
【机器学习】机器学习模型解释神器:Shapash
什么是 Shapash
模型可解释性和可理解性一直是许多研究论文和开源项目的关注的重点。并且很多项目中都配备了数据专家和训练有素的专业人员。Shapash 是一个 Python 库,用于描述 AI 模型的动态交互。它希望通过使 AI 模型更加直观,让使用者更加相信模型。Shapash 对全局和局部合理性进行了直接的可视化。
Shapash 适用于大多数 sklearn、lightgbm、xgboost、catboost 模型,并可用于分类和回归任务。它利用 Shap 后端来计算特征的局部贡献度,但是,这可以用其他一些计算局部贡献度的策略代替。数据科学家可以利用 Shapash 解释器对他们的模型进行调查和故障排除,或者部署以提供每个推测的可视化。并且它还可以用于制作可以为最终客户和企业家带来巨大价值的 Web 应用程序。

Shapash的目标
01 显示清晰合理的结果
绘图和输出使用每个组件及其模式的标签:
02 Web 应用程序
数据科学家可以通过使用 Web 应用程序轻松探索全局和局部邻域之间的逻辑,从而快速理解他们的模型,并了解各种关键点如何发挥作用:

03 总结并导出解释
Shapash 提出了一个简短而清晰的解释。它允许每个客户(无论他们的背景是什么),都能理解对托管模型清晰的解释,因为对 Shapash 特征进行了总结和清晰的说明。
04 完整的数据科学报告
这里有完整的数据报告可以查看:https://shapash-demo.ossbymaif.fr/
Shapash 功能
Shapash 的一些功能如下所示:
机器学习模型:它适用于分类(二元或多类问题)和回归问题。它支持多种模型,如 Catboost、Xgboost、LightGBM、Sklearn Ensemble、线性模型和 SVM。 特征编码:它支持大量的编码技术来处理我们数据集中的分类特征,如单热编码、序数编码、Base N 编码、目标编码或二进制编码等。 