
DAFormer | 使用Transformer进行语义分割无监督域自适应的开篇之作



由于为语义分割标注真实图像是一个代价昂贵的过程,因此可以用更容易获得的合成数据训练模型,并在不需要标注的情况下适应真实图像。
在
无监督域适应(UDA)中研究了这一过程。尽管有大量的方法提出了新的适应策略,但它们大多是基于比较经典的网络架构。由于目前网络结构的影响尚未得到系统的研究,作者首先对UDA的不同网络结构进行了基准测试,并揭示了Transformer在UDA语义分割方面的潜力。在此基础上提出了一种新的UDA方法DAFormer。
DAFormer的网络结构包括一个Transformer编码器和一个多级上下文感知特征融合解码器。它是由3个简单但很关键的训练策略来稳定训练和避免对源域的过拟合:
源域上的罕见类采样通过减轻 Self-training对普通类的确认偏差提高了Pseudo-labels的质量;Thing-Class ImageNet Feature Distance Learning rate warmup促进了预训练的特征迁移
DAFormer代表了UDA的一个重大进步。它在GTA→Cityscapes改善了10.8 mIoU、Synthia→Cityscapes提升了5.4 mIoU。
1简介
对于语义分割,标注的成本特别高,因为每个像素都必须被标记。例如,标注一幅Cityscapes图片需要1.5小时,而在恶劣的天气条件下,甚至需要3.3小时。
解决这个问题的一个方法是使用合成数据进行训练。然而,常用的CNN对域迁移很敏感,从合成数据到真实数据的泛化能力较差。该问题在无监督域适应(UDA)中得到解决,通过将由源(合成)数据训练的网络适应于不访问目标标签的目标(真实)数据。
以前的UDA方法主要是使用带有ResNet或VGG Backbone的DeepLabV2或FCN8s网络架构来评估其贡献,以便与之前发表的作品相媲美。然而,即使他们最强大的架构(DeepLabV2+ResNet101)在有监督的语义分割领域也过时了。
例如,它在Cityscape上只能实现65 mIoU的监督性能,而最近的网络达到85 mIoU。由于存在较大的性能差距,使用过时的网络架构是否会限制UDA的整体性能,是否会误导UDA的基准测试进展?
为了回答这个问题,本文研究了网络体系结构对UDA的影响,设计了一个更复杂的体系结构,并通过一些简单但关键的训练策略成功地应用于UDA。单纯地为UDA使用更强大的网络架构可能是次最优的,因为它更容易对源域过拟合。
