
利用OpenCV和深度学习实现人脸检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|磐创AI

来源|Cver
前言:[1]:主要参考Face detection with OpenCV and deep learning这个英文教程,并作部分修改。[2]:亲测OpenCV3.3.0及以下版本,并没有face_detector示例,且不支持face_detector。为了避免折腾,还是建议使用OpenCV3.3.1及以上(如OpenCV3.4)。
1 face_detector简介
face_detector示例链接:
https://github.com/opencv/opencv/tree/master/samples/dnn/face_detector
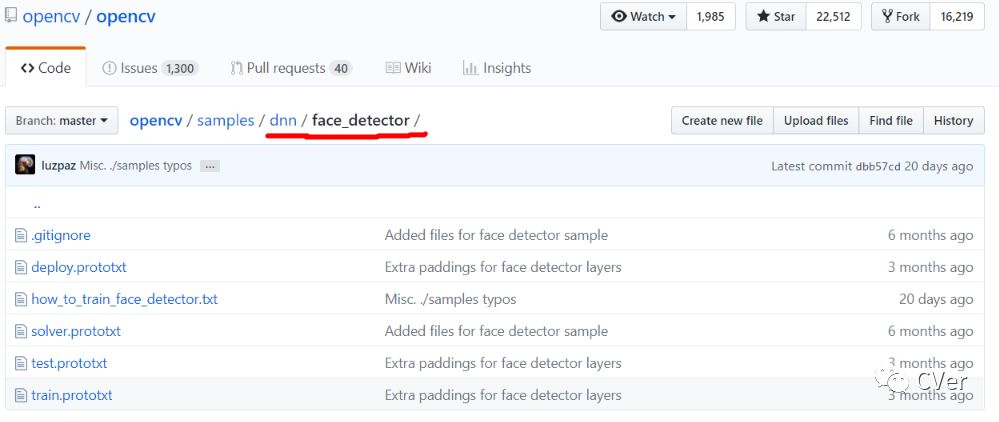
当电脑配置好OpenCV3.3.1或以上版本时,在opencv\samples\dnn也可以找到face_detector示例文件夹,如下图所示:
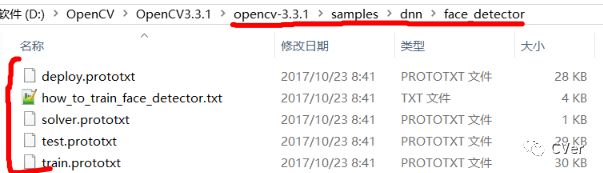
使用OpenCV的DNN模块以及Caffe模型,必须要有.prototxt和.caffemodel两种文件。但face_detector文件夹中,只有.prototxt一类文件,即缺少训练好的.caffemodel。.prototxt和.caffemodel的作用如下:
The .prototxt file(s) which define the model architecture (i.e., the layers themselves)
The .caffemodel file which contains the weights for the actual layers
face_detector文件分析:
deploy.prototxt:调用.caffemodel时的测试网络文件
how_to_train_face_detector.txt:如何使用自定义数据集来训练网络的说明
solver.prototxt:超参数文件
test.prototxt:测试网络文件
train.prototxt:训练网络文件
本教程直接使用训练好的.caffemodel来进行人脸检测,即只需要.caffemodel和deploy.prototxt两个文件。如果想要使用自己的数据集来训练网络,请参考"how_to_train_face_detector.txt"。
2 ResNet-10和SSD简介
本教程属于实战篇,故不深入介绍算法内容,若对ResNet和SSD感兴趣的同学,可以参考下述链接进行学习
[1]ResNet paper:https://arxiv.org/abs/1512.03385
[2]ResNet in Caffe:https://github.com/soeaver/caffe-model/tree/master/cls/resnet
[3]SSD paper:https://arxiv.org/abs/1512.02325
[4]SSD in Caffe:https://github.com/weiliu89/caffe/tree/ssd
3 .caffemodel下载
res10_300x300_ssd_iter_140000.caffemodel下载链接:https://anonfile.com/W7rdG4d0b1/face_detector.rar4 C++版本代码
4.1 图像中的人脸检测
对于OpenCV3.4版本,可直接使用opencv-3.4.1\samples\dnn文件夹中的resnet_ssd_face.cpp;
对于OpenCV3.3.1版本,可参考下述代码:
face_detector_image.cpp
1// Summary: 使用OpenCV3.3.1中的face_detector对图像进行人脸识别
2
3// Author: Amusi
4
5// Date: 2018-02-28
6
7#include <iostream>
8#include <opencv2/opencv.hpp>
9#include <opencv2/dnn.hpp>
10
11using namespace std;
12using namespace cv;
13using namespace cv::dnn;
14
15
16// Set the size of image and meanval
17const size_t inWidth = 300;
18const size_t inHeight = 300;
19const double inScaleFactor = 1.0;
20const Scalar meanVal(104.0, 177.0, 123.0);
21
22
23
24int main(int argc, char** argv)
25{
26 // Load image
27 Mat img;
28 // Use commandline
29#if 0
30
31 if (argc < 2)
32 {
33 cerr<< "please input "<< endl;
34 cerr << "[Format]face_detector_img.exe image.jpg"<< endl;
35 return -1;
36 }
37
38 img = imread(argv[1]);
39
40#else
41 // Not use commandline
42 img = imread("iron_chic.jpg");
43#endif
44
45
46
47 // Initialize Caffe network
48 float min_confidence = 0.5;
49
