
证件造假克星!基于深度学习的文档图像伪造攻击
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达

本文简要介绍2021年8月TIP录用论文“Deep Learning-based Forgery Attack on Document Images”的主要工作。该论文通过基于深度学习的技术提出了一种低成本的文档图像编辑算法,并通过一套网络设计策略解决了现有文本编辑算法在复杂字符和复杂背景上进行文本编辑的局限性。文档编辑的实际效果如下:
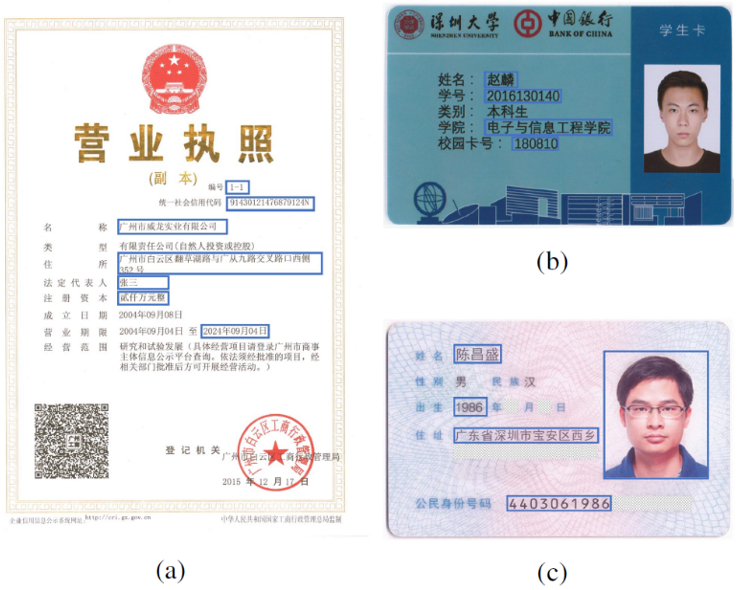
Fig. 1. Illustration of three types of document images processed by the proposed document forgery approach (ForgeNet). The edited regions are boxed out in blue.
一、研究背景
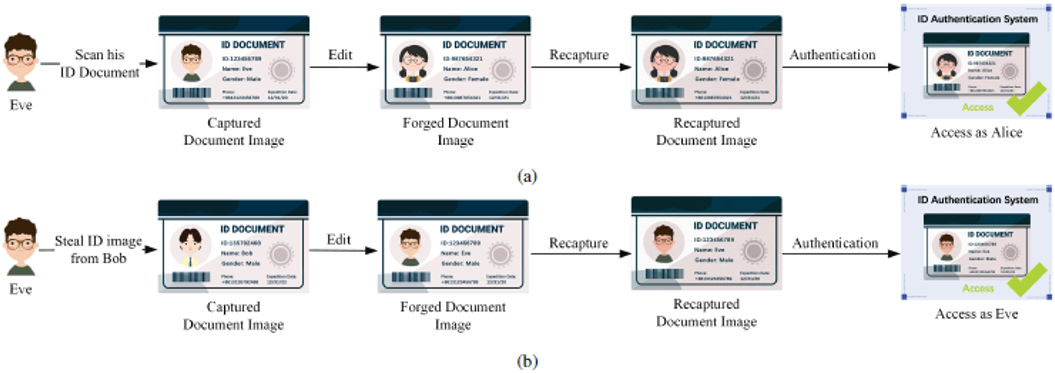
Fig. 2. Two representative forge-and-recapture attack scenarios. (a) The attacker scans his/her own identity document to obtain an identity document image and forges the document of a target identity to perform an impersonate attack. (b) The attacker steals an identity document image and forge his/her own document to obtain unauthorized access.