基于在UDA环境下评估的不同语义分割架构的研究,作者设计了DAFormer,一个为UDA量身定制的网络架构。它是基于最近的Transformer,因为Transformer已经被证明比主流的CNN更强大。
DAFormer它们与上下文感知的多级特征融合相结合,进一步提高了UDA的性能。DAFormer是第一个揭示Transformer在UDA语义分割方面的巨大潜力的工作。
由于更复杂和有能力的架构更容易适应不稳定和对源域过拟合,在这项工作中,引入了3个训练策略,以UDA解决这些问题。
首先,提出了罕见类抽样(RCS)来考虑源域的长尾分布,这阻碍了罕见类的学习,特别是在
UDA中,由于Self-training对常见类的确认偏差。通过频繁采样罕见类图像,网络可以更稳定地学习这些图像,提高了伪标签的质量,减少了确认偏差。其次,提出了一个Thing-Class ImageNet Feature Distance(FD),它从ImageNet特征中提取知识,以规范源训练。当源域仅限于特定类的几个实例(多样性较低)时,这尤其有用,因为它们的外观与目标域(域转移)不同。如果没有FD,这将导致学习缺乏表现力和特定于源领域的特性。当ImageNet特征被训练为事物类时,将FD限制为标记为事物类的图像区域。
最后,在
UDA中引入了学习率warm up。通过在早期训练中线性提高学习率到预期值,学习过程稳定,从ImageNet预处理训练的特征可以更好地迁移到语义分割。

如图1所示,DAFormer在很大程度上优于以前的方法,这支持了作者的假设,即网络架构和适当的训练策略对UDA发挥了重要作用。在GTA→cityscape上,将mIoU从57.5提高到68.3及以上,在Synthia→Cityscape上,将mIoU从55.5提高到60.9。
特别是DAFormer学习了以前的方法难以处理的更难的类。例如,在GTA→Cityscapes模式中,将火车等级从16 mIoU提高到65 mIoU,卡车等级从49 mIoU提高到75 mIoU,公共汽车等级从59 mIoU提高到78 mIoU。
总体而言,DAFormer代表了UDA的一个重大进步。本文的框架可以在16小时内在单个RTX 2080 Ti GPU上进行一个阶段的训练,这与之前的方法(如ProDA)相比简化了它的训练时间,后者需要在4个V100 GPU上训练1个阶段需要很多天。
2相关方法
2.1 语义分割
自从引入卷积神经网络用于语义分割以来,它们一直占据着该领域的主导地位。通常,语义分割网络遵循编码器-解码器的设计。为了克服瓶颈处空间分辨率低的问题,提出了skip connections、dilated convolutions或resolution preserving的架构等补救措施。进一步的改进是通过利用上下文信息实现的,例如使用pyramid pooling或注意力模块。