SklearnColumnTransformer: OneHotEncoder、OrdinalEncoder、StandardScaler、QuantileTransformer 或 PowerTransformer 可视化: 提供一组视觉效果以轻松解释你的结果,并显示可理解和清晰的结果。 它与 Lime 和 Shap 兼容。它使用 Shap 后端只需几行代码即可显示结果。 它为参数提供了许多选项,以简洁地获得结果。 Shapash 安装简单和使用方便: 它提供了一个 SmartExplainer 类来理解你的模型并用简单的语法总结澄清。 部署: 对于操作使用的调查和部署(通过 API 或批处理模式)很重要。轻松创建 Web 应用程序以从全局导航到本地。 高度通用性: 要显示结果,需要进行非常多次的争论。但如果你在清理和归档数据方面做得越多,最终客户得到的结果就越清楚。
Shapash 如何工作
Shapash 是一个使机器学习易于理解和解释的Python库。数据爱好者可以轻松理解并分享他们的模型。Shapash 使用 Lime 和 Shap 作为后端,只需几行代码即可显示结果。Shapash 依赖于构建机器学习模型以使结果合理的各种重要进展。下图显示了 shapash 包的工作流程:
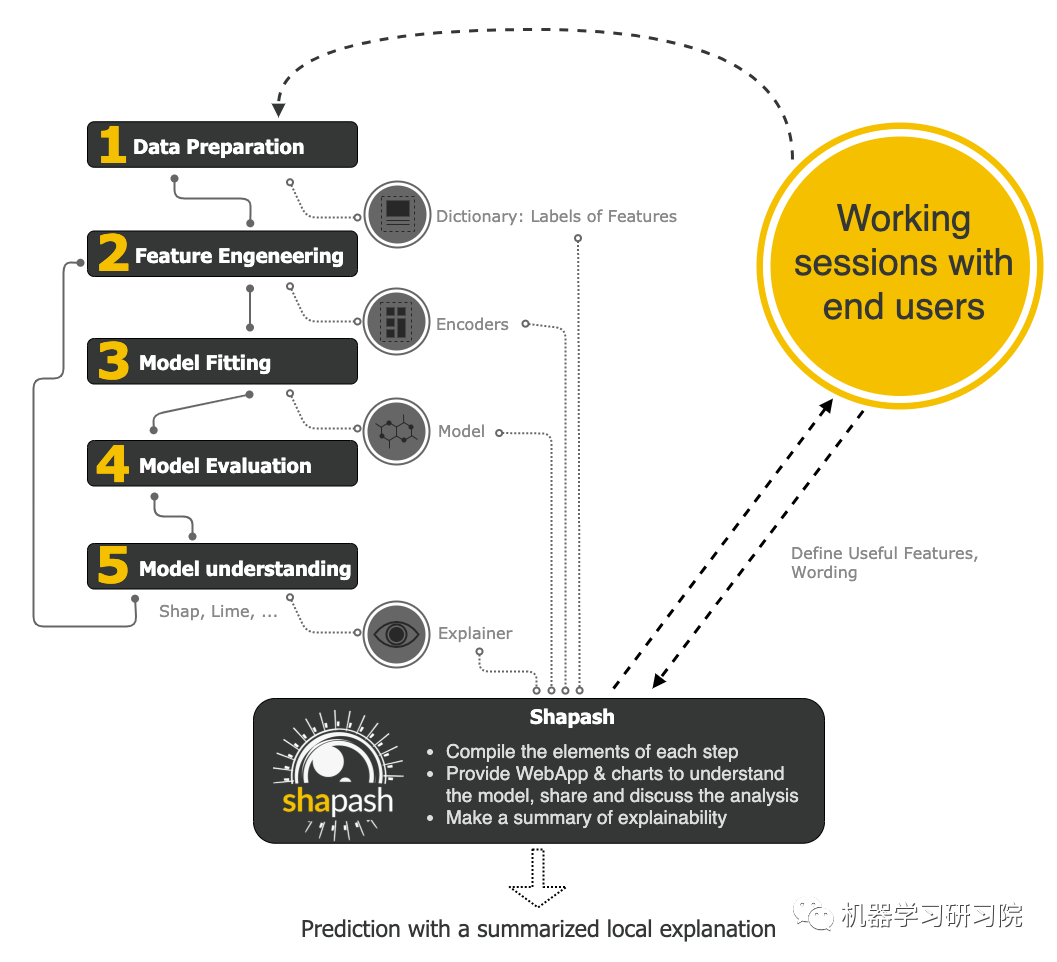
工作原理
首先,它编译每个步骤的元素,如数据准备、特征工程、模型拟合、模型评估和模型理解。 其次,它提供了一个 WebApp 和图表来更好地理解模型。可以与客户分享和讨论模型的结果。 最后,它为您提供了可解释性的摘要。
安装
可以使用以下代码安装 Shapash:
pip install shapash
对于 Jupyter Notebook: 如果你正在使用 jupyter notebook 并且想要查看内联图,那么你需要使用另一个命令:
pip install ipywidgets
入门
