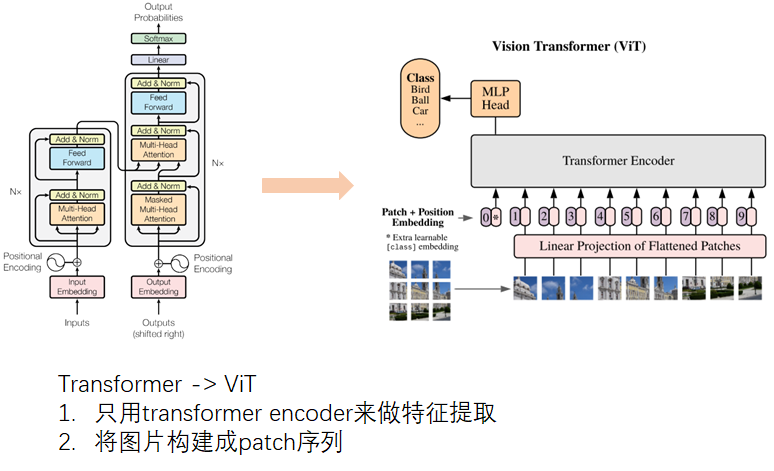
ViT巧妙的将图片构造成patch序列,可以将patch序列送入原始的transformer encoder进行图像分类,ViT直接启发了Transformer和BERT在CV领域的正确打开方式。
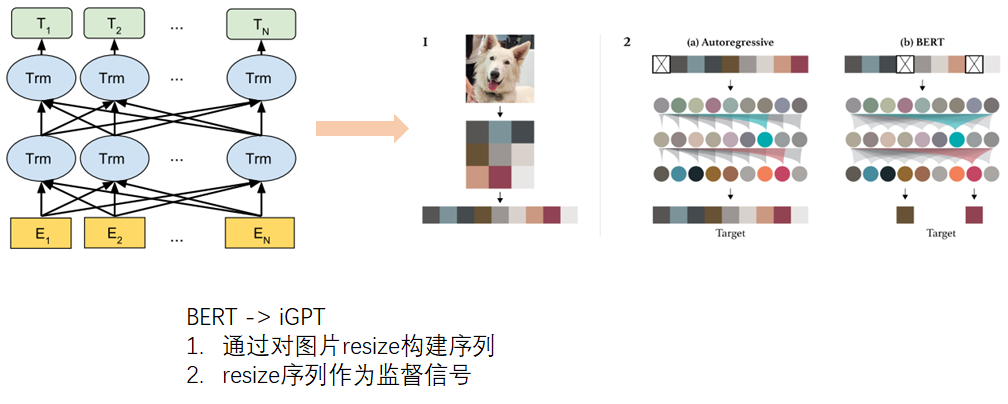
iGPT应该是第一个应用BERT-like的mask方式做CV领域无监督预训练的工作。iGPT把图片resize构建resize序列,同时将resize序列当作监督信号,可以直接使用BERT进行CV的无监督预训练,这给予了cv领域极大的想象空间。
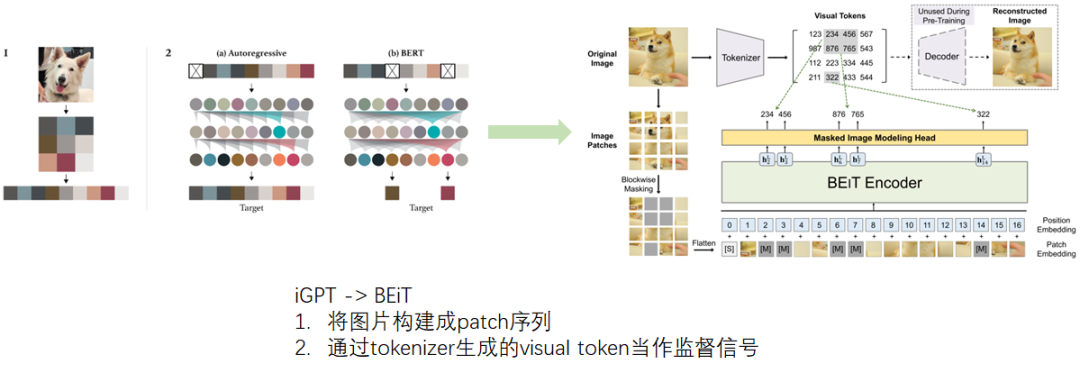
BEiT对iGPT无监督预训练方法进行了改进,借鉴ViT的思路,将图片构建成patch序列,并且通过一个tokenizer得到visual token,用学习的方式得到更精确的监督信号,避免了resize导致的大量信息丢失。
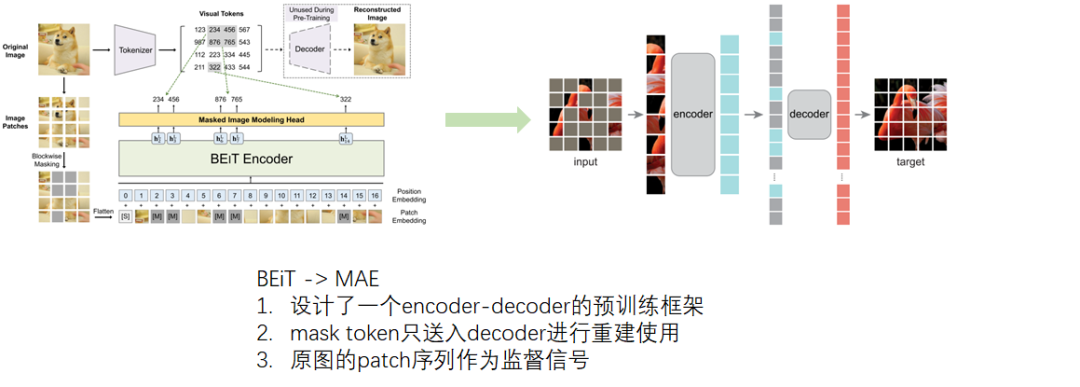
重头戏来了!MAE做的更为极致,设计了一个encoder-decoder预训练框架,encoder只送入image token,decoder同时送入image token和mask token,对patch序列进行重建,最后还原成图片。相比于BEiT,省去了繁琐的训练tokenizer的过程,同时对image token和mask token进行解耦,特征提取和图像重建进行解耦,encoder只负责image token的特征提取,decoder专注于图像重建,这种设计直接导致了训练速度大幅度提升,同时提升精度,真称得上MAE文章中所说的win-win scenario了。
BEiT如今的处境就如同当年NLP的ELMO的处境,碰上MAE如此完美的方法,大部分影响力必然会被MAE给蚕食掉。BERT对整个大规模无监督预训练的发展影响巨大,MAE可能是NLP和CV更紧密结合的开始。
MAE
mask autoencoder在cv领域中起源于denoising autoencoder(DAE),iGPT和BEiT实际上都包含了DAE的思想(DAE是bengio在08年提出来的,DAE认为对输入加噪声,模型可以学习到更鲁棒的特征),MAE则略有不同,将image token和mask token解耦,encoder只对image token进行学习,mask token只在decoder图像重建中使用。