50 String modelConfiguration = "face_detector/deploy.prototxt";
51
52 String modelBinary = "face_detector/res10_300x300_ssd_iter_140000.caffemodel";
53
54 dnn::Net net = readNetFromCaffe(modelConfiguration, modelBinary);
55
56
57
58 if (net.empty())
59 {
60 cerr << "Can't load network by using the following files: " << endl;
61 cerr << "prototxt: " << modelConfiguration << endl;
62 cerr << "caffemodel: " << modelBinary << endl;
63 cerr << "Models are available here:" << endl;
64 cerr << "<OPENCV_SRC_DIR>/samples/dnn/face_detector" << endl;
65 cerr << "or here:" << endl;
66 cerr << "https://github.com/opencv/opencv/tree/master/samples/dnn/face_detector" << endl;
67 exit(-1);
68 }
69
70
71
72 // Prepare blob
73 Mat inputBlob = blobFromImage(img, inScaleFactor, Size(inWidth, inHeight), meanVal, false, false);
74 net.setInput(inputBlob, "data"); // set the network input
75 Mat detection = net.forward("detection_out"); // compute output
76
77 // Calculate and display time and frame rate
78
79 vector<double> layersTimings;
80 double freq = getTickFrequency() / 1000;
81 double time = net.getPerfProfile(layersTimings) / freq;
82
83 Mat detectionMat(detection.size[2], detection.size[3], CV_32F, detection.ptr<float>());
84 ostringstream ss;
85 ss << "FPS: " << 1000 / time << " ; time: " << time << "ms" << endl;
86
87 putText(img, ss.str(), Point(20,20), 0, 0.5, Scalar(0, 0, 255));
88
89 float confidenceThreshold = min_confidence;
90 for (int i = 0; i < detectionMat.rows; ++i)
91 {
92 // judge confidence
93 float confidence = detectionMat.at<float>(i, 2);
94
95 if (confidence > confidenceThreshold)
96 {
97 int xLeftBottom = static_cast<int>(detectionMat.at<float>(i, 3) * img.cols);
98 int yLeftBottom = static_cast<int>(detectionMat.at<float>(i, 4) * img.rows);
99 int xRightTop = static_cast<int>(detectionMat.at<float>(i, 5) * img.cols);
100 int yRightTop = static_cast<int>(detectionMat.at<float>(i, 6) * img.rows);
101 Rect object((int)xLeftBottom, (int)yLeftBottom, (int (xRightTop - xLeftBottom),
102 (int)(yRightTop - yLeftBottom));
103 rectangle(img, object, Scalar(0, 255, 0));
104 ss.str("");
105 ss << confidence;
106 String conf(ss.str());
107 String label = "Face: " + conf;
108 int baseLine = 0;
109 Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
110 rectangle(img, Rect(Point(xLeftBottom, yLeftBottom-labelSize.height),
111 Size(labelSize.width, labelSize.height + baseLine)),
112 Scalar(255, 255, 255), CV_FILLED);
113 putText(img, label, Point(xLeftBottom, yLeftBottom),
114 FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
