
【深度学习】利用CNN来检测伪造图像
随着像Facebook和Instagram这样的社交网络服务的出现,在过去十年中产生的图像数据量有一个巨大增加。使用图像(和视频)等处理软件GNU Gimp,Adobe Photoshop创建修改过的图像和视频是Facebook等互联网公司的主要关注点。
这些图片是假新闻的主要来源,经常被用于恶意的方式,如煽动暴徒。在对可疑图像采取行动之前,我们必须核实其真实性。IEEE信息取证和安全技术委员会(IFS-TC)发起了一项检测和定位取证挑战第一次图像取证挑战2013年解决了这个问题。他们提供了一个开放的数字图像数据集,其中包括在不同光照条件下拍摄的图像,以及使用如下算法生成的伪造图像:
内容感知的填充和补丁匹配(用于复制/粘贴)
内容感知修复(用于复制/粘贴和拼接)
克隆图章(复制/粘贴)
缝刻(图像重定向)
修复(受损部分的图像重建-复制/粘贴的特殊情况)
Alpha Matting(用于拼接)
第一阶段要求参与的团队将图像分类为伪造的或原始的(从不操纵)。
第二阶段则要求他们检测/定位伪造图像中的伪造区域。
在人工智能的前深度学习时代,图像处理研究人员用于设计手工特征,解决一般的图像处理问题,特别是图像分类问题。一个这样的例子是Sobel内核用于边缘检测。之前使用的图像取证工具可以分为5类,即
基于像素的技术,检测像素级引入的统计异常。
利用特定有损压缩方案引入的统计相关性的基于格式的技术。
利用相机镜头、传感器或芯片后处理引入的伪影的基于相机的技术。
基于物理学的技术,明确地建模和检测物理对象、光和相机之间的三维交互作用中的异常。
基于几何的技术,使世界上的对象和他们的位置相对于相机的测量。
几乎所有这些技术都利用了图像的基于内容的特征,即图像中呈现的视觉信息。CNN的是灵感来自视觉皮层。从技术上讲,这些网络被设计用来提取对分类有意义的特征,即那些使损失函数最小化的特征。通过梯度下降法学习网络参数-核权值,从而从输入给网络的图像中生成最有区别的特征。然后,这些特征被提供给一个完全连接的层,该层执行最后的分类任务。
在观察了一些伪造的图像后,很明显,人类视觉皮层找到伪造的区域是可能的。因此CNN是这个工作的完美的深度学习模型。如果人类的视觉皮层能够探测到它,那么这个专为这项任务而设计的网络肯定会更强大。
在进入数据集概述之前,需要明确使用的术语
伪造图像:使用两种最常见的操作操作即复制/粘贴和图像拼接来处理/篡改的图像。
原始图像:没有被操纵的图像,除了根据比赛规则将所有图像调整为标准尺寸。
图像拼接:拼接操作可以将人的图像组合在一起,给建筑物加门,给停车场加树,加车等等。拼接的图像也可以包含复制/粘贴操作产生的部分。接收拼接部分的图像称为“主机”图像。与宿主映像拼接在一起的部分称为“外星人”。
可以找到第一阶段和第二阶段的整个数据集在这里。对于这个项目,我们将只使用火车集。它包含2个目录—一个包含假图像及其对应的掩码,另一个包含原始图像。伪图像的掩码是描述伪图像拼接区域的黑白(非灰度)图像。蒙版中的黑色像素表示在源图像中进行操作以获得伪造图像的区域,特别是拼接区域。
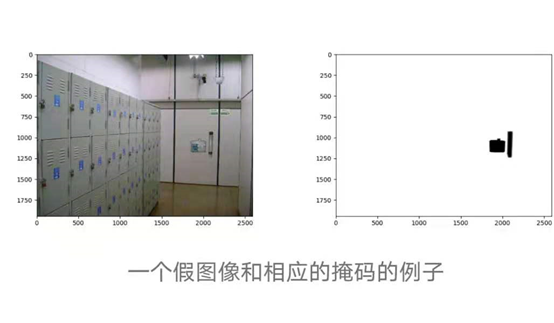
该数据集由1050张原始图像和450张伪造图像组成。彩色图像通常是三个通道的图像,红、绿、蓝各一个通道,但有时也会出现黄色的第四个通道。我们的数据集中的图像是1、3和4通道图像的混合。在观察一些1通道图像即灰度图像后。
