
机器学习模型部署都有哪些坑?剑桥研究者梳理了99篇相关研究
点击上方“AI算法与图像处理”,选择加"星标"或“置顶”
重磅干货,第一时间送达
在生产环境中部署机器学习模型是一个复杂的过程,需要考虑诸多因素,也存在很多挑战。近日,来自剑桥的研究者梳理了该流程常见的问题。

用例研究型论文:这类论文提供单个机器学习部署项目的经过,通常会深入讨论作者面临的每个挑战以及克服方式。
综述文章:这类文章描述了机器学习在特定领域或行业中的应用,通常总结了在所涉及领域中部署机器学习解决方案最常遇到的挑战。
经验总结型论文:作者通常会回顾他们在生产中部署机器学习模型的经验。
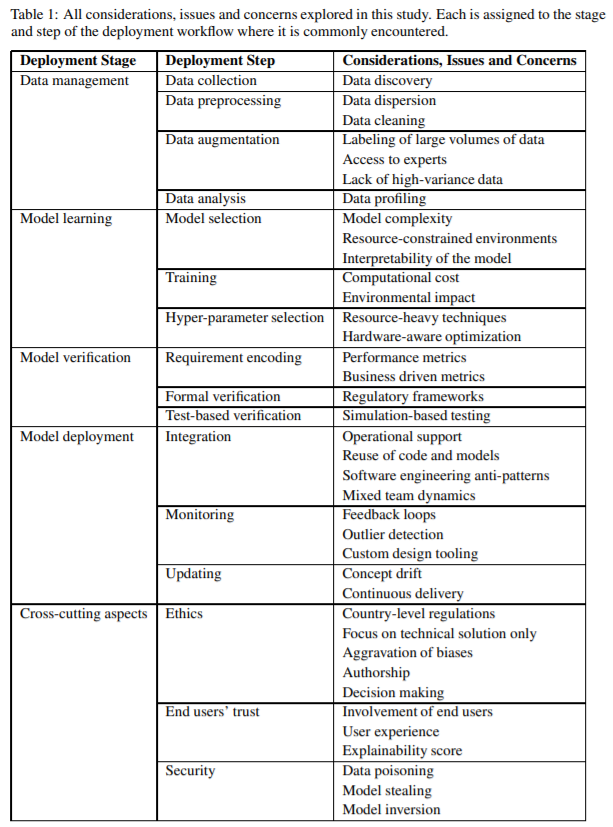
数据管理:重点是准备构建机器学习模型所需的数据。
模型学习:模型选择和训练。
模型验证:确保模型符合特定功能和性能要求。
模型部署:将训练好的模型集成到运行模型所需的软件基础架构中。此阶段还涵盖模型维护和更新的问题。
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:leetcode 开源书
在「AI算法与图像处理」公众号后台回复:leetcode,即可下载。每题都 runtime beats 100% 的开源好书,你值得拥有!
下载3 CVPR2020 在「AI算法与图像处理」公众号后台回复:CVPR2020,即可下载1467篇CVPR 2020论文 个人微信(如果没有备注不拉群!) 请注明:地区+学校/企业+研究方向+昵称

觉得不错就点亮在看吧

评论