
Transformer 眼中世界 Vs. CNN 眼中世界
消失人口回归系列,嗯,这段时间也一直在从事反卷事业。
最近帮朋友看毕业 Report,主要对比视觉识别比较前沿的两个模型,ViT(Vision Transformer) 和 EfficientNet. 需要可视化解释一下这两模型对同一任务的不同之处。
EfficientNet 主要组件是 CNN 还好,CNN 在可视化各位大佬都做了,但 ViT 的 Transformer 在图像方面,说实话都不知道可视化哪部分,开头 patch 的转换部分或者 attention map 还行。
刚好看到这篇论文 Do Vision Transformers See Like Convolutional Neural Networks? 时不时莫名其妙在想什么问题时,突然蹦出相关论文,可能是老天想让我动动了。
ViT 和 ResNet 回顾
这篇论文如果只是想看结论,直接跳到第三小节就行。这里简单介绍一下要对比的模型 ViT 和 ResNet。
ViT 全称 Vision Transformer,即 Transformer 模型用在视觉领域,于去年年底谷歌论文 An Image is Worth 16x16 Words 中提出,当看到该来的还是来了,大家紧跟着赶紧各种魔改,最近也不少相关论文。
主要点还是怎么将图片作为 token 输入。之前比较粗暴点就是直接像素作为 token 输入,或者如 OpenAI 先训VAE 给图片转成离散 token 接着输入。而 ViT 是给图片切成一块块小方块(patch) ,经过线性投影成一个 embedding 表示,然后输入 Transformer 进行交互。
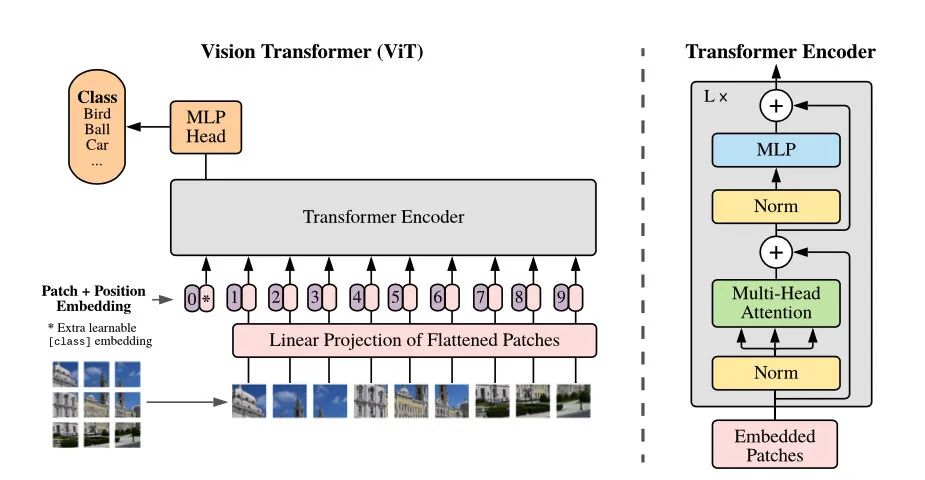
方法不难,但效果很不错,直接 SOTA 了。关于 ViT 各个版本变好主要就是模型大小和切块大小,比如16就是16x16的切块。
之后 ResNet 没有太多要介绍了,太经典了。

这篇 Transformer 和 CNN 对比论文,主要就是给 ViT 模型和 ResNet 模型中的表征抽取出来,然后进行分析。
CKA 向量相似计算介绍
其中用到最主要的分析方法就是 CKA 向量相似度分析法。
CKA(Centered Kernel Alignment)12年就提出来了,但在神经网络表征相似度计算的推广还要多亏 Hinton 团队19年那篇 Similarity of neural network representations revisited.