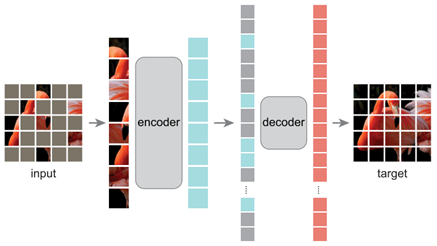
MAE整体上是一个encoder-decoder框架,encoder只对visible patches进行处理,decoder同时处理image token和mask token,得到重建序列,最后还原成图片。其中visible patches是通过shuffle所有patches然后采样前25%得到的(即mask ratio为75%),decoder的输入image token和mask token通过unshuffle还原顺序,并且都需要添加positional embedding来保持patch的位置信息。

通过简单设计,MAE在mask ratio高达95%的时候,仍然能够还原出强语义的信息。

MAE文章中的fig2还有一行小字,意思是说之所以不把visible patches和reconstruction patches合起来显示,就是为了让你们看看我们的算法有多强,蚌埠住了。
Main Properties
接下来看一看最精彩的实验部分
Masking ratio
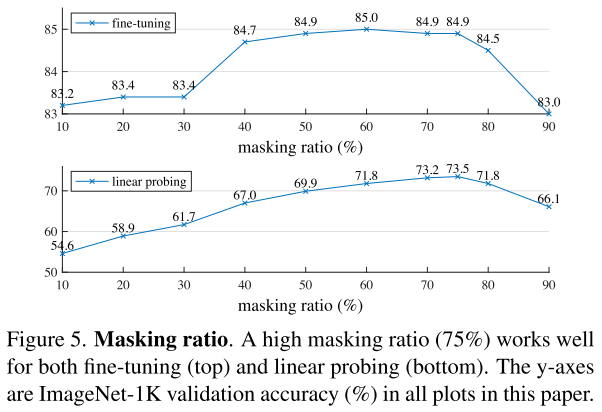
这是MAE最为关键的实验,随着mask ratio的增加,fine-tuning和linear probing的精度竟然逐渐攀升,直到75%的mask ratio还不大幅度掉点,这个实验结论跟之前的工作相差甚远(BEiT的mask ratio是40%),违背直觉的结论往往是推动领域进步的开始。
Decoder design

MAE对decoder的depth和width进行探索,发现depth和width并不起决定性作用,最后MAE为了兼顾linear probing精度选择8个blocks,512-d作为默认配置。
Mask token

MAE在encoder部分做mask token的消融实验,发现同时在encoder送入image token和mask token会导致fine-tuning和inear probling掉点,尤其是linear probling掉了10几个点,并且计算量增加了3.3倍,该实验表明encoder使用mask token会导致encoder的提取特征能力减弱。