115
116 }
117 }
118
119 namedWindow("Face Detection", WINDOW_NORMAL);
120 imshow("Face Detection", img);
121 waitKey(0);
122
123return 0;
124
125}
检测结果
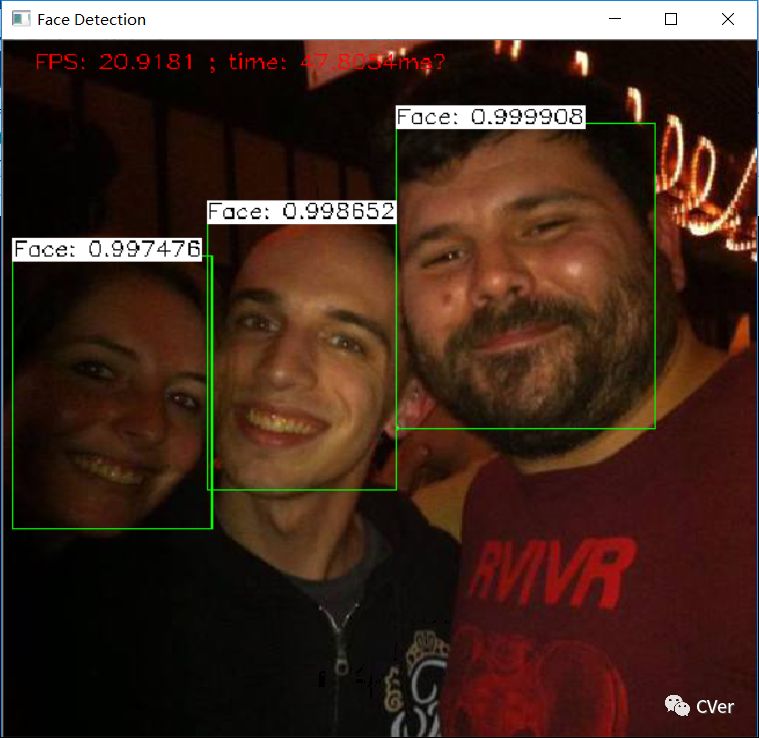
4.2 摄像头/视频中的人脸检测
face_detector_video.cpp
1// Summary: 使用OpenCV3.3.1中的face_detector
2// Author: Amusi
3// Date: 2018-02-28
4// Reference: http://blog.csdn.net/minstyrain/article/details/78907425
5
6#include <iostream>
7#include <cstdlib>
8#include <stdio.h>
9#include <opencv2/opencv.hpp>
10#include <opencv2/dnn.hpp>
11#include <opencv2/dnn/shape_utils.hpp>
12
13using namespace cv;
14using namespace cv::dnn;
15using namespace std;
16const size_t inWidth = 300;
17const size_t inHeight = 300;
18const double inScaleFactor = 1.0;
19const Scalar meanVal(104.0, 177.0, 123.0);
20
21int main(int argc, char** argv)
22{
23 float min_confidence = 0.5;
24 String modelConfiguration = "face_detector/deploy.prototxt";
25 String modelBinary = "face_detector/res10_300x300_ssd_iter_140000.caffemodel";
26 //! [Initialize network]
27 dnn::Net net = readNetFromCaffe(modelConfiguration, modelBinary);
28 //! [Initialize network]
29 if (net.empty())
30 {
31 cerr << "Can't load network by using the following files: " << endl;
32 cerr << "prototxt: " << modelConfiguration << endl;
33 cerr << "caffemodel: " << modelBinary << endl;
34 cerr << "Models are available here:" << endl;
35 cerr << "<OPENCV_SRC_DIR>/samples/dnn/face_detector" << endl;
36 cerr << "or here:" << endl;
37 cerr << "https://github.com/opencv/opencv/tree/master/samples/dnn/face_detector" << endl;
38 exit(-1);
39 }
40
41 VideoCapture cap(0);
42 if (!cap.isOpened())
43 {
44 cout << "Couldn't open camera : " << endl;
45 return -1;
46 }
47 for (;;)
48 {
49 Mat frame;
50 cap >> frame; // get a new frame from camera/video or read image
51
52 if (frame.empty())
53 {
54 waitKey();
55 break;
56 }
57
58 if (frame.channels() == 4)
59 cvtColor(frame, frame, COLOR_BGRA2BGR);
60
61 //! [Prepare blob]
62 Mat inputBlob = blobFromImage(frame, inScaleFactor,
63 Size(inWidth, inHeight), meanVal, false, false); //Convert Mat to batch of images
64 //! [Prepare blob]
65
66 //! [Set input blob]
67 net.setInput(inputBlob, "data"); //set the network input
68 //! [Set input blob]
69
70 //! [Make forward pass]
71 Mat detection = net.forward("detection_out"); //compute output
72 //! [Make forward pass]
73
74 vector<double> layersTimings;
75 double freq = getTickFrequency() / 1000;
76 double time = net.getPerfProfile(layersTimings) / freq;
77
78 Mat detectionMat(detection.size[2], detection.size[3], CV_32F, detection.ptr<float>());