受基于注意力的Transformer在自然语言处理方面的成功启发,它们被用于图像分类和语义分割,取得了最先进的结果。
对于图像分类,
CNN对分布偏移(如图像损坏、对抗性噪声或域偏移)很敏感。最近的研究表明,在这些特性方面,Transformer比CNN更健壮。CNN关注的是纹理,而Transformer更关注的是物体的形状,它更类似于人类的视觉。在语义分割方面,采用了
ASPP和跳跃式连接来提高鲁棒性。此外,基于Transformer的架构提高了基于CNN网络的鲁棒性。
2.2 无监督域自适应(UDA)
UDA方法可分为Adversarial-training方法和Self-training方法。
Adversarial-training方法的目的是在GAN框架中,在输入、特征、输出或patch级别对齐源和目标域的分布。对鉴别器使用多个尺度或类别信息可以优化比对。
在Self-training中,利用目标域的伪标签对网络进行训练。大多数的UDA方法都是离线预计算伪标签,训练模型,然后重复这个过程。或者,伪标签可以在训练期间在线计算。为了避免训练不稳定性,采用了基于数据增强或域混淆的伪标签原型或一致性正则化方法。
几种方法还包括Adversarial-training和Self-training相结合,训练与辅助任务相结合,或进行测试时间UDA。
数据集通常是不平衡的,并且遵循长尾分布,这使得模型偏向于学习公共类。解决这个问题的策略有重采样、损失重加权和迁移学习。在UDA中,采用重加权和类平衡采样进行图像分类。
本文将类平衡抽样从分类扩展到语义切分,并提出了罕见类抽样,该抽样解决了罕见类和常见类在单个语义切分样本中同时出现的问题。此外,还证明了重采样对于UDA训练Transformer特别有效。
Li等人已经证明,从旧任务中提取的知识可以作为新任务的正则化器。作者也将这一思想应用于Self-training中,实验表明它对Transformer特别有效,并通过将特征距离限制在图像区域中进行改进,如ImageNet主要标记事物类。
3本文方法
3.1 Self-Training (ST) for UDA
在UDA中,神经网络为了实现良好的性能,对于目标图像,训练使用源域图像和One-hot标签,没有使用目标标签。
在源域上使用分类交叉熵(CE)损失来训练网络
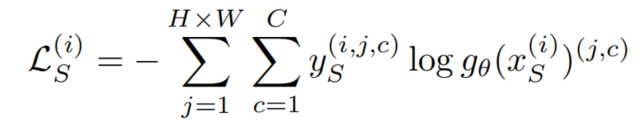
