
使用多尺度注意力进行语义分割
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
本文转自AI公园
作者:Andrew Tao and Karan Sapra
编译:ronghuaiyang
来自NVIDIA的SOTA语义分割文章,代码开源。
关注公众号后后台回复“多尺度语义分割”,下载打包好的论文和代码。
有一项重要的技术,通常用于自动驾驶、医学成像,甚至缩放虚拟背景:“语义分割。这是将图像中的像素标记为属于N类中的一个(N是任意数量的类)的过程,这些类可以是像汽车、道路、人或树这样的东西。就医学图像而言,类别对应于不同的器官或解剖结构。
NVIDIA Research正在研究语义分割,因为它是一项广泛适用的技术。我们还相信,改进语义分割的技术也可能有助于改进许多其他密集预测任务,如光流预测(预测物体的运动),图像超分辨率,等等。
我们开发出一种新方法的语义分割方法,在两个共同的基准:Cityscapes和Mapillary Vistas上达到了SOTA的结果。。IOU是交并比,是描述语义分割预测精度的度量。
在Cityscapes中,这种方法在测试集上达到了85.4 IOU,考虑到这些分数之间的接近程度,这相对于其他方法来说是一个相当大的进步。
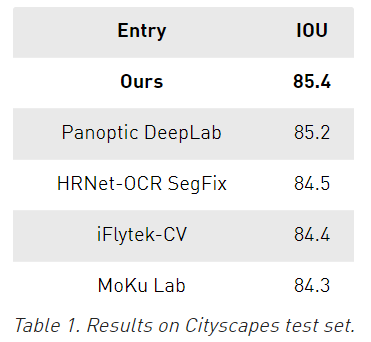
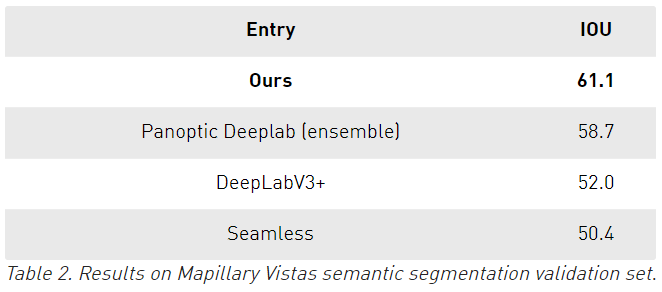
在Mapillary上,使用单个模型在验证集上达到了61.1 IOU,相比于其他的使用了模型集成最优结果是58.7。
预测结果

研究过程
为了开发这种新方法,我们考虑了图像的哪些特定区域需要改进。图2显示了当前语义分割模型的两种最大的失败模式:细节错误和类混淆。

在这个例子中,存在两个问题:细节和类混淆。
第一张图片中邮箱的细节在2倍尺度的预测中得到了最好的分辨,但在0.5倍尺度下的分辨很差。 与中值分割相比,在0.5x尺度下对道路的粗预测要比在2x尺度下更好,在2x尺度下存在类混淆。
我们的解决方案在这两个问题上的性能都能好得多,类混淆几乎没有发生,对细节的预测也更加平滑和一致。
在确定了这些错误模式之后,团队试验了许多不同的策略,包括不同的网络主干(例如,WiderResnet-38、EfficientNet-B4、xcepase -71),以及不同的分割解码器(例如,DeeperLab)。我们决定采用HRNet作为网络主干,RMI作为主要的损失函数。
HRNet已经被证明非常适合计算机视觉任务,因为它保持了比以前的网络WiderResnet38高2倍分辨率的表示。RMI损失提供了一种无需诉诸于条件随机场之类的东西就能获得结构性损失的方法。HRNet和RMI损失都有助于解决细节和类混淆。
为了进一步解决主要的错误模式,我们创新了两种方法:多尺度注意力和自动标记。
多尺度注意力
在计算机视觉模型中,通常采用多尺度推理的方法来获得最佳的结果。多尺度图像在网络中运行,并将结果使用平均池化组合起来。
使用平均池化作为一个组合策略,将所有尺度视为同等重要。然而,精细的细节通常在较高的尺度上被最好地预测,大的物体在较低的尺度上被更好地预测,在较低的尺度上,网络的感受野能够更好地理解场景。
学习如何在像素级结合多尺度预测可以帮助解决这个问题。之前就有关于这一策略的研究,Chen等人的Attention to Scale是最接近的。在这个方法中,同时学习所有尺度的注意力。我们将其称为显式方法,如下图所示。