79
80 ostringstream ss;
81 ss << "FPS: " << 1000 / time << " ; time: " << time << " ms";
82 putText(frame, ss.str(), Point(20, 20), 0, 0.5, Scalar(0, 0, 255));
83
84 float confidenceThreshold = min_confidence;
85 for (int i = 0; i < detectionMat.rows; i++)
86 {
87 float confidence = detectionMat.at<float>(i, 2);
88
89 if (confidence > confidenceThreshold)
90 {
91 int xLeftBottom = static_cast<int>(detectionMat.at<float>(i, 3) * frame.cols);
92 int yLeftBottom = static_cast<int>(detectionMat.at<float>(i, 4) * frame.rows);
93 int xRightTop = static_cast<int>(detectionMat.at<float>(i, 5) * frame.cols);
94 int yRightTop = static_cast<int>(detectionMat.at<float>(i, 6) * frame.rows);
95
96 Rect object((int)xLeftBottom, (int)yLeftBottom,
97 (int)(xRightTop - xLeftBottom),
98 (int)(yRightTop - yLeftBottom));
99
100 rectangle(frame, object, Scalar(0, 255, 0));
101
102 ss.str("");
103 ss << confidence;
104 String conf(ss.str());
105 String label = "Face: " + conf;
106 int baseLine = 0;
107 Size labelSize = getTextSize(label, FONT_HERSHEY_SIMPLEX, 0.5, 1, &baseLine);
108 rectangle(frame, Rect(Point(xLeftBottom, yLeftBottom - labelSize.height),
109 Size(labelSize.width, labelSize.height + baseLine)),
110 Scalar(255, 255, 255), CV_FILLED);
111 putText(frame, label, Point(xLeftBottom, yLeftBottom),
112 FONT_HERSHEY_SIMPLEX, 0.5, Scalar(0, 0, 0));
113 }
114 }
115 cv::imshow("detections", frame);
116 if (waitKey(1) >= 0) break;
117 }
118 return 0;
119}
检测结果
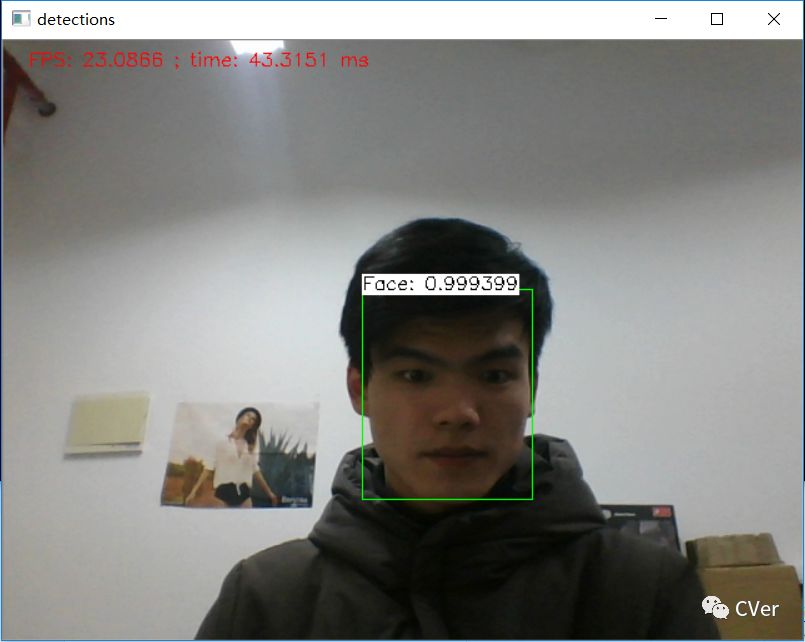
5 Python版本代码
最简单安装Python版的OpenCV方法
pip install opencv-contrib-python
对于OpenCV3.4版本,可直接使用opencv-3.4.1\samples\dnn文件夹中的resnet_ssd_face_python.py;
对于OpenCV3.3.1版本,可参考下述代码(自己写的):
5.1 图像中的人脸检测
detect_faces.py
1# USAGE
2# python detect_faces.py --image rooster.jpg --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel
3
4# import the necessary packages
5import numpy as np
6import argparse
7import cv2
8
9# construct the argument parse and parse the arguments
10ap = argparse.ArgumentParser()
11ap.add_argument("-i", "--image", required=True,
12 help="path to input image")
13ap.add_argument("-p", "--prototxt", required=True,
14 help="path to Caffe 'deploy' prototxt file")
15ap.add_argument("-m", "--model", required=True,
16 help="path to Caffe pre-trained model")
17ap.add_argument("-c", "--confidence", type=float, default=0.5,
18 help="minimum probability to filter weak detections")
19args = vars(ap.parse_args())
20
21# load our serialized model from disk
22print("[INFO] loading model...")