由于该网络不能很好地推广到目标域,通常导致对目标图像的性能较低。
为了解决这一领域的差距,人们提出了几种策略,可以分为Adversarial-training方法和Self-training方法。在这项工作中使用Self-training,因为Adversarial-training训练不稳定。为了更好地将知识从源域转移到目标域,Self-training方法使用教师网络来为目标域数据生成伪标签:
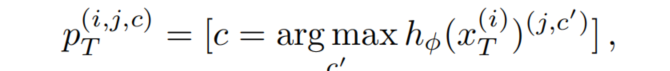
其中[·]为艾弗森括号。请注意,教师网络没有梯度反向传播。另外,对伪标签进行质量/置信度估计。在这里,使用像素超过阈值τ的最大softmax概率:
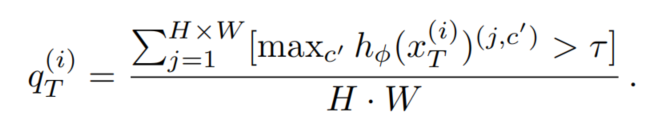
伪标签及其质量估计被用于在目标域上额外训练网络:
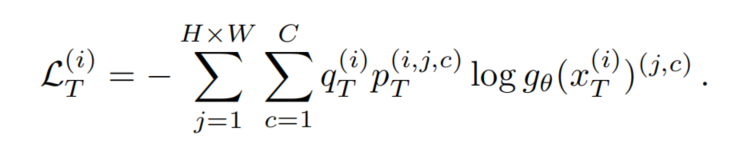
这些伪标签可以通过在线或离线来生成。本文选择了在线Self-training。在在线Self-training中,在训练期间基于进行更新。通常,权值被设置为每个训练步骤t后的权值的指数移动平均值,以增加预测的稳定性:
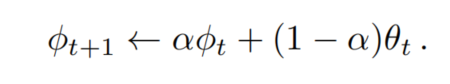
如果学生网络训练增强目标数据,教师网络使用非增强目标数据半监督学习和无监督域适应生成伪标签,Self-training方法已经被证明是特别有效的。在这项工作中,遵循DACS和使用颜色抖动,高斯模糊,类Mix数据增强学习更多的领域稳健的特性。
3.2 DAFormer Network Architecture
以前的UDA方法大多使用(简化的)DeepLabV2网络架构来评估,都是一些比较老的方法。因此,作者自行为UDA设计了一个定制的网络体系结构,不仅可以实现良好的监督性能,还可以提供良好的领域适应能力。
对于编码器,目标是建立一个强大而又稳健的网络架构。假设稳健性是为了实现良好的域自适应性能的一个重要特性,因为它可以促进域不变特征的学习。
基于最近的发现,Transformer是UDA的一个很好的选择,因为它们满足这些标准。虽然Transformer的Self-Attention和卷积都是加权和,但它们的权值计算方式不同:在CNN中,权值在训练中学习,但在测试中固定;在Self-Attention机制中,权值是基于每对Token之间的相似性或亲和性动态计算的。因此,Self-Attention机制中的自相似性操作提供了可能比卷积操作更具有自适应性和通用性的建模手段。