挑战设置者有意添加这些图像,因为他们想要解决这样的噪声。尽管一些蓝色的图像可以是晴朗天空的图像。因此,其中一些被包括在内,而另一些则作为噪声被丢弃。来看看四个频道的图像——它们也没有任何有用的信息。它们只是填充0值的像素网格。因此,清理后的原始数据集包含大约1025张RGB图像。
假图像是3和4通道图像的混合,但是,没有一个是噪声的。相应的掩模是1、3和4通道图像的混合。我们将使用的特征提取只需要从蒙版的一个通道获取信息。因此,我们的伪造图像语料库有450个赝品。接下来,我们做了一个火车测试分离,以保留20%的1475张照片的最终测试。
数据集目前的状态不适合训练模型。它必须转换成一种状态,这种状态非常适合于手头的任务,即在像素级检测由于锻造操作而引入的异常。把思想从在这里,我们设计了以下方法来从给定的数据创建相关的图像。
对于每一个假图像,我们都有一个对应的掩模。我们使用该掩模沿拼接区域的边界对假图像进行采样,以确保图像的伪造部分和未伪造部分都至少有25%的贡献。这些样本将具有只有在假图像中才会出现的可区分的边界。这些界限将由我们设计的CNN来学习。由于mask的3个通道都包含相同的信息(不同像素的图像的假部分),所以我们只需要1个通道来提取样本。
为了使图像的边界更加清晰,将灰度图像转换为二值图像首先进行阈值(实施OpenCV),然后用高斯滤波器去噪。在此操作之后,采样仅仅是在伪图像中移动一个64×64窗口(8步),在对应的掩模中计数0值(黑色)像素,如果值在一定的间隔内进行采样。
In [29]:binaries=[]for grayscale in x_train_masks:blur = cv2.GaussianBlur(grayscale,(5,5),0)ret,th = cv2.threshold(blur,0,255,cv2.THRESH_BINARY+cv2.THRESH_OTSU)binaries.append(th)In [56]:~binaries[28]Out[56]:array([[0, 0, 0, ..., 0, 0, 0],[],[],...,[],[],[]], dtype=uint8)
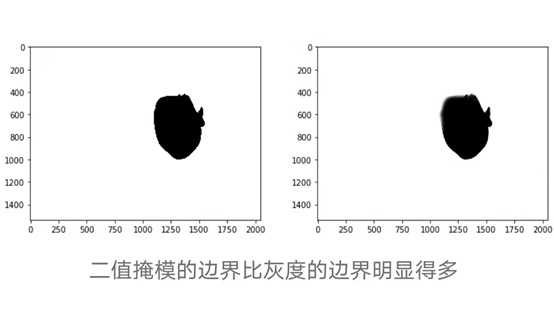
采样后,我们从假图像中得到175,119个64×64补丁。为了生成0标记(原始)补丁,我们从真实图像中采样了大致相同的数量。最后,我们有350,728个补丁,它们被分成了多个序列和交叉验证集。
现在我们有了一个大的高质量输入图像数据集。现在是试验各种CNN架构的时候了。
我们尝试的第一个建筑灵感来自于最初的建筑研究论文. 他们的输入图像大小为128×128×3,因此网络很大。因为我们有一半的空间大小,我们的网络也更小。这是第一个尝试的架构。
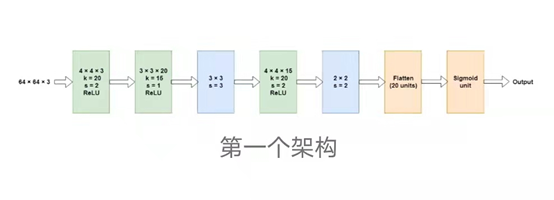
绿色的图层是卷积的,蓝色的是Max pool。该网络对150,000列样本(用于测试)和25,000验证样本进行了训练。该网络有8536个参数,与列车样本相比相对较少,因此避免了更激进的辍学的需要。在20个单位的平坦产量上应用了0.2的辍学率。我们使用缺省学习率(0.001)和beta_1, beta_2的Adam优化器。在大约___个时代之后,结果如下
列车精度:77.13%,列车损耗:0.4678
验证准确性:75.68%,验证损耗:0.5121