23net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
24
25# load the input image and construct an input blob for the image
26# by resizing to a fixed 300x300 pixels and then normalizing it
27image = cv2.imread(args["image"])
28(h, w) = image.shape[:2]
29blob = cv2.dnn.blobFromImage(cv2.resize(image, (300, 300)), 1.0,
30 (300, 300), (104.0, 177.0, 123.0))
31
32# pass the blob through the network and obtain the detections and
33# predictions
34print("[INFO] computing object detections...")
35net.setInput(blob)
36detections = net.forward()
37
38# loop over the detections
39for i in range(0, detections.shape[2]):
40 # extract the confidence (i.e., probability) associated with the
41 # prediction
42 confidence = detections[0, 0, i, 2]
43
44 # filter out weak detections by ensuring the `confidence` is
45 # greater than the minimum confidence
46 if confidence > args["confidence"]:
47 # compute the (x, y)-coordinates of the bounding box for the
48 # object
49 box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
50 (startX, startY, endX, endY) = box.astype("int")
51
52 # draw the bounding box of the face along with the associated
53 # probability
54 text = "{:.2f}%".format(confidence * 100)
55 y = startY - 10 if startY - 10 > 10 else startY + 10
56 cv2.rectangle(image, (startX, startY), (endX, endY),
57 (0, 0, 255), 2)
58 cv2.putText(image, text, (startX, y),
59 cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
60
61# show the output image
62cv2.imshow("Output", image)
63cv2.waitKey(0)
打开cmd命令提示符,切换至路径下,输入下述命令:
python detect_faces.py --image rooster.jpg --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel
检测结果

python detect_faces.py --image iron_chic.jpg --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel
检测结果
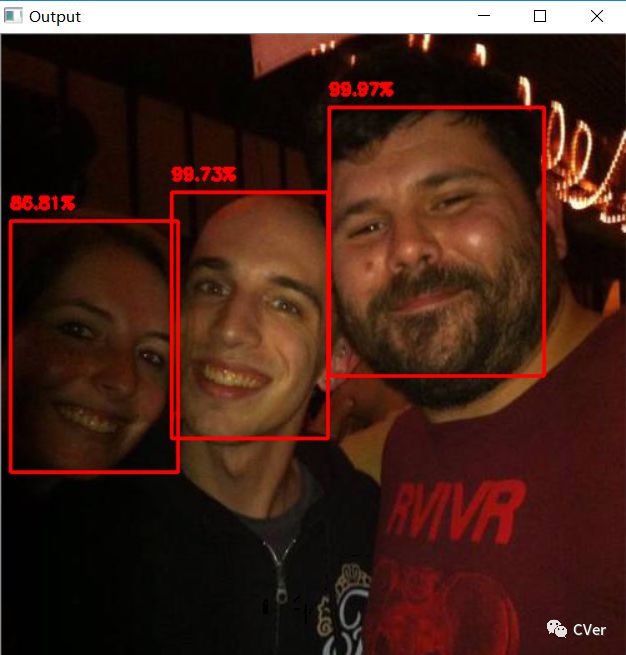
5.2 摄像头/视频中的人脸检测
detect_faces_video.py
1# USAGE
2# python detect_faces_video.py --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel
3
4# import the necessary packages
5from imutils.video import VideoStream
6import numpy as np
7import argparse
8import imutils
9import time
10import cv2
11
12# construct the argument parse and parse the arguments
13ap = argparse.ArgumentParser()
14ap.add_argument("-p", "--prototxt", required=True,
15 help="path to Caffe 'deploy' prototxt file")
16ap.add_argument("-m", "--model", required=True,
17 help="path to Caffe pre-trained model")
18ap.add_argument("-c", "--confidence", type=float, default=0.5,
19 help="minimum probability to filter weak detections")
20args = vars(ap.parse_args())
21
22# load our serialized model from disk
23print("[INFO] loading model...")