Reconstruction target
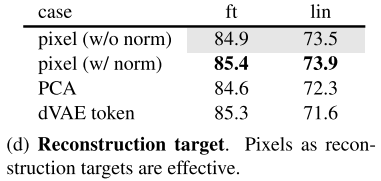
MAE对reconstruction target做了消融实验,发现基于token的target相比于基于pixel的target不占优势,带norm的pixel的target同时在fine-tuning和linear-tuning达到最优,表明基于token的target存在信息丢失问题。
Data augmentation

通过data augmentation的消融实验,表明MAE对于数据增强的需求并不强烈,在较弱的数据增强下,反而能够取得最好的精度,推测是因为重建任务本身就不需要强烈的数据增强,过于强烈的数据增强会导致信息失真。
Mask sampling strategy


尝试不同的mask采样策略,发现随机采样效果是最好的,这也挺符合直觉的,随机采样得到的visible patches组合多样性更好。
Training schedule
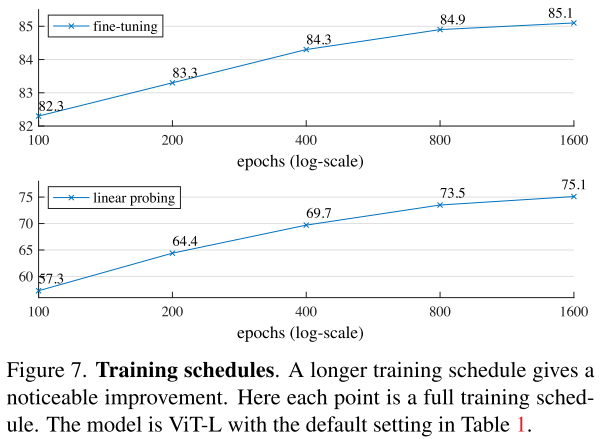
通过增加训练的epoch,MAE在fine-tuning和linear probing上可以持续提升精度,并且直到1600epoch还未见到衰退现象,说明了MAE抽象语义信息的能力之强。
Comparisons with self-supervised methods
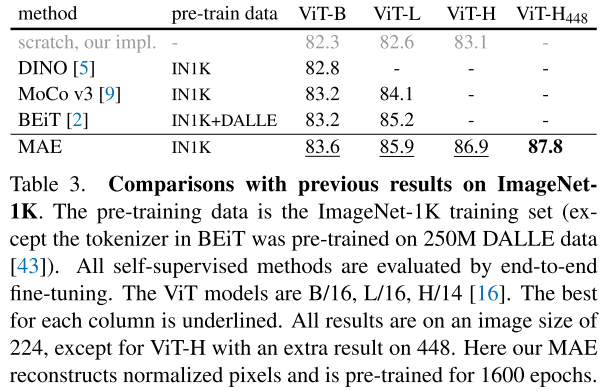
和之前self-supervised方法进行比较,MAE在只使用ImageNet-1K(IN1k)的情况下,更具优势,并且在使用ViT-H488的backbone上取得了只使用IN1k的最好精度。
Comparisons with supervised pre-training
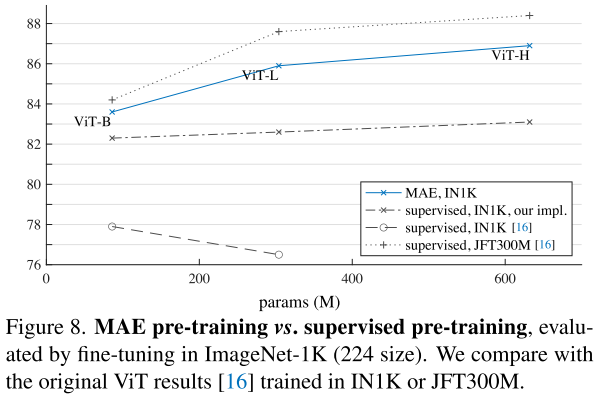
MAE和supervised pre-training的进行比较,发现MAE大幅度超过只使用IN1K的supervised pre-training,而且和使用JFT300M的supervised pre-training相差不多。
Partial Fine-tuning
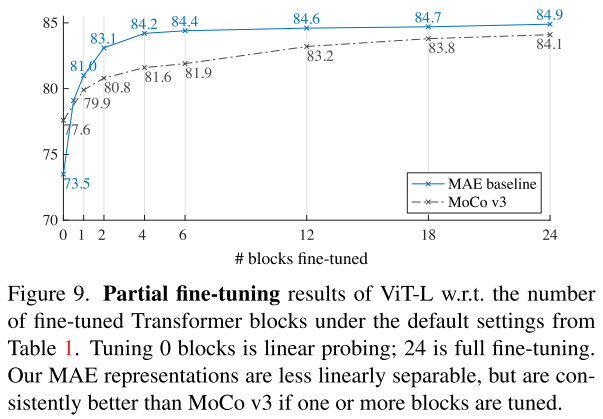