作者遵循Mix Transformer(MiT)的设计,它是为语义分割量身定制的。图像被分成4×4大小的小块(而不是ViT中的16×16),以便为语义分割保留更多的细节。为了应对高特征分辨率,在Self-Attention块中使用了序列约简。Transformer编码器设计用于产生多级特征映射。下采样是通过overlapping patch merging实现的,这样可以保持局部连续性。
以前使用Transformer Backbone进行语义分割的工作通常只利用局部信息作为解码器。相反,作者建议在解码器中利用额外的上下文信息,因为这已被证明可以增加语义分割的稳健性,这是UDA的一个有用属性。
DAFormer不只是考虑瓶颈特性的上下文信息,而是使用来自不同编码器级别的特性的上下文信息,因为附加的早期特征为高分辨率的语义分割提供了有价值的low-level信息,这也可以提供重要的上下文信息。
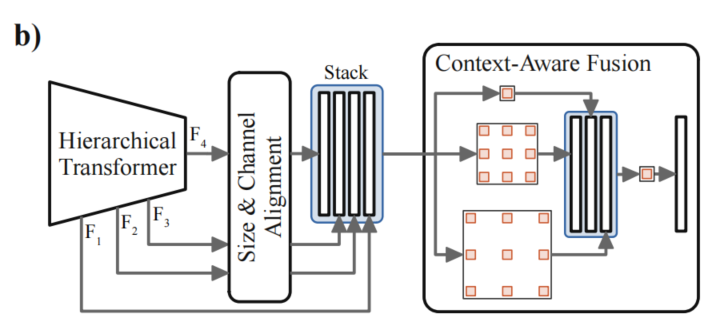
DAFormer解码器的架构如图2(b)所示。在进行特征融合之前,通过1×1卷积将每个嵌入到相同数量的通道中,并对特征进行双线性上采样至大小,然后拼接。
对于上下文感知的特征融合,使用多个具有不同扩张率的并行3×3深度可分离卷积和一个1×1卷积来融合它们,类似于ASPP,但没有全局平均池化。
与最初使用ASPP相比,不仅将其应用于瓶颈特性,而且将其用于融合所有堆叠的多层次特性。深度可分离卷积具有比常规卷积参数少的优点,可以减少对源域的过拟合。
3.3 Training Strategies for UDA
为UDA训练一个更强大的架构的一个挑战是对源域的过拟合。为了解决这个问题,引入了3种策略来稳定和规范UDA训练:
罕见类采样 Thing-Class ImageNet特征距离 学习率Warmup
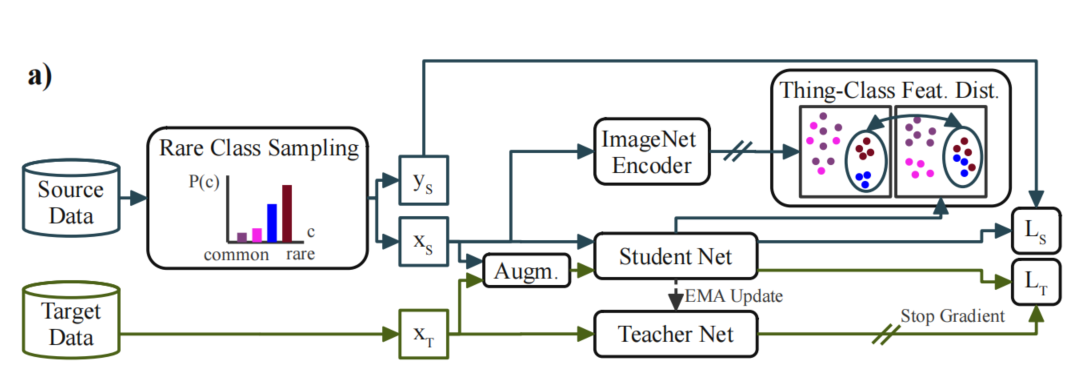
总体UDA框架如图2(a)所示。
1、罕见类采样
尽管DAFormer能够在困难类上获得比其他架构更好的性能,但作者观察到,源数据集中罕见的类的UDA性能在不同运行中存在显著差异。根据数据采样顺序的随机种子,这些类是在训练的不同迭代中学习的。在训练中学习的类越晚,在训练结束时的表现越差。
作者假设,如果由于随机性,含有罕见类的相关样本在训练中出现较晚,网络才开始学习它们,更重要的是,很有可能这个网络已经学会了对普通类别的强烈偏爱,使得用很少的样本“重新学习”新概念变得困难。