二、方法简述
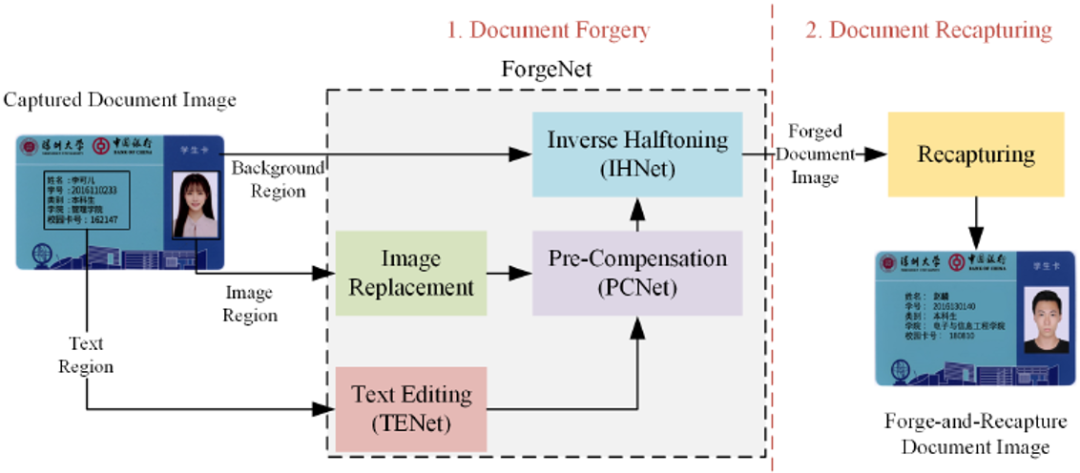
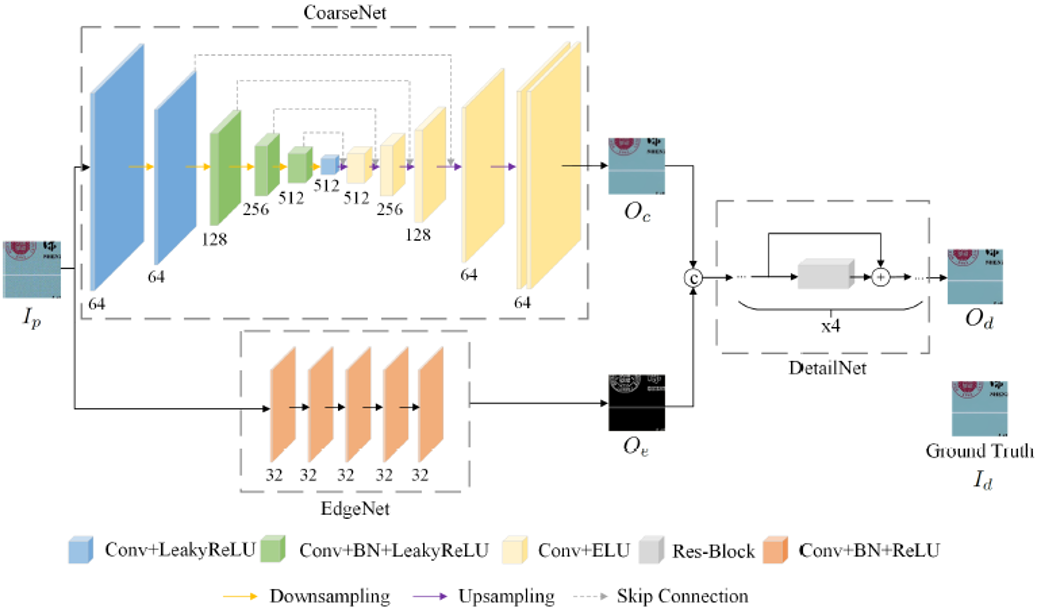
文档伪造攻击分为伪造(通过该论文提出的深度网络ForgeNet,网络框架见Fig. 3)和翻拍两个步骤。在伪造过程中,由成像设备获取的文档图像作为ForgeNet的输入。它被分为三个区域,即文本区域、图像区域和背景区域(不包括在前两类中的区域)。背景区域由反半色调模块(IHNet)处理,用以去除打印图像中的半色调点。图像区域中的原始照片被目标照片所取代,所得图像被输入到打印和扫描预补偿模块(PCNet)和IHNet。值得注意的是,PCNet引入颜色失真,并在编辑过的区域引入半色调图案,这样就可以补偿编辑过的区域和背景区域之间的差异。文本区域随后被输入到文本编辑模块(TENet)、PCNet和IHNet。经伪造网络处理后,这三个区域被拼接在一起,形成一个完整的文档图像。最后,伪造的文档图像由相机或扫描仪进行翻拍,完成伪造和翻拍攻击。
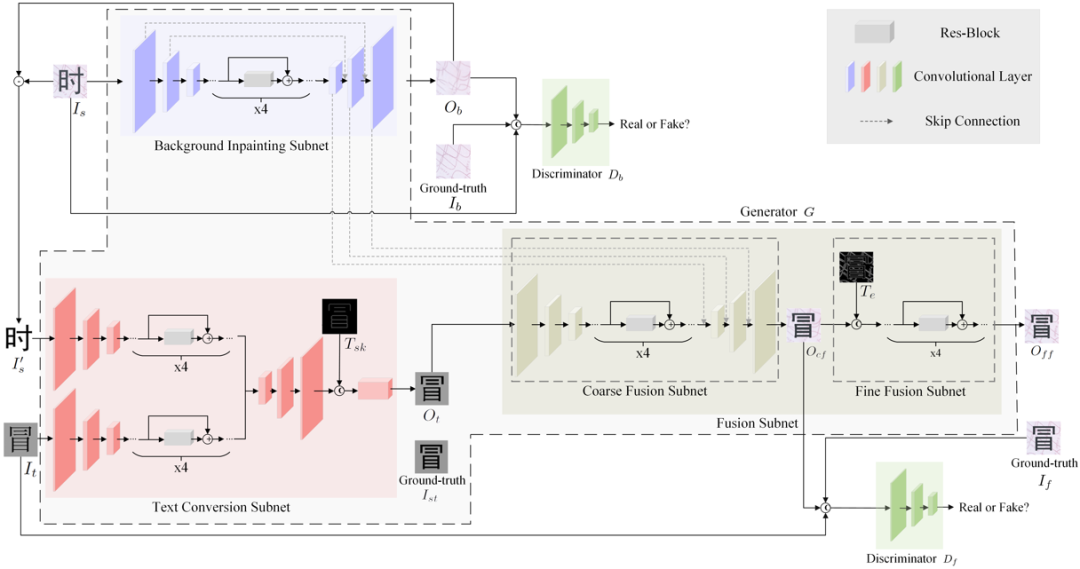
Fig. 4是文本编辑网络(TENet)的框架,它由三个子网组成。背景填充子网预测原始文本区域的背景内容并进行填充;文本转换子网将源图像 I_s 的文本内容替换为输入的目标文本图像,同时保留原始风格;融合子网将前两个子网的输出合并,得到带有目标文本和原始背景的图像。
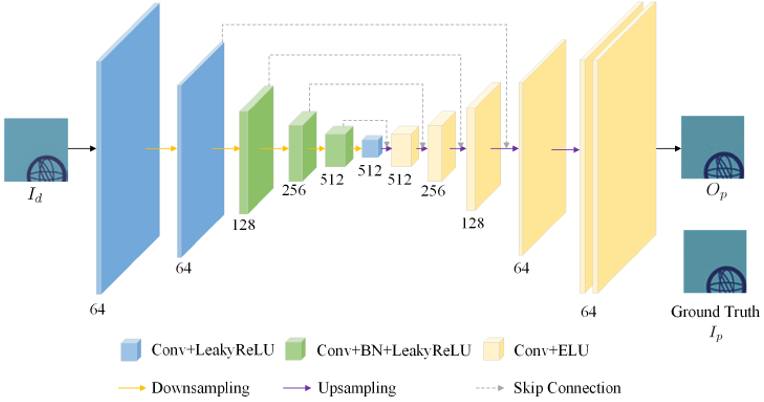
由于编辑过的文字区域没有打印和扫描的失真,但背景区域却经过了打印和扫描过程。如果直接拼接编辑过的文本和背景区域,二者边缘的伪影会很明显。所以,在合并不同区域之前,可以通过具有自动编码器结构的PCNet(网络结构如Fig. 5所示)来模拟打印-扫描过程中的强度变化和噪声,预先补偿文字区域的打印和扫描失真。
在打印和扫描后或由PCNet处理后,文档图像可以被视为半色调点的集群。如果图像在没有进行还原的情况下被重新打印和扫描,第一次和第二次打印过程中产生的半色调图案会相互干扰并引入混叠失真。为了提高伪造和翻拍攻击的成功率,在翻拍之前可以通过IHNet(网络结构如Fig. 6所示)去除伪造文档图像中的半色调图案。
三、主要实验结果及可视化效果
