梯度下降算法的工作原理
共
1101字,需浏览
3分钟
·
2020-10-29 15:03
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达
梯度下降算法是工业中最常用的机器学习算法之一,但也是很多新手难以理解的算法之一。如果你刚刚接触机器学习,那么梯度下降算法背后的数学原理是比较难理解的。在本文中,我将帮助你了解梯度下降算法背后的工作原理。我们会了解损失函数的作用,梯度下降的工作原理,以及如何选择学习参数。什么是损失函数
它是一个函数,用于衡量模型对任何给定数据的性能。损失函数将预测值与期望值之间的误差进行量化,并以单个实数的形式表示出来。
在对初始参数进行假设后,我们会计算了损失函数,以降低损失函数为目标,利用梯度下降算法对给定数据进行参数修正。下面是它的数学表示: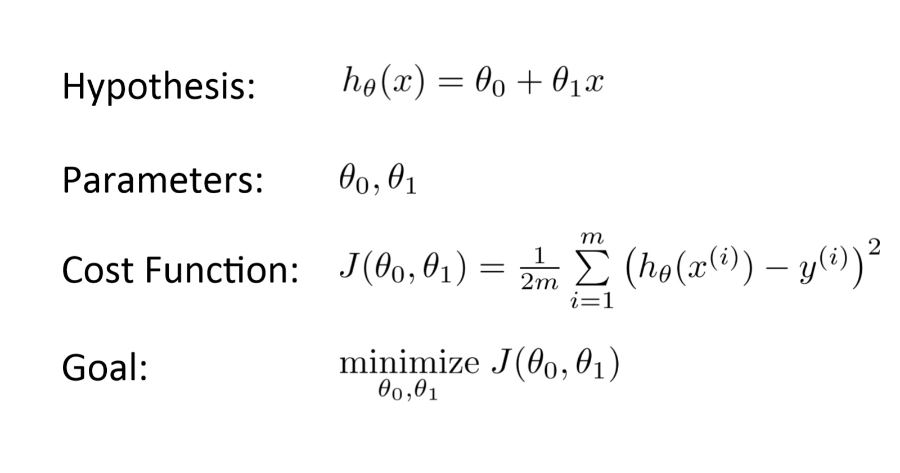
什么是梯度下降
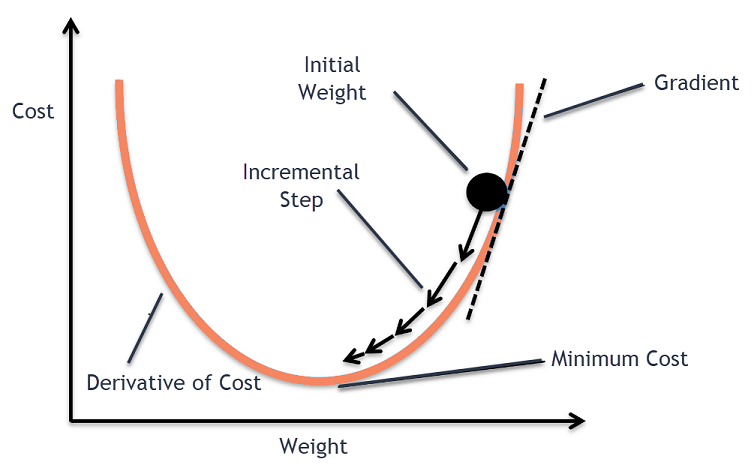
假设你在玩一个游戏,玩家在山顶,他们要求到达山的最低点,此外,他们还蒙着眼睛,那么,你认为怎样才能到达最低点呢?最好的办法是观察地面,找出地面下降的地方,从这个位置开始,向下降方向迈出一步,重复这个过程,直到到达最低点。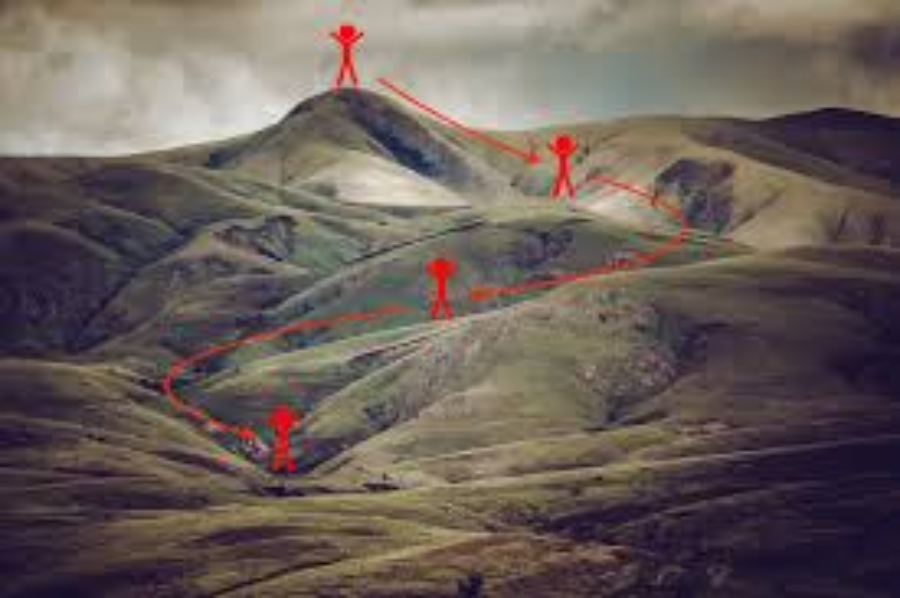
