
梯度下降算法综述!
algorithms进行介绍并在此基础上进行一定的分析和补充。
背景介绍
 图1:梯度下降算法示意图
图1:梯度下降算法示意图
随着近年来深度学习领域的蓬勃兴起,梯度类算法成为了优化神经网络的最重要的方法。各种深度学习的框架(如Caffe, Keras, TensorFlow and PyTorch)中,均支持各种各样的梯度类优化器。梯度类方法在深度学习中如此重要的主要原因是深度神经网络中数以百万、千万级别的待优化参数使得诸如牛顿法和拟牛顿法等高阶优化方法不再可行,而梯度类方法借助GPU计算资源的支持可以进行高效的运算。然而天下没有免费的午餐,当我们使用一阶优化算法获取其计算可行性上的好处时,付出的代价便是一阶算法较慢的收敛速率。尤其是当目标函数接近病态系统时,梯度类算法的收敛速度会变得更加缓慢。除此之外,由于深度神经网络的损失函数极其复杂且非凸,梯度类算法优化得到的模型参数的性质未知,依赖于算法的参数选取和初值的选取。因此,目前深度学习中的梯度类算法实际上是某种意义上的黑箱算法,其可解释性仍然面临着巨大挑战。
梯度下降算法的变体
批量梯度下降
随机梯度下降
小批量梯度下降
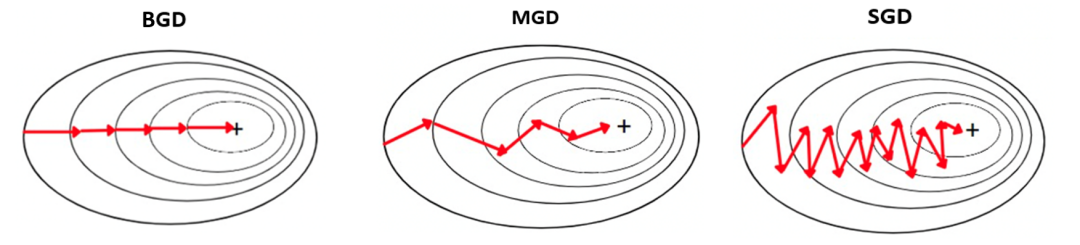 图2:三种梯度下降算法的对比示意图
图2:三种梯度下降算法的对比示意图
梯度下降算法的改进算法
如前所说,梯度下降算法作为一阶算法有其固有的局限性,仅仅使用损失函数的一阶信息进行更新是比较“短视”的做法,在病态系统下收敛速度极为缓慢。学者们也提出了一系列方法来加速梯度下降算法,主要的思路是对梯度下降法的两个主要组成部分进行修改,即更新方向和学习率。我们接下来主要介绍其中几种十分重要的算法。请注意,以下算法原始版本均是在非随机优化或BGD的条件下讨论的,但是在实际深度学习的应用中往往是使用了MGD的版本,我们在下文的介绍中并不区分这些细节。
动量梯度下降
动量梯度下降(Gradient Descent with Momentum)法 [Polyak, 1964, Ning, 1999],也被称为重球(Heavy Ball, HB)方法,是对梯度下降算法的经典改进算法,其更新公式如下:
Nesterov动量梯度
Nesterov动量梯度(Nesterov accelerated gradient, NAG)方法 [Nesterov, 1983],是动量梯度下降法的改进版本,其更新公式如下:
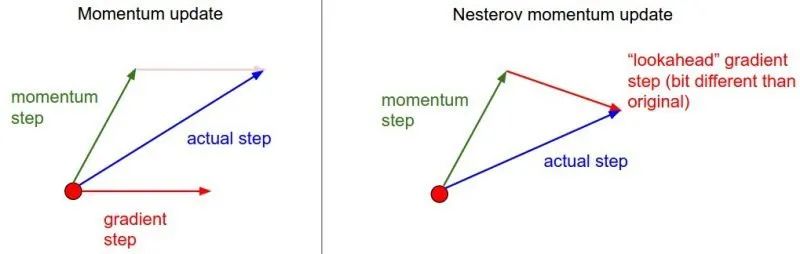 图3:动量梯度下降与NAG的对比示意图
图3:动量梯度下降与NAG的对比示意图
AdaGrad
AdaDelta
RMSprop
RMSprop[Tieleman and Hinton, 2012]和AdaDelta的思路十分相似,两个算法同年分别被Hinton和Zeiler提出,有趣的是Hinton正是Zeiler的导师。RMSprop最早出现在Hinton在Coursera的课程中,这一算法成果并未发表。其更新公式与第一阶段的AdaDelta一致:
Adam