作者首先评估了TENet在合成字符数据集上的性能。由于SRNet [2]最初设计用于编辑场景图像中的英文字母和阿拉伯数字,应用于视觉翻译和增强现实上,它在结构复杂的汉字上表现不佳,尤其是在有复杂背景的文档中。所以作者通过对SRNet的网络结构进行调整,提出了文本编辑网络TENet。作者对TENet中不同于SRNet的组件进行了定性和定量的评估。SRNet和TENet的三个主要区别如下:1)对源图像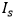 和背景填充子网的输出
和背景填充子网的输出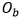 进行图像差分操作,获得没有背景的样式文本图像
进行图像差分操作,获得没有背景的样式文本图像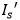 ;2)将输入到文本骨架器,所提取的骨架图像作为监督信息直接输入到文本转换子网;3)设计了一个考虑纹理连续性的精细融合子网取代通用的U-Net网络结构,用来融合不同的区域。
;2)将输入到文本骨架器,所提取的骨架图像作为监督信息直接输入到文本转换子网;3)设计了一个考虑纹理连续性的精细融合子网取代通用的U-Net网络结构,用来融合不同的区域。

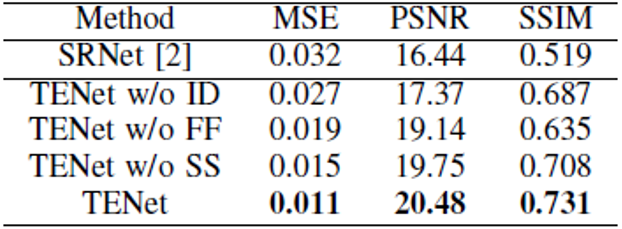
如Fig. 7 (c)-(e)中的视觉结果所示,如果去除这三个组件,都出现了不同程度的失真。图像差分、精细融合网络和骨架监督的重要性分别反映在字符、背景纹理和字符骨架的质量上。定量分析(见TABLE Ⅰ)和视觉实例都充分地证明了这三个组件的重要性。
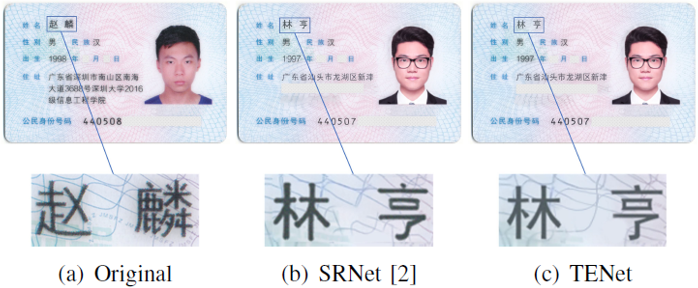
Fig. 8. Visual comparison on the identity card images.
此外,作者还选择具有复杂背景的身份证作为目标文档,通过单样本和一些数据增强策略训练文本伪造网络(ForgeNet)。如Fig. 8所示,ForgeNet只用单样本进行微调就取得了良好的伪造性能,而在SRNet编辑的图像中文字和背景都出现了失真。
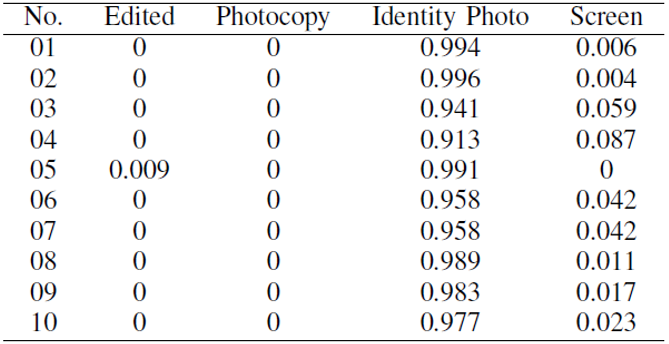
TABLE Ⅱ Identity document authentication under forge-and-recapture attack on MEGVII Face++ AI.
四、总结及讨论
五、论文资源
论文地址:https://arxiv.org/abs/2102.00653
参考文献
[1] Q. Yang, J. Huang, and W. Lin, “SwapText: Image based Texts Transfer in Scenes,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 14 700–14 709.
[2] L. Wu, C. Zhang, J. Liu, J. Han, J. Liu, E. Ding, and X. Bai, “Editing Text in the Wild,” in Proceedings of the 27th ACM International Conference on Multimedia, 2019, pp. 1500–1508.
[3] P. Roy, S. Bhattacharya, S. Ghosh, and U. Pal, “STEFANN: Scene text editor using font adaptive neural network,” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, 2020, pp. 13 228–13 237.
原文作者: Lin Zhao, Changsheng Chen, Jinwu Huang
免责声明:(1)本文仅代表撰稿者观点,撰稿者不一定是原文作者,其个人理解及总结不一定准确及全面,论文完整思想及论点应以原论文为准。(2)本文观点不代表本公众号立场。
交流群
欢迎加入公众号读者群一起和同行交流,目前有美颜、三维视觉、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群
个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021 在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
