
线性回归拟合优度的度量:R平方
线性回归 Y = ax + b 的拟合程度,都是用 R 平方来进行判定,所以本篇文章来梳理 R 平方的具体计算方式。
首先,根据这一回归方程,可以依据自变量 x 的取值来预测因变量 Y 的取值。但预测的精度取决于回归直线对观测数据的拟合程度。各个观测点(也就是训练集的数据)越是紧密围绕直线,说明直线对观测数据的拟合程度越好,反之则越差。
两个变量的相关分析中,我们用相关系数来衡量,Pearson 相关系数就是 R 值。这个在《相关系数之Pearson》有过介绍。
R 值的作用也很清楚。判断自变量与因变量的关系,以确定该自变量有没有纳入回归方程的必要。如果是一元回归,就是有没有做回归分析的必要。一般情况下,如果 R 低于 ±0.5,则这个自变量不需要纳入回归方程。另外一个就是上面说的,衡量预测的精度。
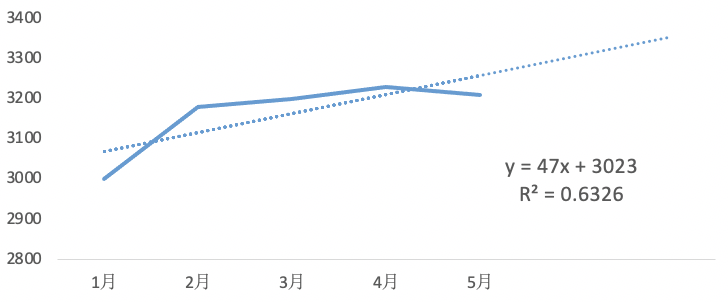
再来介绍下 R 平方。 可以理解为 Pearson 系数的平方,但计算方法是通过类似方差分析的方法得到的。R 平方又叫决定系数,反应因变量 Y 的总变异中回归关系所能解释的百分比。如图,如果 R 平方值 0.6326,代表的是总变异中回归关系可解释部分的占比为 63%。
R 平方的公式如下: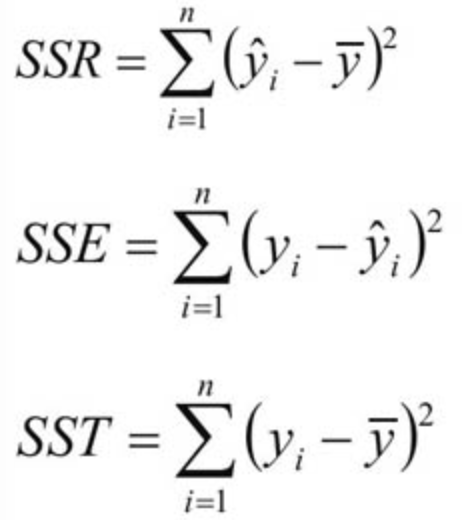
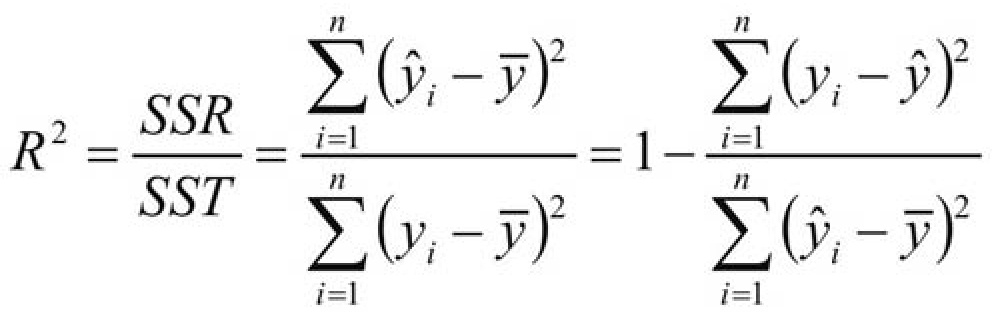
每个观测点的离差,比较直观的是直接在坐标系上表现,其中:
 是 SSR。也就是因为自变量 x 的变化,引起的 y 的变化,代表回归关系中可被解释的部分。
是 SSR。也就是因为自变量 x 的变化,引起的 y 的变化,代表回归关系中可被解释的部分。
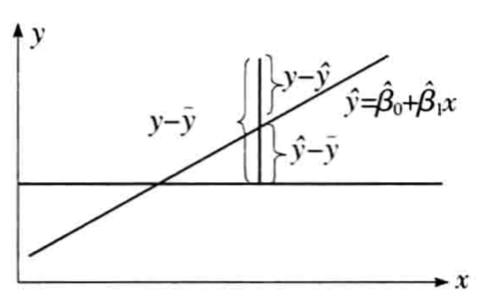 图:统计学-贾俊平
图:统计学-贾俊平
SSR(回归平方和):样本平均值与预测值的差的平方和,由 x 与 y 的线性关系引起的 y 变化,代表回归关系中可被解释的部分。
SSE(残差平方和):样本观测值与预测值的差的平方和,除 x 影响之外的其他因素引起的 y 变化,代表回归关系中不可解释的部分。
SST(总平方和):样本观测值与样本平均值的差的平方和,代表总的变异程度。
从图中和公式可以看出,SST = SSR+ SSE ,总变异来自两个方面的影响,一个是来自因变量 x 的影响(SSR),一个是来自无法预测的残差干扰(SST),想要回归直线拟合的越好,就需要让能被回归可解释的部分(SSR/SST)占比越高,无法被回归解释的部分(SSE/SST)占比越小。
总结下,平方值是取值范围在 0 到 1 之间,当趋势线的 R 平方值等于 1 或接近 1 时,意味着大部分 Y 的总变异可以被回归方程式的 x 变化所解释,模型拟合程度的越高,可靠性越高,反之则可靠性较低。