自适应矩估计算法(Adaptive Moment Estimation, Adam)[Kingma and Ba, 2015]是将搜索方向和学习率结合在一起考虑的改进算法,其原论文引用量为ICLR官方引用最高的文章。Adam的思路非常清晰:搜索方向上,借鉴动量梯度下降法使用梯度的指数加权;学习率上,借鉴RMSprop使用自适应学习率调整。所谓矩估计,则是修正采用指数加权带来的偏差。其更新公式具体如下:
AdaMax 与 Nadam
Nadam[Dozat, 2016]则是将Adam中关于搜索方向的部分改为使用Nesterov动量。在引入其更新公式之前,我们首先给出NAG的等价更新形式。
一些可视化结果
我们展示两幅图片来对比不同的优化算法的表现,如图4所示。
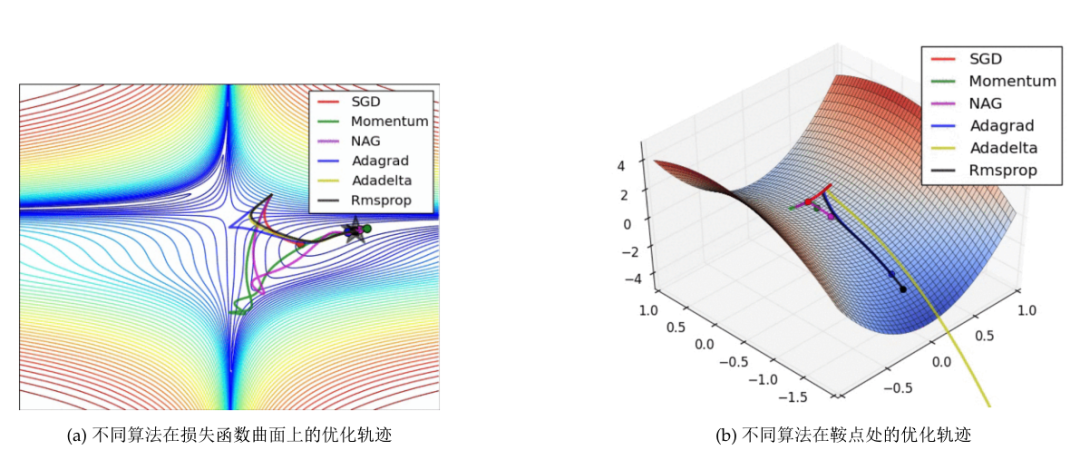 图4:梯度下降算法的可视化结果
图4:梯度下降算法的可视化结果
图4-(a)展示的是六种梯度下降改进算法在Beale函数的函数曲面的优化路径。等高线由红变蓝的过程表示函数值由大到小,最小值点在图中由五角星标出。所有的算法均从同一点出发,可以看到自适应学习率类的算法(AdaGrad, AdaDelta和RMSprop)的优化路径直接走向了右边的极小值点,但是动量梯度法(绿色曲线)和NAG(紫色曲线)均是先走到了另一处狭长的区域,再转向极小值点,且NAG的纠正速度快于动量梯度法。
图4-(b)展示的是六种梯度下降改进算法在鞍点附近的优化路径。所谓鞍点就是,满足一阶条件等于0但是海森矩阵的特征值有正有负的点。由于梯度下降算法仅仅考虑一阶条件,理论上会受到鞍点的困扰。可以看到,SGD(红色曲线)在鞍点处停止,动量梯度法(绿色曲线)和NAG(紫色曲线)在鞍点处停留一会后逐渐脱离鞍点,而三种自适应学习率算法则能够快速摆脱鞍点。
梯度类算法相关研究
并行SGD和分布式SGD
在当今无处不在的大数据时代,数据的分布方式和使用方式都不再像原来一样单一。与之对应的,当数据仍然保存在本地,学者们开始研究如何在单机上实现并行SGD[Niu et al., 2011]来进行加速;当数据分散地保存在不同的节点,如何实现分布式SGD[Jeffrey Dean and Ng., 2012, Mcmahan and Streeter, 2014, Sixin Zhang and LeCun, 2015];更进一步地,对于数据节点十分庞大而又需要保护用户隐私的时代,联邦学习(Federated Learning)版本的SGD[H. Brendan McMahan and y Arcas, 2016]同样也是学者们关注的问题。由于篇幅原因,我们不在这里进行展开。
梯度类算法的训练策略
除了算法层面的改进,与算法相配套的训练策略或者其他技术同样对训练模型有很大的影响。例如:
数据打乱和课程式学习. 有学者指出避免让数据以固定单一的方式进入模型训练能够提升模型的泛化能力,因此在深度学习模型的训练中人们在每一次遍历全样本后都会进行数据打乱(Shuffling)。另一方面,有学者指出让数据以某种有意义的顺序参与模型训练能够使模型更快收敛且表现不错,这样的方法被称为课程式学习(Curriculum Learning)[Yoshua Bengio and Weston, 2009]. 批量归一化. 批量归一化(Batch normalization)[Ioffe and Szegedy, 2015]是卷积神经网络中经常使用的技术,它能够对每个小批量的数据在模型的某些节点进行归一化。大量实验表明,这种技术能够加速梯度类算法的收敛、让梯度类算法使用更大的初始学习率以及减少参数初始化的影响。 早停. 通过监控验证集的精度指标来决定是否要提前终止算法训练。 梯度噪声. [Neelakantan et al., 2015]提出在梯度上增加独立的高斯噪声,来帮助梯度类算法增加稳健性。他们猜测,增加的梯度噪声能够帮助算法跳过局部鞍点和次优的极小值点。
梯度类算法仍然面临的挑战
尽管我们已经介绍了非常多的梯度类算法的改进算法,但是梯度类算法仍然面临着许多挑战。
选择合适的学习率是非常困难的事情。尽管在传统的优化领域和我们之前提到的自适应学习率算法提供了很多解决这个问题的方法。在深度模型的训练中,这些已有的方法仍然会遇到问题,因此这仍是一个需要小心考虑和诸多尝试的问题。 尽管梯度下降算法在理论上有许多性质和结论,但实际得到神经网络往往不满足已有结论的前提假设。在我们优化超高维非凸的损失函数时,如何保证算法不被鞍点 [Zeiler, 2014]、平坦区域所困扰,依然是十分挑战的问题。 对于超高维得到损失函数,梯度类算法表现地像黑箱优化器,目前上没有特别好的方法对这种超高维优化进行可视化分析。
参考文献
Augustin-Louis Cauchy. Mode grale pour la rlution des systs d’ations simultan. Comptes rendus des sces de l’ Acade des sciences de Paris, pages 536–538, 10 1847.
Xi Chen, Jason D Lee, Xin T Tong, and Yichen Zhang. Statistical inference for model parameters in stochastic
gradient descent. arXiv preprint arXiv:1610.08637, 2016.
Haskell B. Curry. The method of steepest descent for non-linear minimization problems. Quarterly of Applied
Mathematics, pages 258–261, 2 1944.
Jia Deng, Wei Dong, Richard Socher, Li Jia Li, and Fei Fei Li. Imagenet: A large-scale hierarchical image
database. In IEEE Conference on Computer Vision and Pattern Recognition, 2009.
Timothy Dozat. Incorporating nesterov momentum into adam. ICLR Workshop, 2016.