MAE进一步指出linear probling指标对于非线性能力强的深度学习来说是不合理的。为了用更合理的指标评估深度学习的非线性能力,MAE建议使用partial fine-tuning的评价指标。使用partial fine-tuning评价指标,发现MAE在微调0层的时候,不如MoCov3,当微调层数大于0层的时候,MAE开始逐渐超过MoCov3的精度,这个实验证明了MAE的非线性能力很强,同时也说明了linear probling指标的不合理性。
Transfer Learning Experiments

将MAE的encoder迁移到下游任务中,通过COCO和ADE20K两个数据集,证明了MAE迁移目标检测和语义分割任务的优越性。
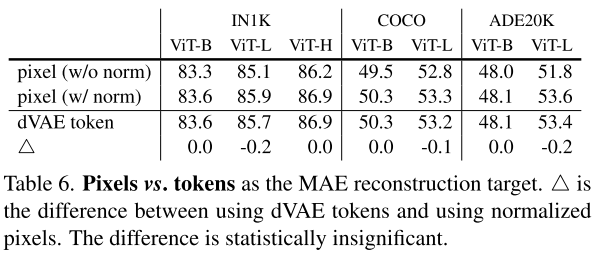
同时MAE也比较了一下pixel和token的target对于下游任务的影响,实验发现token的target对于下游任务来说也同样没有优势,甚至会轻微掉点。
下面试图解释一下MAE能work的4点原因:
图片构建成patch序列。构建成patch序列的方式,带来了许多优势:相比于self-supervised的global对比学习,patch序列可以学习到更细粒度的语义信息;相比于pixel序列,计算量大幅度降低,并且减少了pixel level的大量噪声;相比于iGPT的resize序列,避免了resize的信息丢失。
image token和mask token解耦。MAE在encoder部分只使用image token,使得encoder学到的特征更加干净,mask token只在decoder中进行使用,同时这种设计可以大幅度的降低encoder的计算量。
特征提取和图像重建解耦。MAE的encoder只负责特征提取,decoder只负责图像重建,所以decoder不需要很大的计算量。encoder是下游任务真正想要的,最后用于下游任务的时候,把不干净的decoder扔掉就好了。而BEiT的encoder是需要同时兼顾特征提取和图像重建,需要同时将image token和mask token映射到一个低维空间中,特征提取需要迁就图像重建,降低了encoder的上限。特征提取和图像重建解耦也是高mask ratio的关键。