梯度下降法是一种求解函数局部极小值的迭代优化算法。
要用梯度下降法求函数的局部极小值,必须选择与当前点处函数的负梯度(远离梯度)方向。如果我们采取与梯度的正方向,我们将接近函数的局部极大值,这个过程称为梯度上升。梯度下降最初是由柯西在1847年提出的,它也被称为最速下降。梯度下降算法的目标是最小化给定函数(比如损失函数)。为了实现这一目标,它迭代地执行两个步骤:

Alpha被称为学习率-优化过程中的一个调整参数,它决定了步长。绘制梯度下降算法
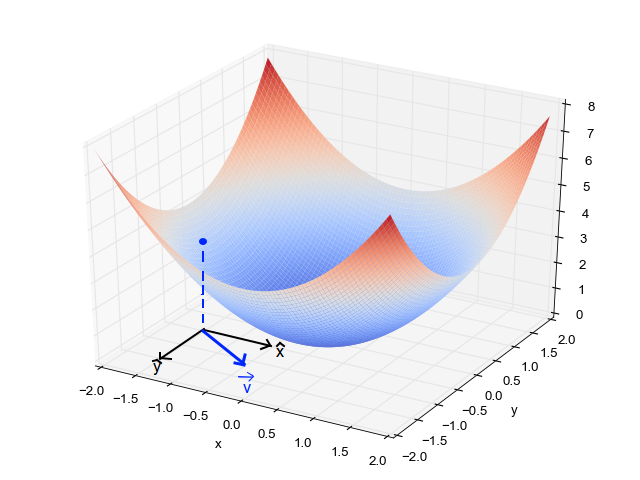
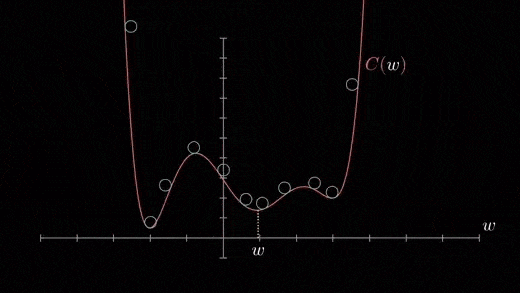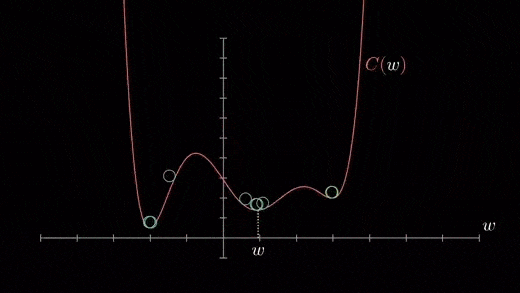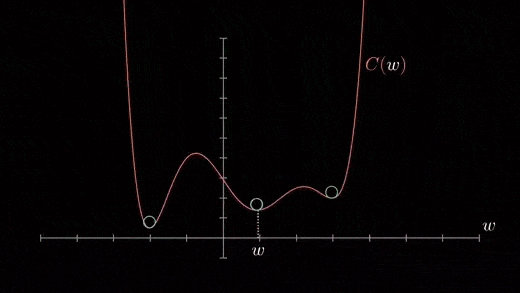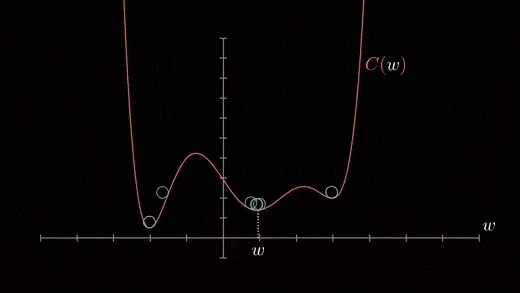
当我们有一个单一的参数(θ),我们可以在y轴上绘制因变量损失值,并在x轴上绘制θ。如果有两个参数,我们可以进行三维绘图,其中一个轴上有损失值,另两个轴上有两个参数(θ)。它也可以通过使用等高线来可视化,这会显示一个二维的三维绘图,其中包括沿两个轴的参数和等高线的响应值。远离中心的响应值增加,并且随着环的增加而增加。α-学习率
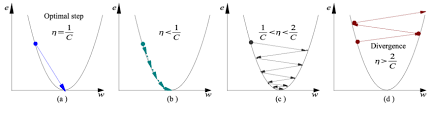