要计算神经网络表征在模型不同层,或不同模型间的相似度。因为特征是分散在大量神经元中,还有分布顺序和 scaling 问题,还是有些困难的。
CKA 方法,就是先选定两个要对比的表征层,比如说 ViT 的第2层和 ResNet 的第10层,那么取一些样本,输入两个模型,就能从对应层拿到两份表征。
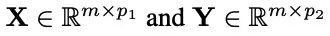
先分别对着两份表征计算 Gram matrix(就是计算向量两两之间内积组成的矩阵,相当于计算了各个数据点pair对之间的相似度)
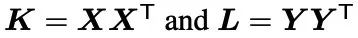
分别获得 和 ,之后再来计算它们的 Hilbert-Schmidt independence criterion (HSIC,Hilbert-Schmidt独立性指标,用于计算两个分布的统计学独立性),这里两个分布就是 和 ,具体计算过程如下,先构建一个中心矩阵
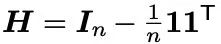
接着用 来给 和 分别中心化

接着就可以直接计算 HSIC 了
最后 Normalize 一下就是 CKA 了
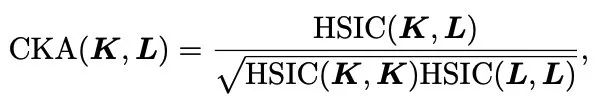
CKA 最大的优点是对矩阵正交变换后获得的结果也是不变的(比如排列不同),所以一个相同模型因为随机种子不同,表征顺序不同也没关系;而且 Normalization 后对不同 Scaling 也可以进行对比。
结论:这俩眼中的世界灰常的不同
讲完技术部分,就直接看实验结论吧。
ViT 内层间表征结构和 ResNet 内层间表征结构有很大不同
在 ViT 和 ResNet 模型内,对每层之间表征进行 CKA 分析
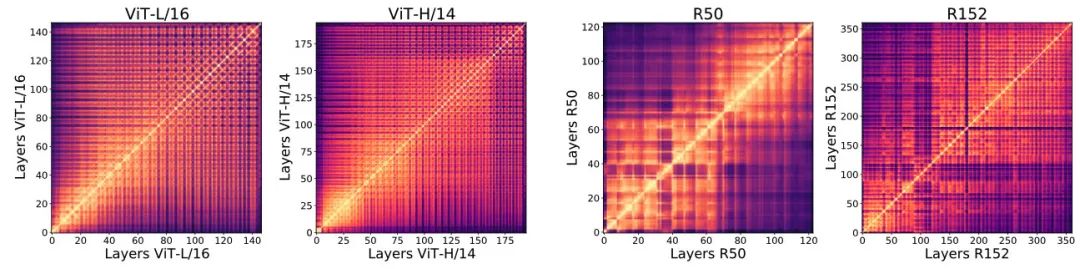