pixel的重建目标。pixel的重建目标可以尽可能的利用好图像信息,避免监督信息的丢失,而iGPT和BEiT的resize重建目标和token重建目标都会有不同程度的监督信息的丢失,降低了encoder的上限。
还有一个小细节

重建loss只作用在mask token上,这会提升0.5个点,这个设计使得image token和mask token的解耦更加彻底,试想一下,如果image token也计算重建loss,这会导致encoder的输出和decoder没办法完全解耦,image token的重建loss梯度会回传到encoder上,导致encoder将一部分注意力分散到了重建任务上,增加了encoder的学习难度。
image token和mask token解耦对于encoder的影响
这里我画了一个图来解释一下image token和mask token解耦对于encoder的影响。
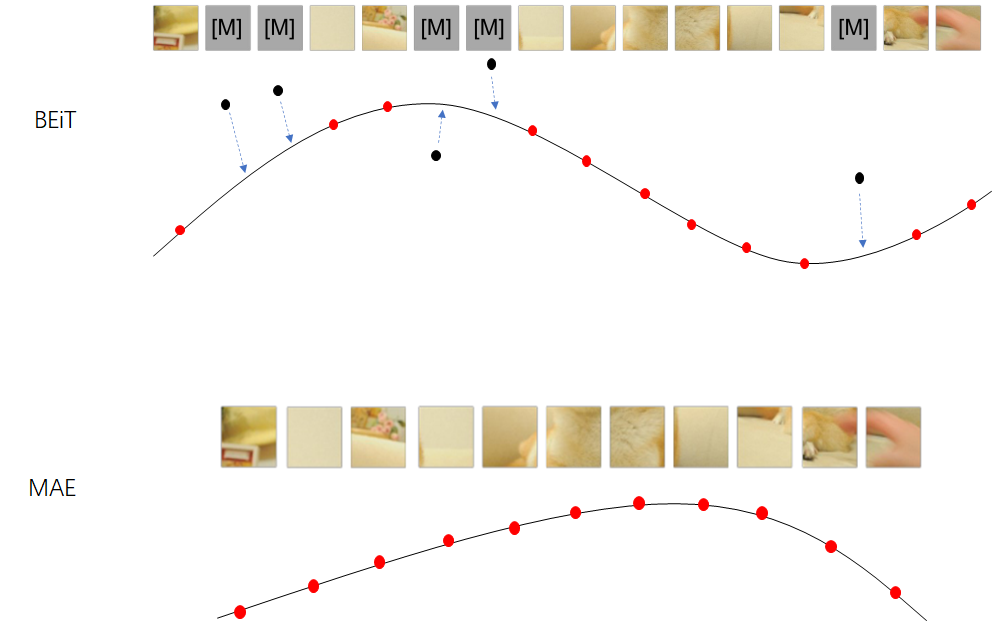
image token和mask token同时送入encoder,相当于是将两个不同高维空间映射到一个低维空间中,假设image token映射到了一个低维空间中,那么encoder就需要分散出一部分的注意力将mask token映射到同一个空间。而MAE的encoder只对image token进行映射,这个映射空间不要对mask token进行迁就,能够尽可能的得到干净的语义特征,提高了encoder的上限。
BERT vs MAE
MAE另一个有意思的点是通过mask ratio揭示了vision和language两种模态之间本质差异。
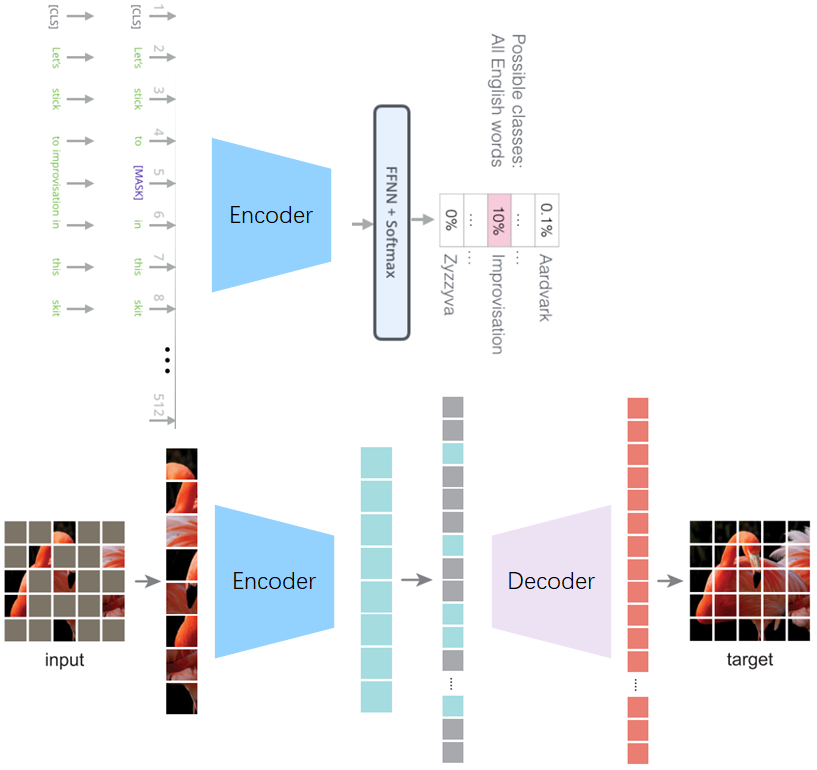
将BERT和MAE的框架进行比较,MAE多了一个decoder重建的过程,并且mask token只用于decoder。BERT的和MAE的encoder功能性有所不同,BERT的功能性更类似于MAE的decoder重建,通过上下文来预测mask信息,而MAE的encoder主要是为了得到好的特征表达,用于图像信息的高度抽象。正是由于language本身就是高度抽象的信息,只需要通过encoder进行重建即可,而vision本身有大量的冗余信息需要先通过encoder获得高度抽象的信息,然后再通过decoder进行重建。另外,NLP大多数的下游任务和BERT的预测mask信息是兼容的,而CV大多数的下游任务不需要重建,而是为了获得高度抽象信息(比如图像分类、目标检测、语义分割),也就是只需要encoder。