为了解决这个问题,作者提出了罕见类采样(RCS)。它经常从源领域对具有罕见类的图像进行采样,以便更好地、更早地学习它们。源数据集中每个c类的频率可以根据类像素的个数来计算:
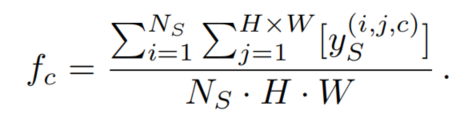
某一类c的采样概率P(c)被定义为其频率的函数:
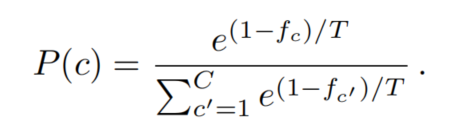
因此,频率越小的类,其抽样概率越高。T控制着分布的平滑度。T越高,分布越均匀;T越低,分布越集中在小的稀有类上。
2、Thing-Class ImageNet特征距离
通常,语义分割模型用ImageNet分类的权重初始化。考虑到ImageNet还包含来自一些相关的高级语义类的图像,UDA经常难以区分这些类,假设ImageNet特征可以提供除通常的预训练之外的有用监督。特别是,作者观察到DAFormer网络能够在训练开始时分割一些类,但在几百个训练步骤后就会失去监督效果。
因此,假设ImageNet预训练的有用特征被LS破坏,并且模型对合成源数据的过拟合。
为了避免这一问题,基于语义分割UDA模型的瓶颈特征和ImageNet模型的瓶颈特征的特征距离(FD)对模型进行规范化:
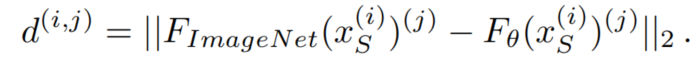
然而,ImageNet模型主要训练对象类(具有明确形状的对象,如汽车或斑马),而不是对象类(无定形的背景区域,如道路或天空)。因此,只计算包含由二进制Mask 描述的事物类的图像区域的:
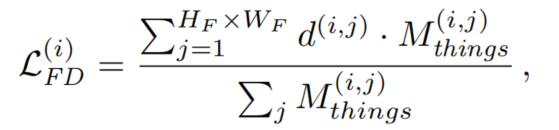
这个Mask是由 downscaled label 得到的:
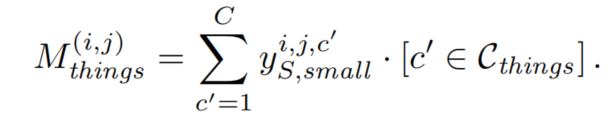
为了将标签降采样到瓶颈特征大小,对每个类通道应用patch size为的平均池化,当一个类超过比率r时,则该类将被保留:
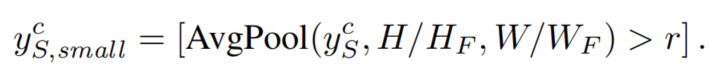
这确保了只有包含主导物类的瓶颈特征像素才被考虑为特征距离。
总体UDA loss L是各loss分量的加权和:
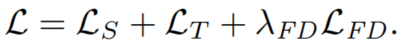
3、学习率Warmup
线性Warmup学习率开始训练已经成功地用于训练网络和Transformer,因为它通过避免一个大的自适应学习率方差改善了网络泛化。作者最近在UDA中引入了学习率Warmup系统。假设这对UDA来说特别重要,因为来自ImageNet预训练的特征会剥夺网络对真实领域的有用监督。