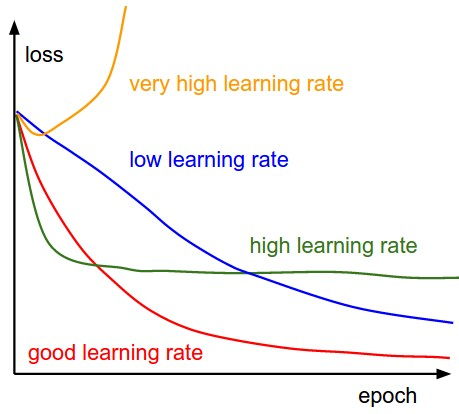
有了前进的方向之后,现在我们必须决定我们要采取的步大小。- 如果学习率太高,我们可能会超过最小值,而不会达到最小值
b) 学习速度太小,需要更多的时间,但会收敛到最小值c) 学习率高于最优值,较慢速度的收敛(1/c<η<2/c)d) 学习率非常大,它会过度偏离,偏离最小值,学习性能下降注:随着梯度减小而向局部最小值移动,步长减小,因此,学习速率(alpha)可以在优化过程中保持不变,而不需要迭代地改变。局部最小值
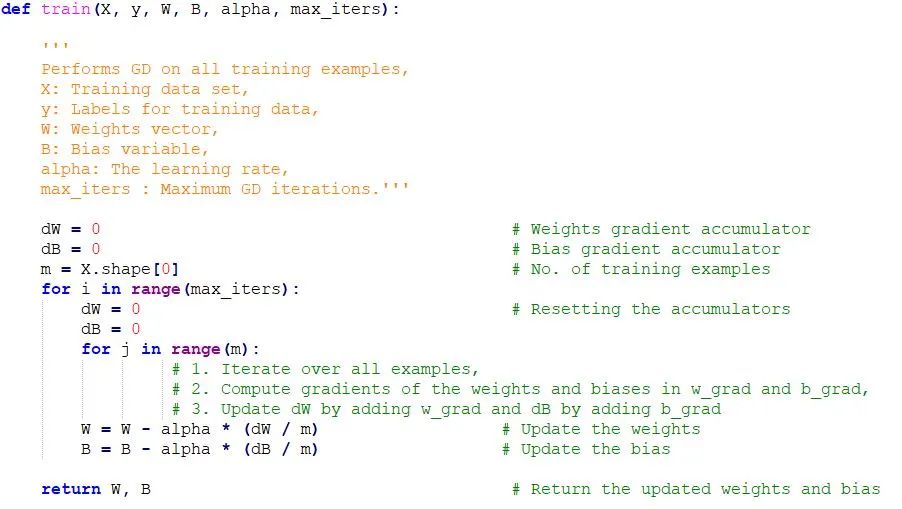
成本函数可以由许多最小点组成。梯度可以落在任何一个极小值上,这取决于初始点(即初始参数θ)和学习速率,因此,在不同的起点和学习率下,优化可以收敛到不同的点。梯度下降的Python代码实现
结尾
一旦我们调整了学习参数(alpha)并得到了最优的学习速率,我们就可以开始迭代了,直到我们收敛到局部最小值。参考链接:https://www.analyticsvidhya.com/blog/2020/10/how-does-the-gradient-descent-algorithm-work-in-machine-learning/
点赞
评论
收藏
分享

手机扫一扫分享
举报
点赞
评论
收藏
分享
手机扫一扫分享
举报