可清晰看到分别的热度图结构有很大的差别,对于 ViT 模型所有层之间会学到高度相似的表征,而对于 ResNet 则底层和高层网络学到的表征有很大不同。
ViT 和 ResNet 间表征对比也有很大不同
对不同模型表征之间进行相似度计算,看看 ViT 和 ResNet 学到的表征是不是有相似的。
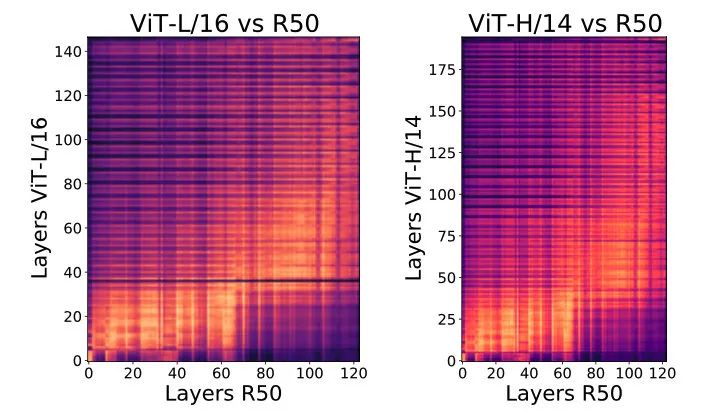
结果发现,ResNet 低层有很多层和 ViT的低层比较像,之后往上走点 ResNet 和 ViT 中间层的表征比较像,而没有特征和 ViT 的顶层相似,也就是说 ViT 顶层学到的表示和 ResNet 所有层学到的表示都差很多。
可能跟 ViT 最后输出用 [CLS] token,而 ResNet 用的 Global Pooling 有关,后面也有相关对比。
ViT 和 ResNet 表征中的局部和全局信息学习
对 ViT 每层各个头进行分析,每层各个头算 attention 的平均距离,排序画图,如下
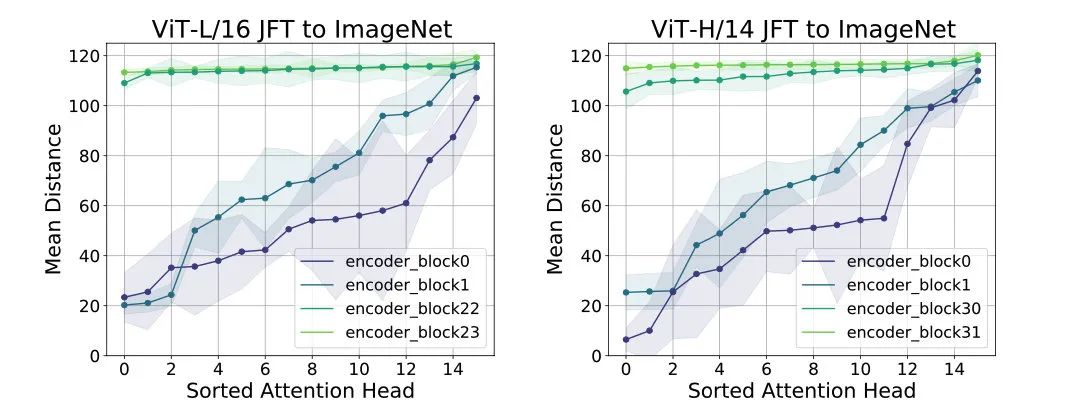
发现,对于 ViT 模型,在底层就已经是局部和全局信息都混在一起了,而上层则基本都是全局信息。和 ResNet 差别在于,因为 CNN 本身特性,底层只利用局部信息。之后作者们用 ResNet 学到的特征和 ViT 里注意力头特征做 CKA 分析,发现 ResNet 学到的和学习局部信息头学到的特征更相似。
此外,当用少量数据训练 ViT 的时候,发现底层的头是学习不到局部信息的。
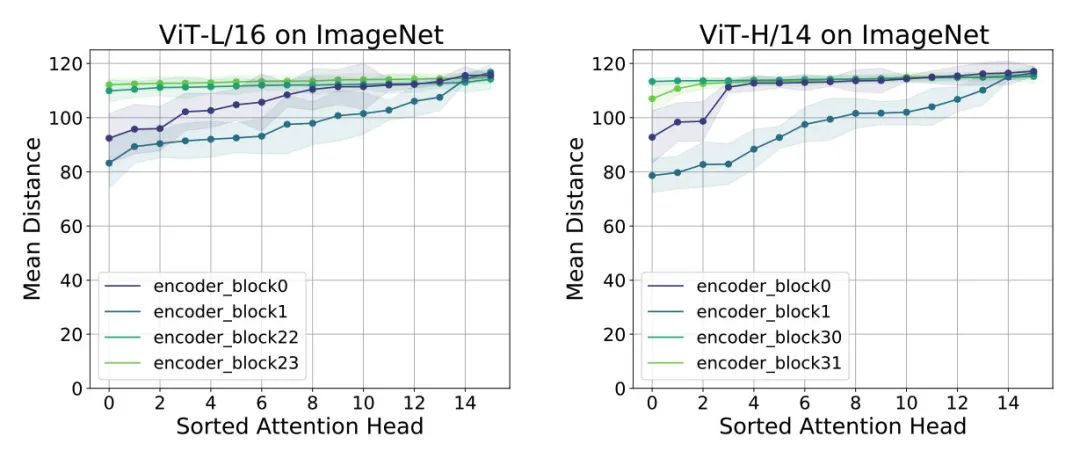
而这也导致了模型性能不是很好,所以视觉模型需要表现好,底层一般都需要学习到局部信息,这也是符合解剖学里面人类视觉神经结构的。
关于局部和全局信息,最近 Transformer 在视觉方面模型几个改进也都和这相关,比如最近的 Focal Transformer.