在Warmup到迭代期间,迭代的学习速率设置为。
4实验
4.1 SOTA 对比
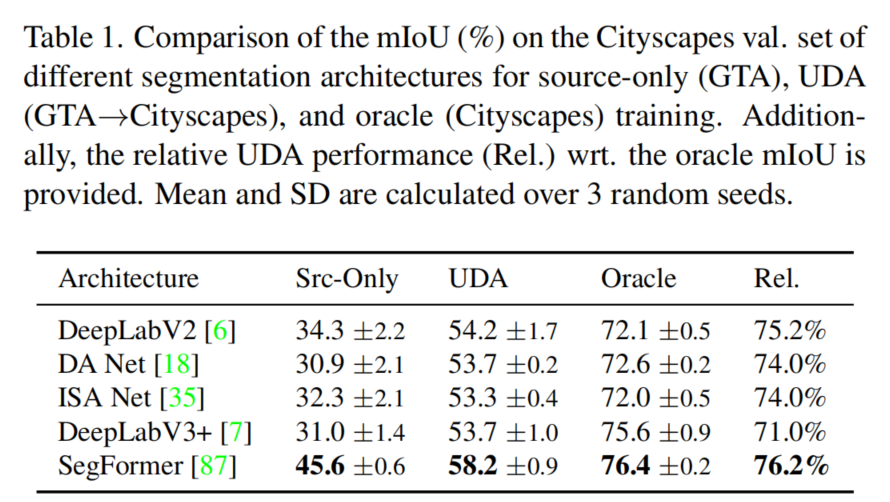
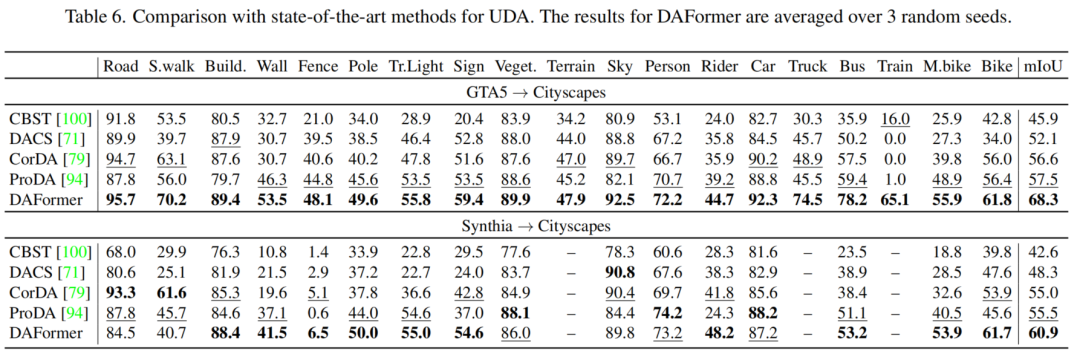
UDA上的大部分工作使用DeepLabV2和ResNet-101 Backbone。有趣的是,更高的Oracle性能并不一定会提高UDA性能,这在表1中的DeepLabV3+中可以看到。一般来说,研究的最新CNN架构并没有提供比DeepLabV2更好的UDA性能。
然而,作者确定了基于Transformer的SegFormer是一个强大的UDA架构。它显著提高了仅使用源代码/UDA/oracle训练的mIoU,从34.3/54.2/72.1增加到45.6/58.2/76.4。作者认为,特别是更好的SegFormer的域泛化(仅源训练)对于提高UDA性能是有价值的。
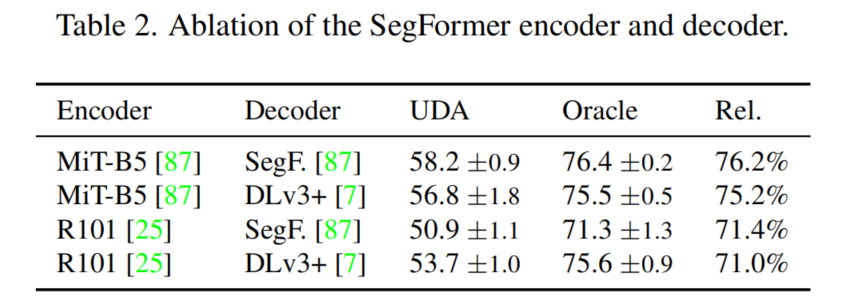
表2显示,SegFormer的轻量级MLP解码器相对于UDA性能略高于较重的DLv3+解码器(76.2% vs . 75.2%)。然而,对于良好的UDA性能的关键贡献来自于Transformer MiT编码器。用ResNet101编码器替换它会导致UDA性能的显著下降。尽管由于ResNet编码器的感受野变小,oracle的性能也会下降,但对于UDA来说,相对性能从76.2%下降到71.4%是不成比例的。
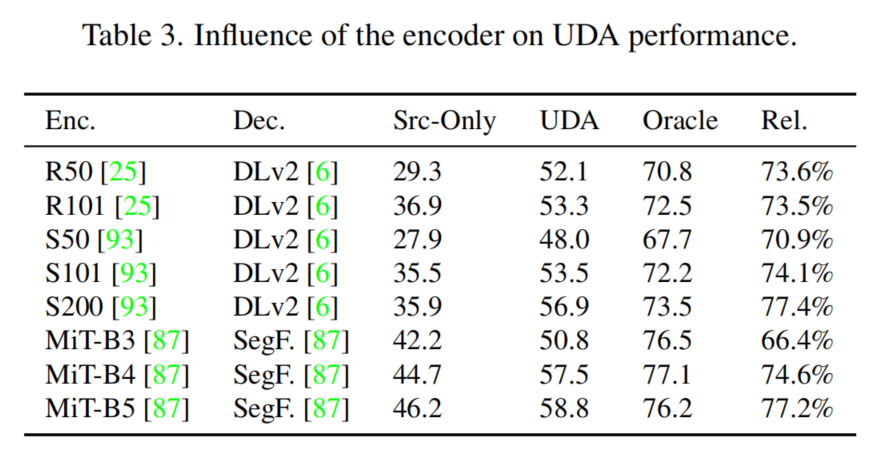
因此,进一步研究了编码器架构对UDA性能的影响。在表3中比较了不同的编码器的设计和大小。可以看出,更深层次的模型可以实现更好的source-only和相对性能,这表明更深层次的模型可以更好地概括/适应新的领域。这一观察结果与关于网络架构的鲁棒性的研究结果相一致。
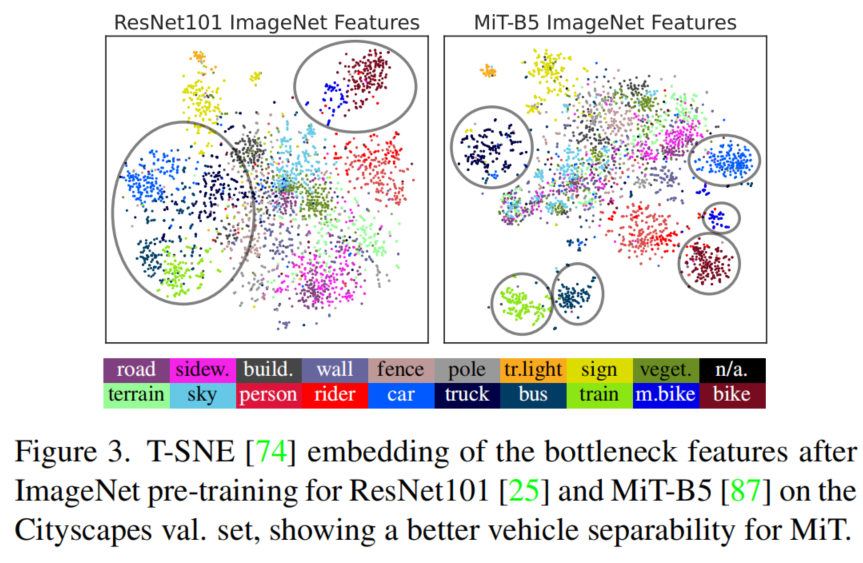
与CNN编码器相比,MiT编码器从源域训练推广到目标域。总的来说,最好的UDA mIoU是由MiT-B5编码器实现的。为了深入了解改进的泛化效果,图3可视化了目标域的ImageNet特征。尽管ResNet对stuff-classes的结构稍微好一些,但MiT在分离语义上相似的类(例如所有车辆类)方面表现出色,而这些类通常特别难以适应。
4.2 消融实验
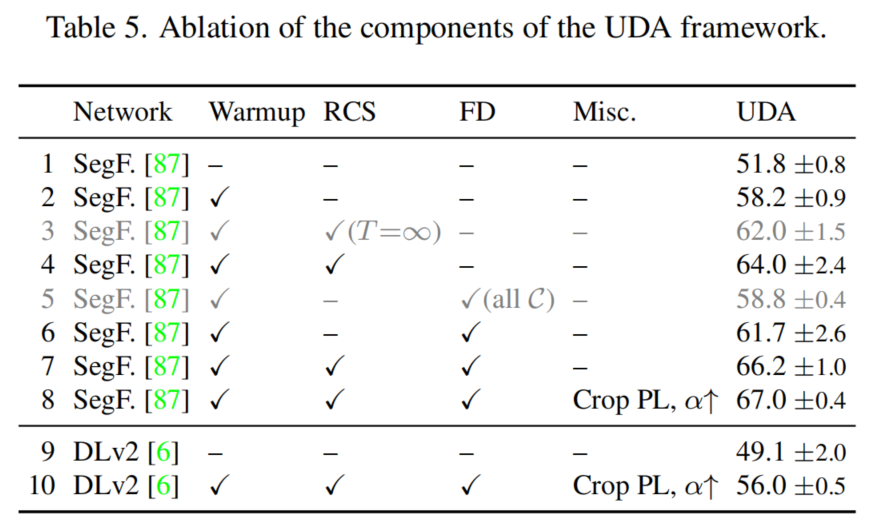
1、Learning Rate Warmup