John Duchi, Elad Hazan, and Yoram Singer. Adaptive subgradient methods for online learning and stochastic
optimization. Journal of Machine Learning Research, 12(7):257–269, 2011.
Igor Gitman, Hunter Lang, Pengchuan Zhang, and Lin Xiao. Understanding the role of momentum in stochastic gradient methods. In Proceedings of 33rd Conference and Workshop on Neural Information Processing Systems,
2019.
Daniel Ramage Seth Hampson H. Brendan McMahan, Eider Moore and Blaise Aguera y Arcas.
Communication-efficient learning of deep networks from decentralized data. In International Conference on
Machine Learning (ICML), 2016.
Sergey Ioffe and Christian Szegedy. Batch normalization: Accelerating deep network training by reducing
internal covariate shift. In Proceedings of the 32nd annual international conference on machine learning, 2015.
Rajat Monga Kai Chen Matthieu Devin Quoc V. Le Mark Z. Mao Marc Aurelio Ranzato Andrew Senior Paul
Tucker Ke Yang Jeffrey Dean, Greg S. Corrado and Andrew Y. Ng. Large scale distributed deep networks. In
Neural Information Processing Systems Conference (NIPS 2012), pages 1–11, 2012.
Diederik P. Kingma and Jimmy Lei Ba. Adam: A method for stochastic optimization. In International Conference
on Learning Representations, pages 1–13, 2015.
H. Brendan Mcmahan and Matthew Streeter. Delay-tolerant algorithms for asynchronous distributed online
learning. In Neural Information Processing Systems Conference (NIPS 2014), pages 1–9, 2014.
A. Neelakantan, L. Vilnis, Q. V. Le, I. Sutskever, and J. Martens. Adding gradient noise improves learning for
very deep networks. arXiv preprint arXiv:1511.06807., 2015.
Arkadii S. Nemirovski, Anatoli Juditsky, Guanghui Lan, Shapiro, and A. Robust stochastic approximation
approach to stochastic programming. SIAM Journal on Optimization, 19(4):1574–1609, 2009.
Y. E. Nesterov. A method for solving the convex programming problem with convergence rate o(1/ ). Dok-
l.akad.nauk Sssr, 269, 1983.
Q. Ning. On the momentum term in gradient descent learning algorithms. Neural Netw, 12(1):145–151, 1999.
F. Niu, B. Recht, C. Re, and S. J. Wright. Hogwild!: A lock-free approach to parallelizing stochastic gradient
descent. In Neural Information Processing Systems Conference (NIPS 2011), pages 1–22, 2011.
B. T. Polyak. Some methods of speeding up the convergence of iteration methods. Ussr Computational Mathe-
matics Mathematical Physics, 4(5):1–17, 1964.
A. Rakhlin, O. Shamir, and K. Sridharan. Making gradient descent optimal for strongly convex stochastic
optimization. In International Conference on Machine Learning, 2012.
Anna Choromanska Sixin Zhang and Yann LeCun. Deep learning with elastic averaging sgd. In Neural Information Processing Systems Conference (NIPS 2015), pages 1–9, 2015.
R.S. Sutton. Twoproblemswith backpropagationand other steepest-descent learning proceduresfor networks.
proc cognitive sci soc, 1986.
T. Tieleman and G. Hinton. Lecture 6.5-rmsprop: Divide the gradient by a running average of its recent magnitude. COURSERA: Neural Networks for Machine Learning, pages 26–31, 2012.
Panos Toulis and Edoardo M. Airoldi. Asymptotic and finite-sample properties of estimators based on stochastic gradients. Eprint Arxiv, 45(4):1694–1727, 2017.
Ronan Collobert Yoshua Bengio, Jme Louradour and Jason Weston. Curriculum learning. In Proceedings of the
26th annual international conference on machine learning, pages 41–48, 2009.
Matthew D. Zeiler. Adadelta: An adaptive learning rate method. arXiv preprint arXiv:1212.5701, 2012.
Matthew D. Zeiler. Identifying and attacking the saddle point problem in high-dimensional nonconvex optimization. arXiv preprint arXiv:1406.2572, 2014.
- END -