这些数字并不是很令人印象深刻,因为在2012年,CNN以巨大的优势击败了专家们经过多年研究开发的特色节目。然而,考虑到我们完全没有使用图像取证知识(像素统计和相关概念)来获得看不见的数据的___精度,这些数字也不是很糟糕。
因为这是一个CNN它击败了所有经典的机器学习算法ImageNet分类任务,为什么不利用这些强大的机器之一的工作来解决手边的问题呢?这是背后的想法转移学习. 简而言之,我们使用一个预训练模型的权重来解决我们的问题,这个模型可能是在一个更大的数据集上训练的,在解决它的问题时给出了更好的结果。换句话说,我们将一种模型的学习“转移”到我们自己的模型上。在我们的例子中,我们使用theVGG16在ImageNet数据集上训练,使我们的数据集中的图像矢量化。在这里,我们尝试了两种方法
使用VGG16输出的瓶颈特性,并在此基础上构建一个浅网络。
微调上面(1)中VGG16+Shallow模型的最后一个卷积层。
凭直觉,2给出的结果比1好得多。我们尝试了多种浅层网络架构,最终到达这里
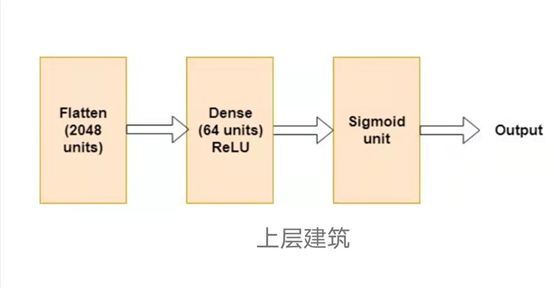
平坦层的输入是VGG16输出的瓶颈特征。这些是形状的张量(2×2×512),因为我们使用了64×64输入图像。
上面的架构给出了以下结果
列车精度83.18%,列车损耗0.3230
验证精度84.26%,验证损耗0.3833
我们使用Adam优化器进行训练,自定义学习率在每10个epoch后降低(除了在每批处理后由Adam定期更新)。
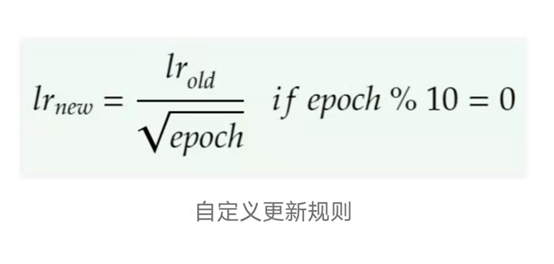
第二种方法需要微调最后一层。这里需要注意的重要一点是,为了进行微调,我们必须使用预先训练好的顶层模型。目标是稍微改变已经掌握的权重,以便更好地拟合数据。如果我们使用一些随机初始化的权值,轻微的变化不会对它们有任何好处,而大的变化会破坏学习到的卷积层的权值。我们还需要一个非常小的学习率来微调我们的模型(原因与上面提到的相同)。在这后,建议使用SGD优化器进行微调。然而,我们观察到亚当在这项任务上比SGD表现得更好。
微调模型得到以下结果
列车精度:99.16%,列车损耗:0.018
验证精度94.77%,验证损耗0.30
稍微过拟合的模型,可以通过使用更小的学习速率来补救(我们使用1e-6)。
除了VGG16,我们还尝试了ResNet50和VGG19模型在Image-Net数据集上预先训练的瓶颈特性。ResNet50的功能表现优于VGG16。VGG19的表现不是很令人满意。我们对ResNet50体系结构(最后一个卷积层)进行了微调,采用了与VGG16类似的方式,使用相同的学习率更新策略,在较小的过拟合问题下给出了更有希望的结果。
列车准确率:98.65%,列车损耗:0.048
验证精度:95.22%,验证损耗:0.18
为了从之前创建的测试集中采样图像,我们采用了与创建训练和交叉验证集类似的策略,即在边界处使用掩模采样假图像,并采样相同尺寸的相同数量的原始图像。我们使用经过微调的VGG16模型来预测这些补丁的标签,并给出了以下结果
测试精度:94.65%,测试损耗:0.31
另一方面,ResNet50给出了以下测试数据的结果
测试精度:95.09%,测试损耗:0.19
正如我们所见,我们的模型表现得很好。我们还有很多改进的余地。如果通过数据增强(剪切、调整大小、旋转和其他操作)可以生成更多的数据,或许我们可以对更多的SOTA网络层进行微调。
往期精彩回顾 本站qq群851320808,加入微信群请扫码: