
细粒度图像分割 (FGIS)
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


如今,照片逼真的编辑需要仔细处理自然场景中经常出现的颜色混合,这些颜色混合通常通过场景或对象颜色的软选择来建模。因此,为了实现高质量的图像编辑和背景合成,精确表示图像区域之间的这些软过渡至关重要。工业中用于生成此类表示的大多数现有技术严重依赖于熟练视觉艺术家的某种用户交互。因此,创建如此准确的显著性选择成为一项昂贵且繁琐的任务. 为了填补熟练视觉艺术家的空白,我们利用计算机视觉来模拟人类视觉系统,该系统具有有效的注意力机制,可以从视觉场景中确定最显着的信息。这类问题也可以解释为前景提取问题,其中显着对象被视为前景类,其余场景为背景类。计算机视觉和深度学习旨在通过一些选择性研究分支对这种机制进行建模,即图像抠图、显著目标检测、注视检测和软分割。值得注意的是,与计算机视觉不同,深度学习主要是一种数据密集型研究方法。
随着近年来使用全卷积网络 (FCN) 进行图像分割的兴起,深度学习显著改善了前景提取和显著性检测基线。尽管有这些改进,但大多数建议的架构使用最初为图像属性分类任务设计的网络主干,它提取具有语义意义的代表性特征,而不是全局对比度和局部细节信息。
是的,如果我们从输出格式的角度来看,这是一个分割问题。近年来,语义分割已成为计算机视觉和深度学习领域的一个关键问题。因此,从更大的场景来看,我们可以说语义分割是该领域的关键任务之一,它为更好地理解场景铺平了道路。从图像和视频中推断认知事实的应用越来越多,这也突出了场景理解的重要性。
细粒度语义分割的三种方法:
图像抠图
显着目标检测 (SOD)
软分割

图像抠图可以理解为绿屏抠像的广义版本,用于在无约束设置中精确估计前景不透明度。图像抠图是计算机图形学和视觉应用中一个非常重要的课题。早期的图像抠图方法涉及大型稀疏矩阵,例如大型核抠图拉普拉斯算子及其优化。然而,这些解决此类线性系统的方法通常非常耗时且不受用户欢迎。许多研究试图通过使用自适应内核大小和 KD 树来提高这种线性系统的求解速度,但在野生图像的质量和推理速度方面没有观察到显着的改进。由于问题是高度不适定的,用户通常会给出一个trimap(或笔划)来表示明确的前景、明确的背景和未知区域,作为支持性输入。

让我们首先制定一个基本的图像抠图公式。将图像像素的背景颜色、前景色和前景不透明度分别表示为 B、F 和 α,像素的颜色 C 可以写为 B 和 F 的组合:
C = F (α)+ B(1 − α)。
图像抠图方法可以分为三种主要类型,基于传播的、基于采样的和基于学习的。在某些方法中,还使用了基于采样和基于传播的抠图的混合组合。
基于采样的图像抠图基于以下假设:未知像素的真实背景和前景颜色可以从位于该未知像素附近的已知背景和前景像素导出。一些基于采样的方法:
共享采样抠图
迭代抠图
贝叶斯抠图
稀疏编码
基于传播的图像抠图技术通过将已知局部背景和前景像素的 alpha 值传播到未知区域来计算未知像素的 alpha 值。然而,在野生背景图像的情况下,对颜色知识的过度依赖导致图像中背景和前景色的分布重叠的伪影。一些基于传播的方法:
Geodesic 抠图
Close-form 抠图
Poisson 抠图
Spectral 抠图
尽管如此,采样和基于传播的技术都无法提供令人满意和完全自动化的结果。因此,一些深度学习研究者提出了一些方法,可以通过将trimap 和 RGB 图像串联输入到 FCN 中来解决上述线性系统,或者仅通过 RGB 图像本身来预测最终的 alpha 蒙版。
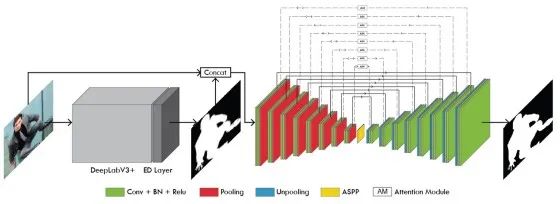
根据经验,基于深度学习的方法能够比其他两种方法更好地捕获全局语义信息和局部细节,而且它们不偏向于任何已知和未知区域像素之间存在相关性的粗略假设。
SOD 的主要目标是分割图片中最显著(重要)和视觉上有吸引力的对象。许多领域,如图像分割和视觉跟踪,在各种应用中应用 SOD。与图像抠图类似,在用于显着性检测的全卷积网络 (FCN) 兴起之后,SOD的最新技术水平显著提高。
与自然抠图不同,显著目标检测并不像看起来那么复杂,实现精确显著目标检测的主要挑战是:
(1)显著性定位。特定视觉资源的显着性通常定义为整个图像的全局对比度,而不是任何像素或局部特征。因此,为了获得精确的 SOD,显著性检测算法不仅要捕获整个图像的全局对比度,还要建立对前景对象详细结构的精确表示。为了解决这个问题,使用了多级深度特征聚合网络。
(2)没有边界细化损失。用于训练显著性目标检测模型的最常见的损失是联合交集 (IoU) 损失或交叉熵 (CE)。但这两种方法都会导致边界细节模糊,因为它们都能有效区分边界像素。许多研究也使用 Dice-score 损失,但其主要目的是处理有偏差的训练集,而不是专门加强精细结构的建模。
用于显著目标检测的深度学习文献有着丰富的现代历史。一些研究强调使用具有注意机制的深度递归网络对某些选择性图像子区域进行迭代细化。另一方面,一些研究强调了通过深度多径循环连接从网络深层到浅端的全局信息传输的有效性。许多作者像胡等人[1] 和王等人[2] 提出了使用循环全连接网络或循环连接多层深层特征进行显著目标检测方法,这些研究也表明了预测误差迭代修正的有效性。与前面提到的研究工作相比,一些研究还展示了在U-Net 架构中使用上下文注意网络来预测像素级注意力图的架构。从评价指标来看,这些提取的像素级注意图对于显著性检测是非常有效的。提出的方法很少有强调从粗到细的预测转换,这些方法提出了通过捕获更精细的结构来实现更准确的边界细节的细化策略。例如,卢等人提出了一种架构,该架构捕获深度层次显著性表示,用于对显著图的各种全局结构化显著性线索以及后细化阶段进行建模。显著目标检测领域的最新进展是Qin 等人提出的,他们提出了一个强大的深度网络架构(U^2-Net),具有两层嵌套的 U 结构。

