
SETR:基于视觉 Transformer 的语义分割模型
Visual Transformer
Author:louwill
Machine Learning Lab
自从Transformer在视觉领域大火之后,一系列下游视觉任务应用研究也随之多了起来。基于视觉Transformer的语义分割正是ViT应用最多的一个经典视觉任务之一。
在视觉Transformer介入语义分割之前,基于深度学习的语义分割是被以UNet为代表的CNN模型主导的。基于编解码结构的FCN/UNet模型成为语义分割领域最主流的模型范式。本文介绍基于ViT的语义分割的第一个代表模型——SEgementation TRansformer (SETR),提出以纯Transformer结构的编码器来代替CNN编码器,改变现有的语义分割模型架构。
提出SETR的这篇论文为Rethinking Semantic Segmentation from a Sequence-to-Sequence Perspective with Transformers,发表于2021年3月份,是由复旦和腾讯优图联合提出的一个基于ViT的新型架构的语义分割模型。
SETR的基本结构
SETR的整体模型结构如图1所示。
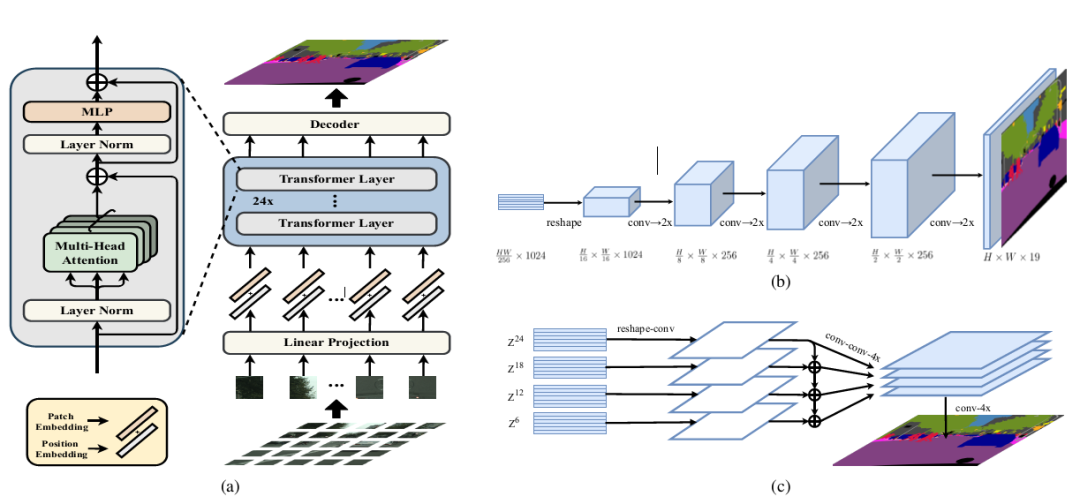
图1 SETR结构
SETR的核心架构仍然是Encoder-Decoder的结构,只不过相比于传统的以CNN为主导的编码器结构,SETR用Transformer来进行替代。图1中(a)图是SETR的整体架构,可以看到编码器是由纯Transformer层构成。
SETR编码器流程跟作为backbone的ViT模型较为一致。先对输入图像做分块处理,然后对每个图像分块做块嵌入并加上位置编码,这个过程就将图像转换为向量序列。之后就是Transformer block,里面包括24个Transformer层,每个Transformer层都是由MSA+MLP+Layer Norm+残差连接组成。
SETR的一个特色在于解码器的设计。将2D的编码器输出向量转换为3D特征图之后,论文中给SETR设计了三种解码器上采样方法。第一种就是最原始的上采样,论文中叫Naive upsampling,通过简单的1x1卷积加上双线性插值来实现图像像素恢复。这种上采样方法简称为SETR-Naive。
重点是第二种和第三种解码器设计。第二种解码器设计叫渐进式上采样 (Progressive UPsampling),作者认为一步到位式的上采样可能会产生大量的噪声,采样渐进式的上采样则可以最大程度上缓解这种问题。渐进式的上采样在于,每一次上采样只恢复上一步图像的2倍,这样经过4次操作就可以回复原始图像。这种解码设计简称为SETR-PUP,如图1中的(b)图所示。第三种解码设计为多层次特征加总 (Multi-Level feature Aggregation, MLA),这种设计跟特征金字塔网络类似,如图1中(c)图所示。
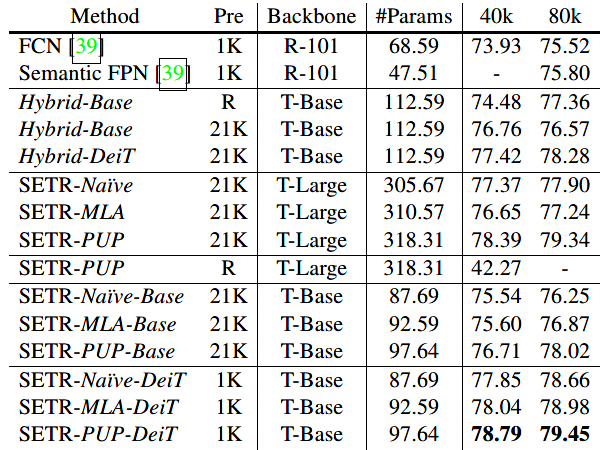
表1是基于不同预训练和backbone的SETR变体模型的参数量和效果展示。
表1 SETR模型细节
SETR训练与实验
SETR在主流的语义分割数据集上都做了大量实验,包括Cityscapes、ADE20K和PASCAL Context等数据集。SETR在多个数据集上都取得了SOTA的结果,如表2和表3所示。
表2 SETR在ADE20K上的表现
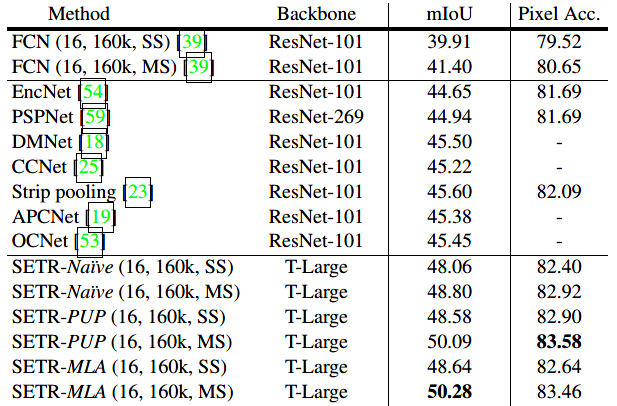
表3 SETR在PASCAL Context上的表现

图2是SETR在ADE20K数据集上的分割效果,左侧列为FCN分割效果,右侧列为SETR的分割效果。可以看到,SETR分割效果要明显优于FCN。

总结
总体而言,SETR的几个重要贡献如下:
为基于FCN/UNet等CNN分割模型的语义分割提供了不同的思路,即基于序列的图像分割视角。Transformer作为这种序列模型的一个实现实例,SETR充分的探索了ViT的分割能力。
设计了三种不同的解码器上采样方法,深入探索了不同的上采样设计的像素恢复效果。
实验证明了基于Transformer的语义分割能够学习到超过FCN等CNN结构的语义表征。
但SETR也有诸多不足。跟ViT一样,SETR要取得好的结果,对预训练和数据集大小都有较大的依赖性。
参考资料:
Zheng S, Lu J, Zhao H, et al. Rethinking semantic segmentation from a sequence-to-sequence perspective with transformers[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 6881-6890.
往期精彩:
ViT:视觉Transformer backbone网络ViT论文与代码详解
求个在看