
深度学习中目标检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

本文转自|AI算法与图像处理
该部分内容出自书《21个项目玩转深度学习:基于TensorFlow的实践详解》,有需要的同志可以关注我的公众号,加入下发的群,在群公告中有附网盘,可以自取(仅供学习使用)。如果失效可以联系或者在公众号留言!!!
深度学习中目标检测的原理
R-CNN 的全称是 Region-CNN,它可以说是第一个成功地将深度学习应用到目标检测上的算法 。 后面将要学习的 Fast R-CNN、 Faster R-CNN 全部都是建立在 R-CNN 基础上的 。
传统的目标检测方法大多以图像识别为基础。 一般可以在图片上使用穷
举法选出所高物体可能出现的区域框,对这些区域框提取特征并使用圄像识
别万法分类, 得到所高分类成功的区域后 , 通过非极大值抑制( Non-maximum suppression )输出结果 。
R-CNN遵循传统目标检测的思路 , 同样采用提取框 、 对每个框提取特征 、 图像分类、 非极大值抑制四个步骤进行目标检测。 只不过在提取特征这一步,将传统的特征(如 SIFT 、 HOG 特征等)换成了深度卷积网络提取的特征 。 R-CNN 的整体框架如图 5-2 所示 。
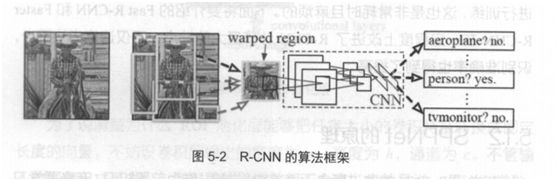
对比:
对于原始图像 , 首先使用 SelectiveSearch 搜寻可能存在物体的区域 。
Selective Search 可以从图像中启发式地搜索出可能包含物体的区域。 相比穷举而言, Selective Search 可以减少一部分计算量 。 下一步,将取出的可能含
高物体的区域送入 CNN 中提取特征 。 CNN 通常是接受一个固定大小的图像,而取出的区域大小却各高不同 。对此, R-CNN的做法是将区域缩放到统一大小 , 再使用 CNN提取特征 。 提取出特征后使用 SVM 进行分类,最后通过非极大值抑制输出结果 。
R-CNN的训练、可以分成下面四步:
1)在数据集上训练 CNN 。 R-CNN 论文中使用的 CNN 网络是 AlexNet,数据集为 ImageNet 。
2)在目标检测的数据集上,对训练好的 CNN司做微调 。
3)用 Selective Search 搜索候选区域,统一使用微调后的 CNN对这些区域提取特征,并将提取到的特征存储起来。
4)使用存储起来的特征 ,训练 SVM 分类器 。
尽管 R-CNN 的识别框架与传统方法区别不是很大,但是得益于 CNN 优异的特征提取能力, R-CNN 的效果还是比传统方法好很多。 如在 VOC 2007数据集上,传统方法最高的平均精确度 mAP ( mean Average Precision )为40%左右,而 R-CNN 的 mAP 达到了 58.5%!
R-CNN 的缺点是计算量太大 。 在一张图片中,通过 Selective Search 得
到的有效区域往往在 1000 个以上,这意昧着要重复计算 1000 多次神经网络 ,非常耗时 。另外,在训练、阶段,还需要把所有特征保存起来 ,再通过 SVM进行训练,这也是非常耗时且麻烦的。Fast R-CNN 和 FasterR-CNN 在一定程度上改进了 R-CNN 计算量大的缺点,不仅速度变快不少,识别准确率也得到了提高 。

具体的实现书中有详细说明
下面放上一些检测的代码


Faster –RCNN的检测效果


交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~