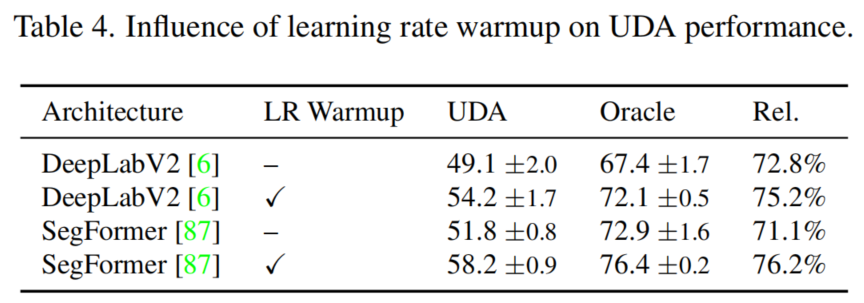
从表4可以看出,学习率Warmup显著提高了UDA和oracle的性能。
2、Rare Class Sampling (RCS)
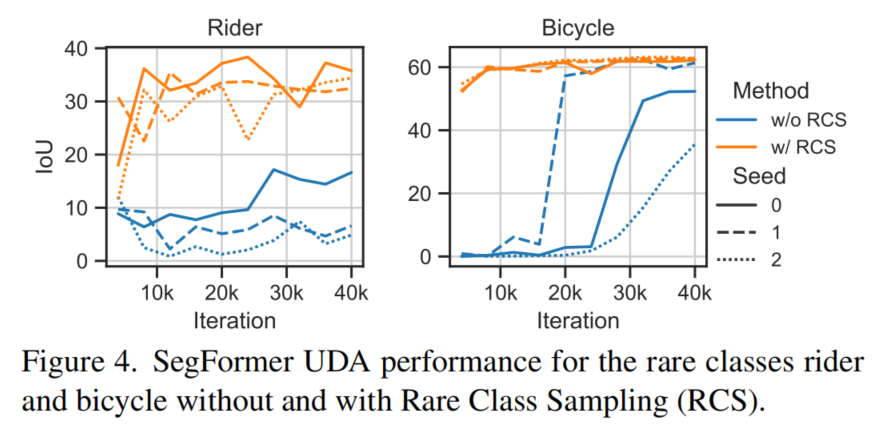
当为UDA训练SegFormer时,观察到一些类的性能依赖于数据抽样的随机种子,如图4中的蓝色IoU曲线所示。源数据集中受影响的类没有充分表示。有趣的是,对于不同的种子,自行车类的IoU在不同的迭代中开始增加。
假设这是由抽样顺序造成的,特别是当相关的稀有类被抽样时。此外,IoU越晚开始训练,该类的最后IoU就越差,这可能是由于在早期迭代中积累的自训练的确认偏差。因此,对于UDA,尽早学习稀有的类别尤为重要。
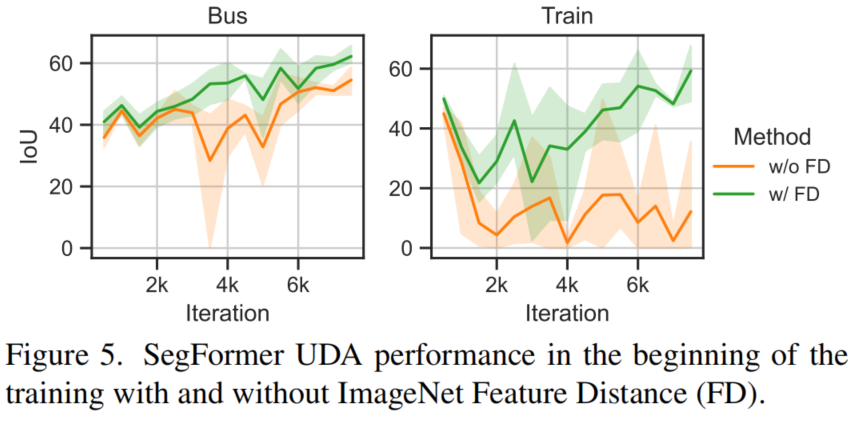
为了解决这个问题,所提出的RCS增加了罕见类的抽样概率。图4(橙色)显示RCS导致骑行者/自行车的mIoU更早增加,最终mIoU更高,与数据抽样随机种子无关。这证实了假设,即(早期)对稀有类的抽样对于正确学习这些类很重要。
3、Thing-Class ImageNet Feature Distance(FD)

虽然RCS提高了性能,但事物类的性能仍然可以进一步提高,因为在UDA训练后,一些在ImageNet特性中分离得相当好的对象类(见图3右)混合在一起。在调查早期训练期间的IoU时(见图5橙色),观察到列车Class的早期性能下降。
假设强大的MiT编码器过度适合于合成域。当使用建议的FD进行正则化训练时,避免了性能下降(见图5绿色)。其他困难的Class,如公共汽车,摩托车和自行车受益于正规化(图6中的第2行和第4行)。总体而言,UDA的性能提高了3.5mIoU(表5中的第2行和第6行).
注意,仅将FD只应用于经过ImageNet特性训练的类,对其良好的性能很重要(cf。第5行和第6行)。
4.3 DAFormer Decoder

5参考
[1].DAFormer6推荐阅读
ResNet50 文艺复兴 | ViT 原作者让 ResNet50 精度达到82.8%,完美起飞!!!
全新Backbone | 模拟CNN创造更具效率的Self-Attention
探究Integral Pose Regression性能不足的原因
长按扫描下方二维码添加小助手。
可以一起讨论遇到的问题
声明:转载请说明出处
扫描下方二维码关注【集智书童】公众号,获取更多实践项目源码和论文解读,非常期待你我的相遇,让我们以梦为马,砥砺前行!
