
通过对比对象掩码建议的无监督语义分割
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


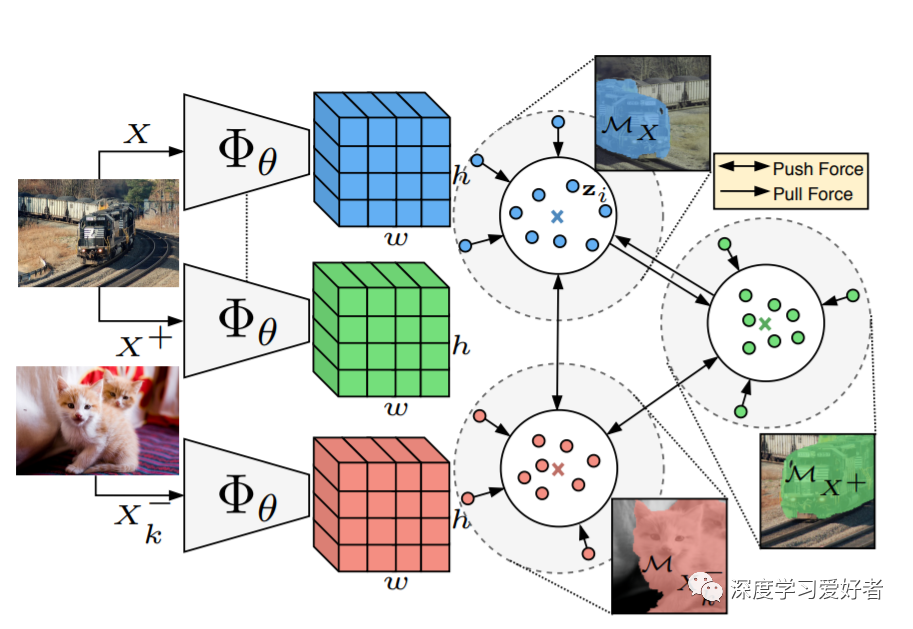
能够在没有监督的情况下学习密集的图像语义表示是计算机视觉中的一个重要问题。然而,尽管意义重大,这个问题仍然没有得到充分的探讨,除了一些例外,即考虑在具有狭窄视觉域的小尺度数据集上进行无监督语义分割。在本文中,作者首次尝试解决传统上用于有监督情况的数据集上的问题。为了实现这一目标,作者引入了一个新的两步学习框架,该框架采用了一个预先确定的对比优化目标来学习像素嵌入。这标志着与依赖代理任务或端到端集群的现有工作有很大的不同。此外,作者讨论了拥有一个包含对象或其部分信息的先验的重要性,并讨论了以无监督方式获得这样一个先验的几种可能性。大量的实验评价表明,所提出的方法比现有的方法具有关键的优势。首先,学习到的像素嵌入可以使用K-Means直接聚类到语义组中。其次,该方法可以作为一种有效的无监督的语义分割任务前训练。特别是,当使用PASCAL上1%的标记示例来优化学习到的表示时,作者比监督ImageNet预训练的性能高出7.1% mIoU
代码链接:https://github.com/wvangansbeke/Unsupervised-Semantic-Segmentation
作者的贡献有:
(1)作者提出了一个两步的无监督语义分割框架,这标志着与最近依赖代理任务或端到端聚类的工作有很大的偏差。
(2)在PASCAL上,作者学习到的像素嵌入可以使用K-Means直接聚类到语义组中。请注意,这是一个非常具有挑战性的场景,在之前的作品中从未被探索过。
(3)最后,当对学习到的表示进行微调时,作者在ImageNet上报告了经过监督的预训练后的更好性能。这些结果表明,就学前训练而言,关注密集表征的学习是一个值得关注的研究方向。这与主流的基于图像级特征学习的预训练策略相反。

作者分别在DUTS和MSRA数据集上训练有监督(中间)和无监督(底部)显著性估计量。作者对帕斯卡进行预测。

在PASCAL上使用1%的标记数据进行微调后的定性比较。作者在ImageNet(中间)或作者的方法(底部)上使用监督前训练来在微调之前初始化权重。
作者提出了一个一般的两步框架来处理无监督语义分割。此外,作者还讨论了拥有表达物体或其部分信息的先验的重要性。实验结果表明,获得的像素嵌入具有几个有趣的特性,即直接聚类、半监督微调和迁移学习能力。最后,作者的框架允许几个可能的扩展:
1.可选择的物体掩模建议方法,以解决与使用显著物体掩模相关的限制。更具体地说,它将有助于提取更细粒度的图像区域的共享像素所有权优先适用。这可以在几个方面对结果有好处,例如,作者可以增加掩模建议的数量,识别物体的部分和学习非显著物体的表示。
2.该方法可以推广到其他密集预测任务,如语义实例分割。例如,像素嵌入可以与对象掩码提议机制相结合来预测语义实例。
3.一种层次策略可以被探索来建模像素关系在多个尺度。
鉴于作者框架的可行性,作者相信这些是有希望的研究方向。
论文链接:https://arxiv.org/pdf/2102.06191.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~