残差连接对 ViT 表征传播影响大些
有观察到 ViT 模型表征在各个层都近似,所以作者也有做关于残差连接对表征影响的实验。
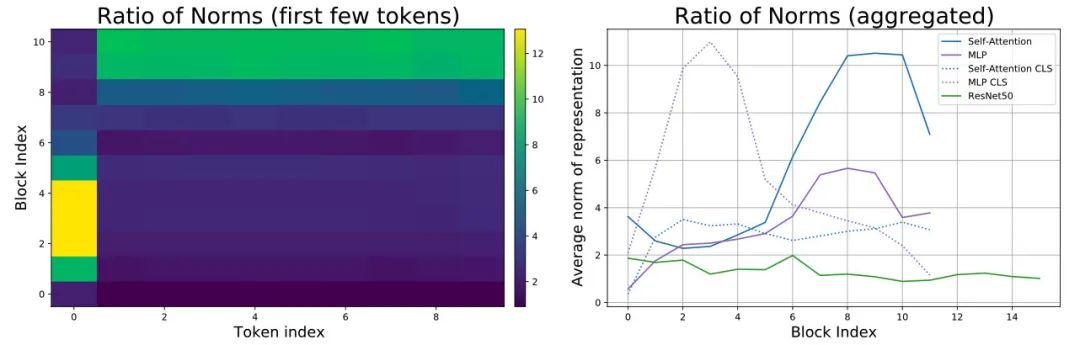
提到 ViT 模型很明显的有两个阶段,在前一个阶段残差连接主要保留 CLS token 的信息,之后阶段就主要是其他 token 的信息。这个之前看文本方面 Transformer 的分析好像也有类似结论。
这个还不够直观,最直观的是直接给其中一些残差连接去掉,然后做个对比
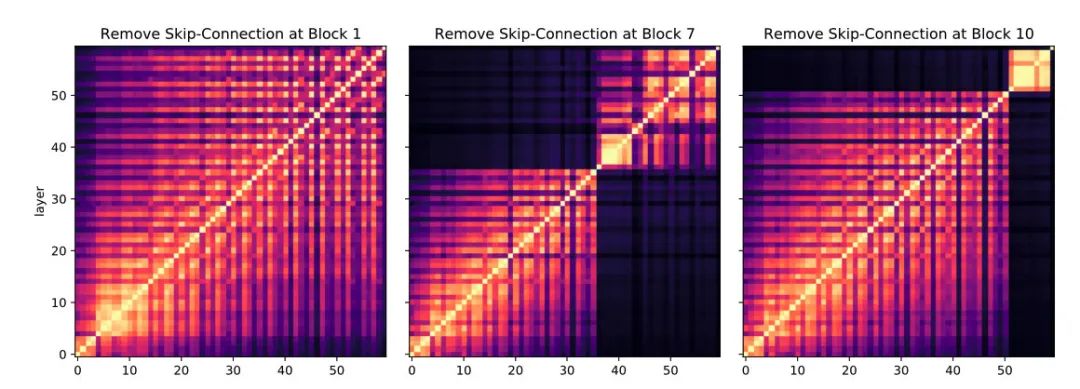
能明显看到去掉残差连接后,不同层表示之间相似度的变化。
最后一层空间信息的学习和 Pooling 相关
发现 ViT 高层比起 ResNet 能保留更多的空间位置,但作者猜想和 ViT 训练用 CLS 做 Pooling 有关,而 ResNet 是直接Global Pooling 取特征相关。
当对 ViT 也直接Global Pooling 取特征之后,就发现之前提到现象少了很多。
在迁移学习上 Scaling
发现对于ViT模型,大模型加大数据可以获得明显更好的中间表示,正常结论.
——The End——