24net = cv2.dnn.readNetFromCaffe(args["prototxt"], args["model"])
25
26# initialize the video stream and allow the cammera sensor to warmup
27print("[INFO] starting video stream...")
28vs = VideoStream(src=0).start()
29time.sleep(2.0)
30
31# loop over the frames from the video stream
32while True:
33 # grab the frame from the threaded video stream and resize it
34 # to have a maximum width of 400 pixels
35 frame = vs.read()
36 frame = imutils.resize(frame, width=400)
37
38 # grab the frame dimensions and convert it to a blob
39 (h, w) = frame.shape[:2]
40 blob = cv2.dnn.blobFromImage(cv2.resize(frame, (300, 300)), 1.0,
41 (300, 300), (104.0, 177.0, 123.0))
42
43 # pass the blob through the network and obtain the detections and
44 # predictions
45 net.setInput(blob)
46 detections = net.forward()
47
48 # loop over the detections
49 for i in range(0, detections.shape[2]):
50 # extract the confidence (i.e., probability) associated with the
51 # prediction
52 confidence = detections[0, 0, i, 2]
53
54 # filter out weak detections by ensuring the `confidence` is
55 # greater than the minimum confidence
56 if confidence < args["confidence"]:
57 continue
58
59 # compute the (x, y)-coordinates of the bounding box for the
60 # object
61 box = detections[0, 0, i, 3:7] * np.array([w, h, w, h])
62 (startX, startY, endX, endY) = box.astype("int")
63
64 # draw the bounding box of the face along with the associated
65 # probability
66 text = "{:.2f}%".format(confidence * 100)
67 y = startY - 10 if startY - 10 > 10 else startY + 10
68 cv2.rectangle(frame, (startX, startY), (endX, endY),
69 (0, 0, 255), 2)
70 cv2.putText(frame, text, (startX, y),
71 cv2.FONT_HERSHEY_SIMPLEX, 0.45, (0, 0, 255), 2)
72
73 # show the output frame
74 cv2.imshow("Frame", frame)
75 key = cv2.waitKey(1) & 0xFF
76
77 # if the `q` key was pressed, break from the loop
78 if key == ord("q"):
79 break
80
81# do a bit of cleanup
82cv2.destroyAllWindows()
83vs.stop()
打开cmd命令提示符,切换至路径下,输入下述命令:
python detect_faces_video.py --prototxt deploy.prototxt.txt --model res10_300x300_ssd_iter_140000.caffemodel
如果程序出错,如ImportError: No module named imutils.video。这说明当前Python库中没有imutils库,所以可以使用pip安装:
pip install imutils
检测结果
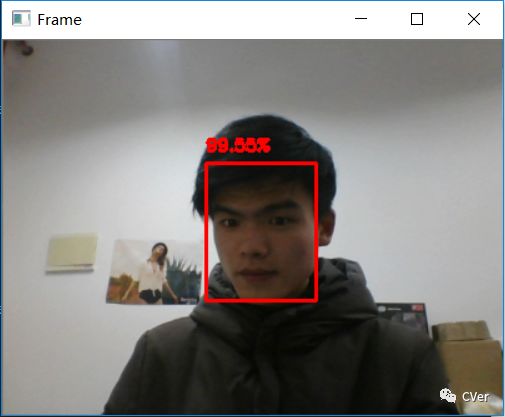
总结
本教程介绍并使用了OpenCV最新提供的更加精确的人脸检测器(与OpenCV的Haar级联相比)。
这里的OpenCV人脸检测器是基于深度学习的,特别是利用ResNet和SSD框架作为基础网络。
感谢Aleksandr Rybnikov、OpenCV dnn模块和Adrian Rosebrock等其他贡献者的努力,我们可以在自己的应用中享受到这些更加精确的OpenCV人脸检测器。
为了你的方便,我已经为你准备了本教程所使用的必要文件,请见下述内容。
代码下载
deep-learning-face-detection.rar:https://anonfile.com/nft4G4d5b1/deep-learning-face-detection.rarReference
[1]Face detection with OpenCV and deep learning:https://www.pyimagesearch.com/2018/02/26/face-detection-with-opencv-and-deep-learning/[2]face_detector:https://github.com/opencv/opencv/tree/master/samples/dnn/face_detector[3]opencv3.4 发布 dnnFace震撼来袭:http://blog.csdn.net/minstyrain/article/details/78907425
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~