另外讲一下mask ratio和模型复杂度还有特征表达之间的关系。
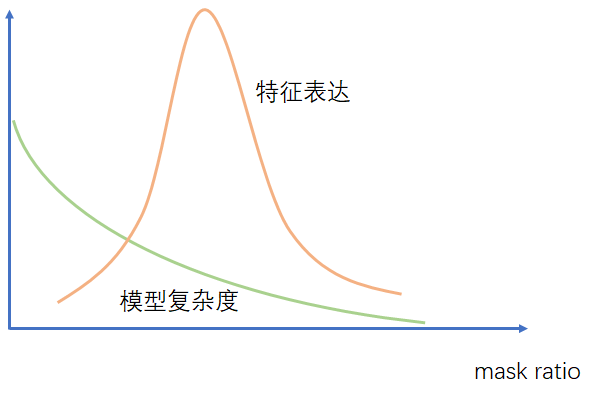
实际上,随着mask ratio的上升,模型复杂度逐渐降低(正则逐渐上升),而特征表达能力上,是先上升后下降的过程。一开始mask ratio比较低,噪声比较大,学到的特征不够干净,特征表达能力弱,随着mask ratio的增加,噪声逐渐减小,特征表达能力逐渐增加,直到mask ratio过大,不能从有效的特征中学到合适的特征表达。
这也能解释为什么vision是高mask ratio(75%),而language是低mask ratio(15%)。上面也说到language本身就是高度抽象的信息,而vision是带有大量冗余的信息,也就是说特征表达能力最强的最优mask ratio,language会更小,vision会更大。因为language噪声更小,需要通过更多的上下文信息推理相互关系,而vision需要减少冗余信息的噪声,通过更小的模型复杂度学到真正的语义信息。
mask ratio其实是在找最适合数据的模型复杂度,mask越多,模型越简单,mask越少,模型越复杂。
Reference
[1] Masked Autoencoders Are Scalable Vision Learners
[2] BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
[3] BEIT: BERT Pre-Training of Image Transformers
[4] Generative Pretraining from Pixels
[5] Extracting and composing robust features with denoising autoencoders
[6] AN IMAGE IS WORTH 16X16 WORDS: TRANSFORMERS FOR IMAGE RECOGNITION AT SCALE
[7] Attention Is All You Need
[8] jalammar.github.io/illustrated-bert/
——The End——


觉得有用给个在看吧 