受Chen方法的启发,我们提出了一个多尺度的注意力模型,该模型也学会了预测一个密集的mask,从而将多尺度的预测结合在一起。但是在这个方法中,我们学习了一个相对的注意力mask,用于在一个尺度和下一个更高的尺度之间进行注意力,如图4所示。我们将其称为层次方法。
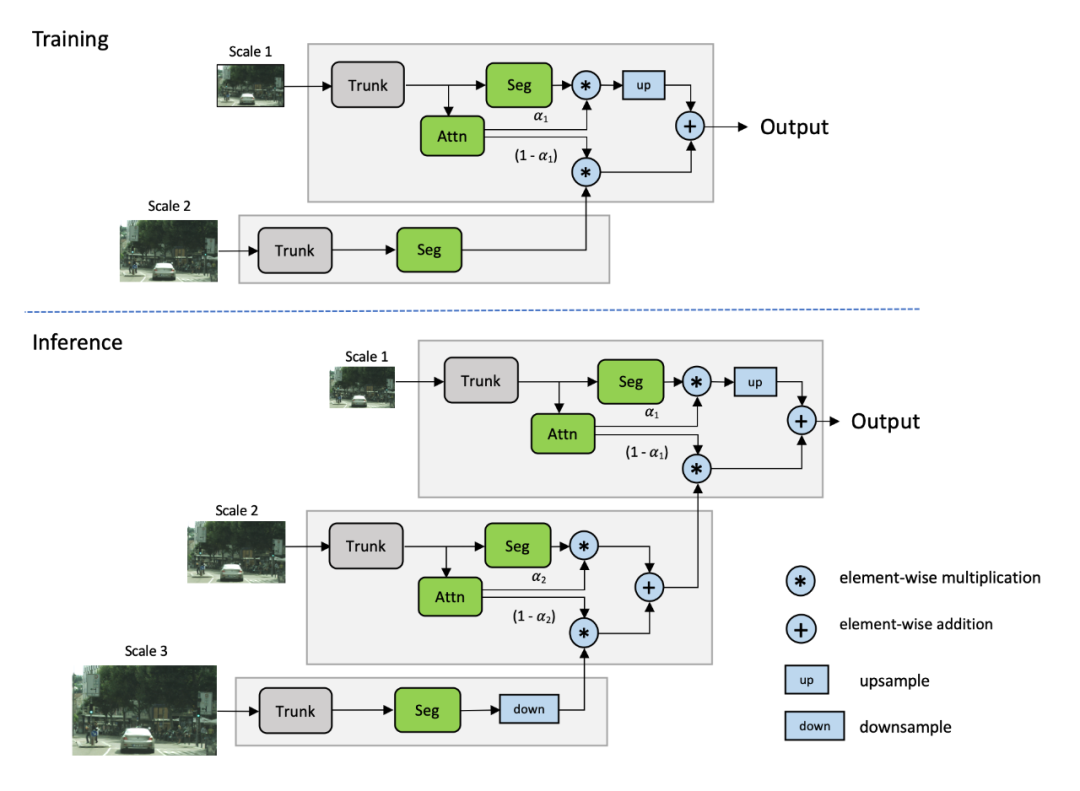
这种方法的主要好处如下:
理论训练成本比Chen方法降低了约4x。 训练只在成对的尺度上进行,推理是灵活的,可以在任意数量的尺度上进行。
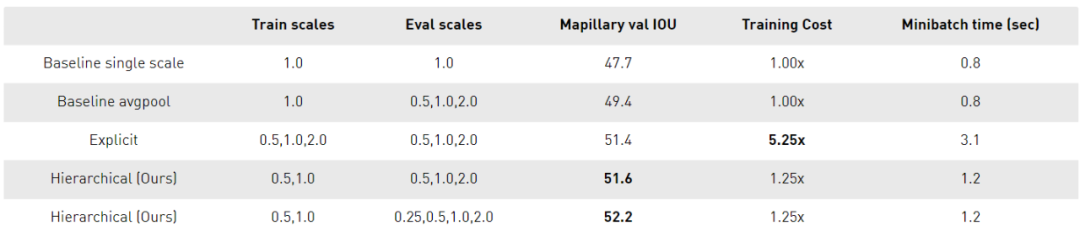
图5显示了我们的方法的一些例子,以及已学习的注意力mask。对于左边图片中邮箱的细节,我们很少关注0.5x的预测,但是对2.0x尺度的预测非常关注。相反,对于右侧图像中非常大的道路/隔离带区域,注意力机制学会最大程度地利用较低的尺度(0.5x),以及更少地利用错误的2.0x预测。

自动标记
改进城市景观语义分割结果的一种常用方法是利用大量的粗标记数据。这个数据大约是基线精标注数据的7倍。过去Cityscapes上的SOTA方法会使用粗标注标签,或者使用粗标注的数据对网络进行预训练,或者将其与细标注数据混合使用。
然而,粗标注的标签是一个挑战,因为它们是有噪声的和不精确的。ground truth粗标签如图6所示为“原始粗标签”。

受最近工作的启发,我们将自动标注作为一种方法,以产生更丰富的标签,以填补ground truth粗标签的标签空白。我们生成的自动标签显示了比基线粗标签更好的细节,如图6所示。我们认为,通过填补长尾类的数据分布空白,这有助于泛化。
使用自动标记的朴素方法,例如使用来自教师网络的多类概率来指导学生,将在磁盘空间上花费非常大的代价。为20,000张横跨19个类的、分辨率都为1920×1080的粗图像生成标签大约需要2tb的存储空间。这么大的代价最大的影响将是降低训练成绩。
我们使用硬阈值方法而不是软阈值方法来将生成的标签占用空间从2TB大大减少到600mb。在这个方法中,教师预测概率 > 0.5是有效的,较低概率的预测被视为“忽略”类。表4显示了将粗数据添加到细数据和使用融合后的数据集训练新学生的好处。


最后的细节
该模型使用PyTorch框架在4个DGX节点上对fp16张量核进行自动混合精度训练。
论文:https://arxiv.org/abs/2005.10821
代码:https://github.com/nvidia/semanic-segmentation

英文原文:https://developer.nvidia.com/blog/using-multi-scale-attention-for-semantic-segmentation/

交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~