根据经验,SOD 也实现了更高质量的显着图作为自然图像抠图,但在透明度建模和精细结构提取方面的质量较差。
软分割被定义为将图像分解为两个或更多部分,其中每个成员像素可能拥有分为两个或更多部分的成员资格。

语义软段,通过为每个段分配纯色来可视化
大多数早期的软分割方法强调使用逐像素颜色分离或全局优化来提取各种同质颜色的软显著性图。虽然观察到这些提取的软彩色地图对许多关键的图像编辑应用程序(例如图像重新着色)很有用,但与 SOD 类似,它们并没有特别考虑对象边界和过渡区域粒度。有趣的是,图像抠图与软分割的分支有着非常密切的关系。事实上,一些图像抠图文献(例如 Matting Laplacian)完全符合软分割的关键思想,即捕捉图像中局部软过渡区域的强大表示。给定一组用户定义的区域,这些方法主要基于迭代求解两层软分割问题以生成多层的思想。Levin等人在光谱抠图方面的工作也达到了同样的目的,通过光谱分解自动估计一组空间连接的软段。Aksoy等人最近的软分割研究也遵循了光谱抠图与光谱分解和消光拉普拉斯算子相结合的思想。然而,与光谱抠图不同的是,他们的工作通过将局部纹理信息与训练用于场景分析的深度卷积神经网络的高级特征融合,从光谱分解角度解决问题。他们的主要贡献之一是使用类似图的结构,通过语义对象以及它们之间的软转换来丰富相应拉普拉斯矩阵的特征向量。
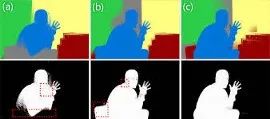
根据经验,软分割是自然图像抠图的一个派生分支,它结合了丰富的历史图像抠图实践和深度学习的力量。同样与普通图像抠图不同的是,软分割提供了更多层的输出来表示语义上有意义的区域。但是,尽管有很大的改进,仍有巨大的改进空间需要解决。
我们已经从解决显着前景提取问题的角度解释了这些方法,但这些方法所要解决的实际问题在各自的研究分支中非常丰富和多样化,并以自己的方式为深度计算机视觉领域做出了贡献。
[1] 胡小伟、朱磊、秦静、傅志荣、彭安恒。反复聚合深度特征以进行显着目标检测。在 AAAI-18 会议记录中,美国路易斯安那州新奥尔良,第 6943-6950 页,2018 年。
[2] 王林昭、王立军、卢虎川、张萍萍、向阮。使用循环全卷积网络进行显着目标检测。IEEE 模式分析和机器智能汇刊,2018 年。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~