在这里我们将使用数据集房价预测来探索 Shapash 。这是一个回归问题,我们必须预测房价。数据集的链获取方法:在公众号『机器学习研习院』后台回复 【shapash】。首先我们分析数据集,包括单变量和双变量分析,然后使用特征重要性、特征贡献、局部和比较图对可解释性建模,然后是模型性能,最后是 WebApp。
分析数据集
单变量分析
使用可以查看下图,了解名为First Floor Square Feet的要素。我们可以看到一个表格,其中显示了我们的训练和测试数据集的多种统计数据,例如平均值、最大值、最小值、标准偏差、中位数等等。在右侧图中可以看到训练和测试数据集的分布图。Shapash 还提到了我们的特征是分类的还是数字的,它还提供了下拉选项,在下拉菜单中所有功能都可用。

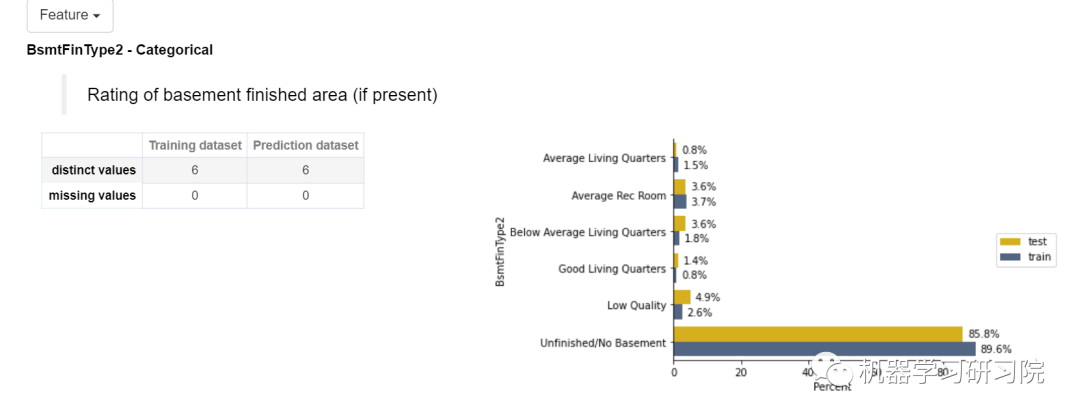
对于分类特征,训练和测试数据集显示了非重复值和缺失值。在右侧,显示了一个条形图,其中显示了各要素中相应类别的百分比。
目标分析
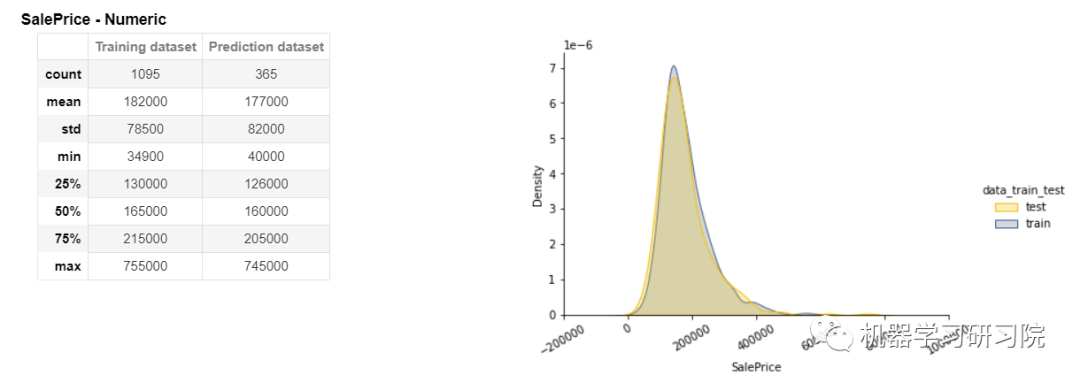
还可以看到对名为 Sales Price 的目标变量的详细分析。在左侧,显示了所有统计数据,如计数、平均值、标准差、最小值、最大值、中位数等,用于训练和预测数据集。在右侧,显示了训练和预测数据集的分布。
多元变量分析
上面我们 详细讨论了单变量分析。在本节中,我们将看到多元分析。下图显示了训练和测试数据集的前 20 个特征的相关矩阵。还根据不同的颜色显示了相关性标度。这就是我们如何使用 Shapash 可视化特征之间的关系。

模型可解释性
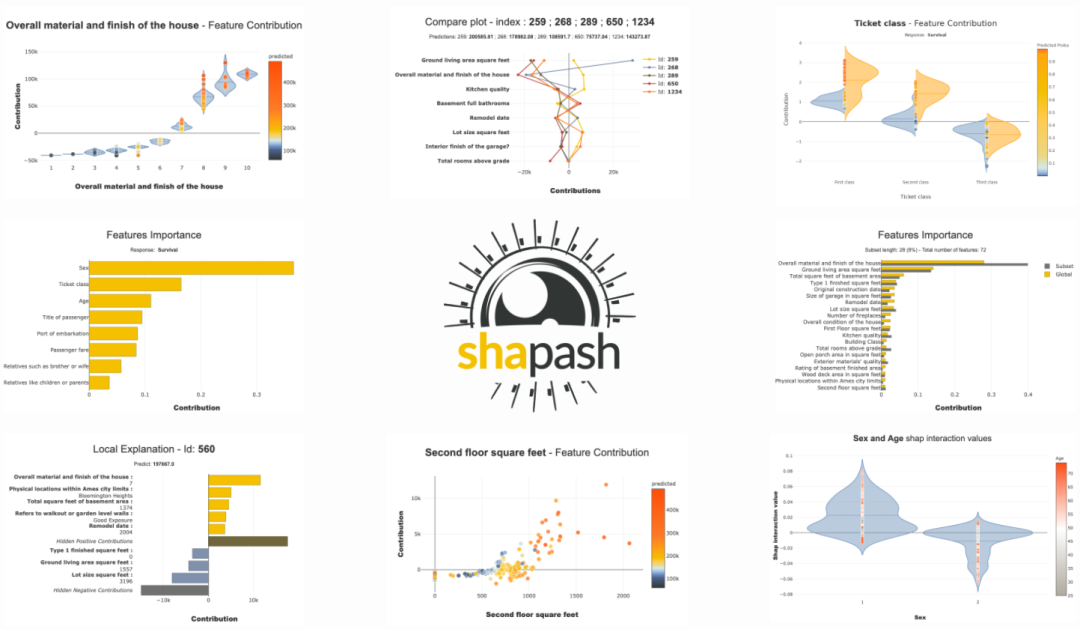
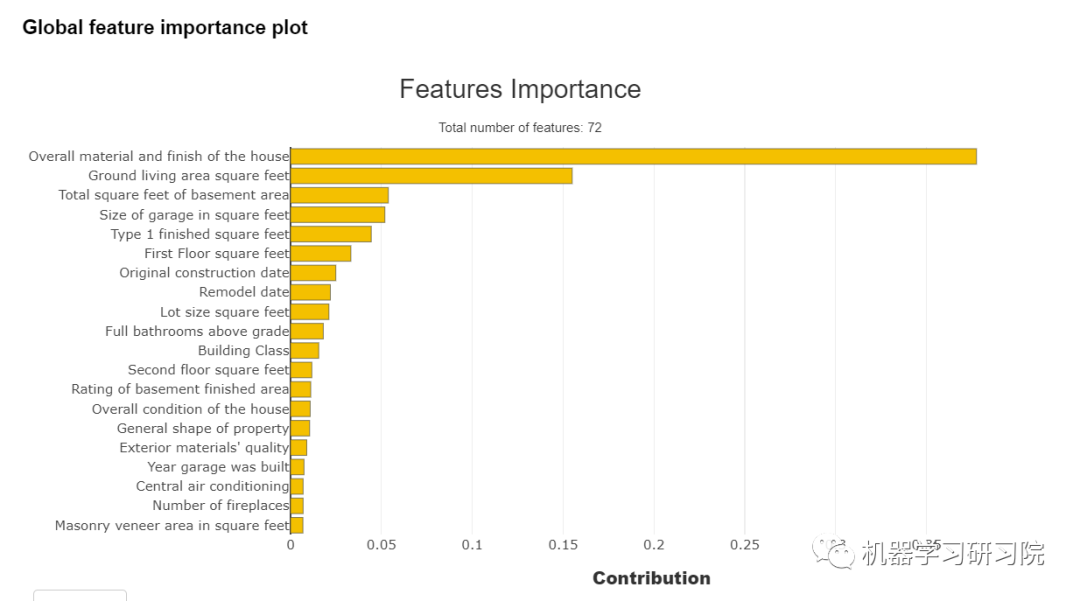
特征重要性图
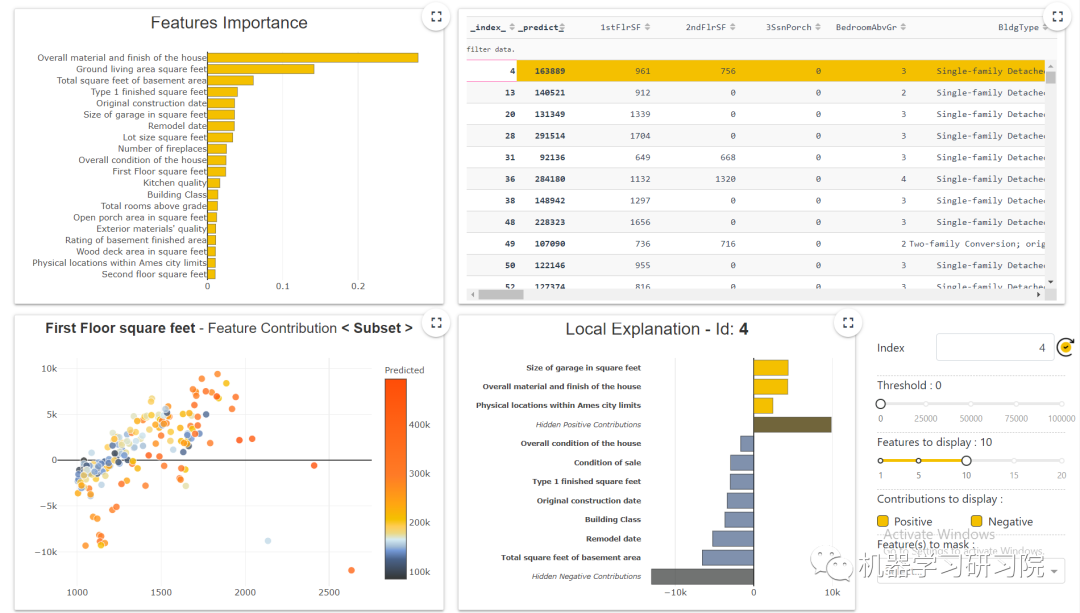
通过使用这个库,我们可以看到该特征的重要性。特征重要性是一种寻找输入特征在预测输出值中的重要性的方法。下图显示了特征重要性曲线:
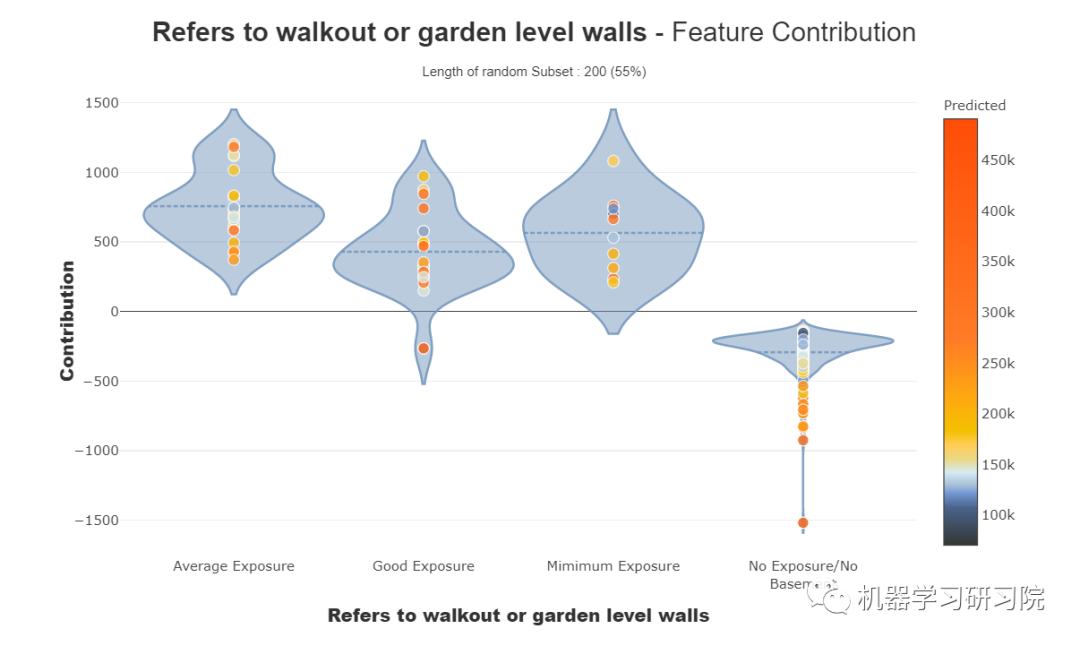
特征贡献图
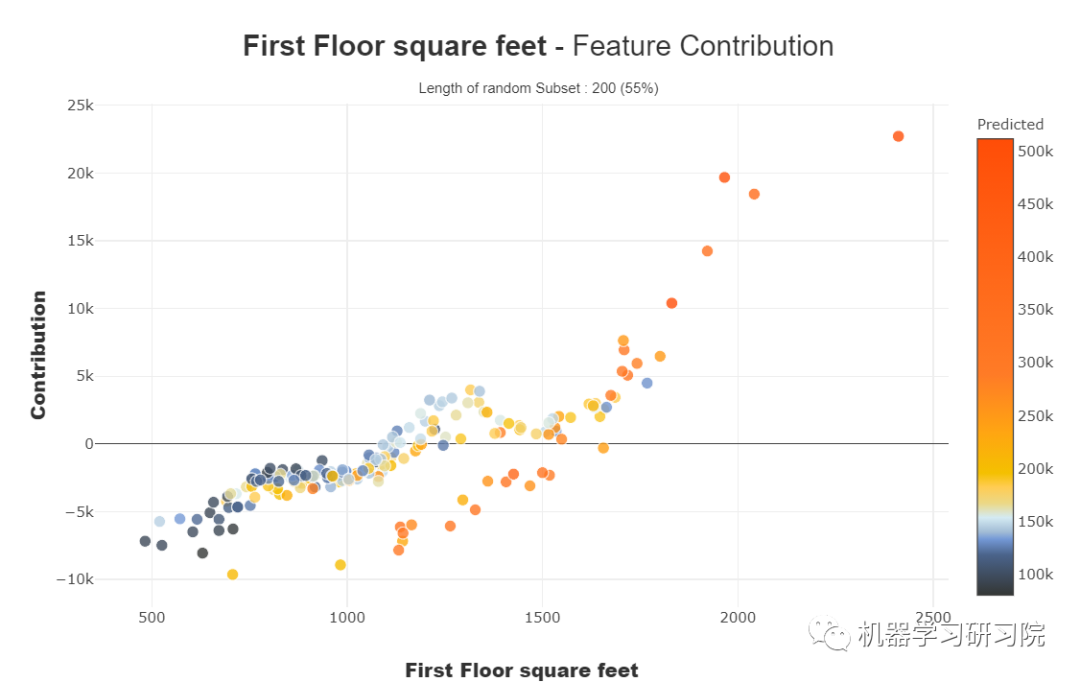
这些曲线帮助我们回答诸如特征如何影响我的预测、它的贡献是积极的还是消极的等等。这个图完成了模型的可解释性的重要性,模型的整体一致性更有可能理解特征对模型的影响。
我们可以看到数值和分类特征的贡献图。
对于数值特征
对于分类特征
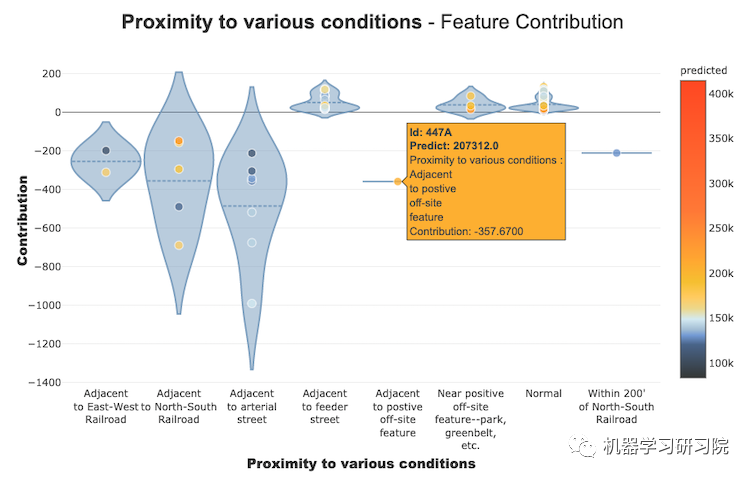
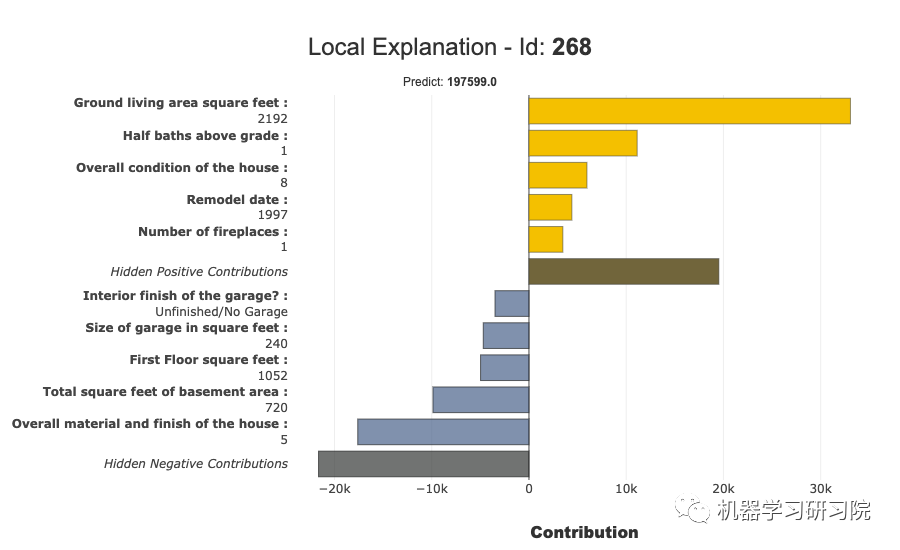
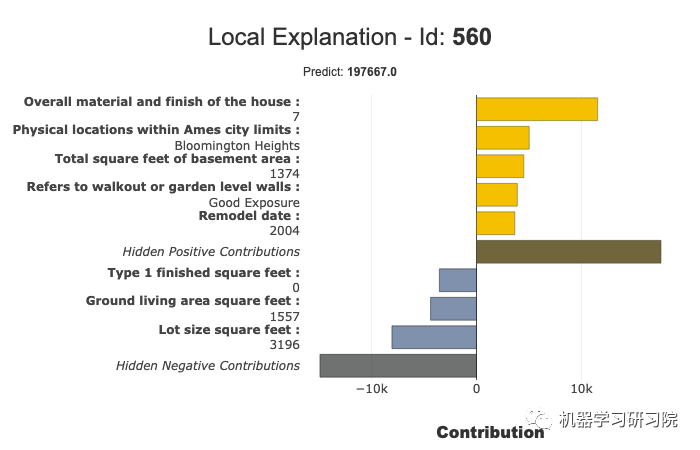
局部图
我们可以绘制局部图。下图显示了局部图:
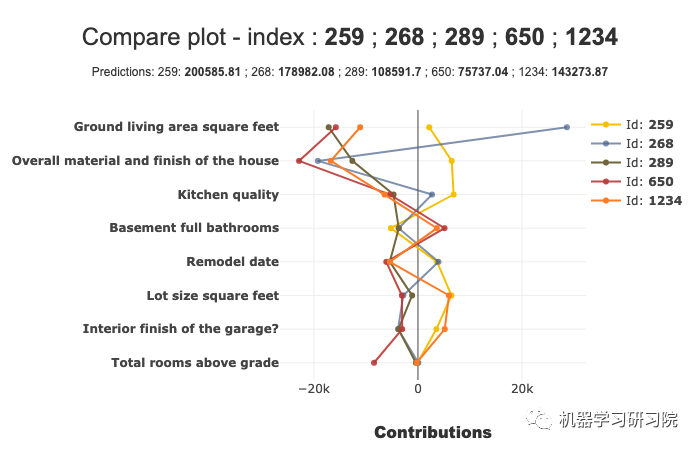
比较图
我们可以绘制比较图。下图显示了比较图:
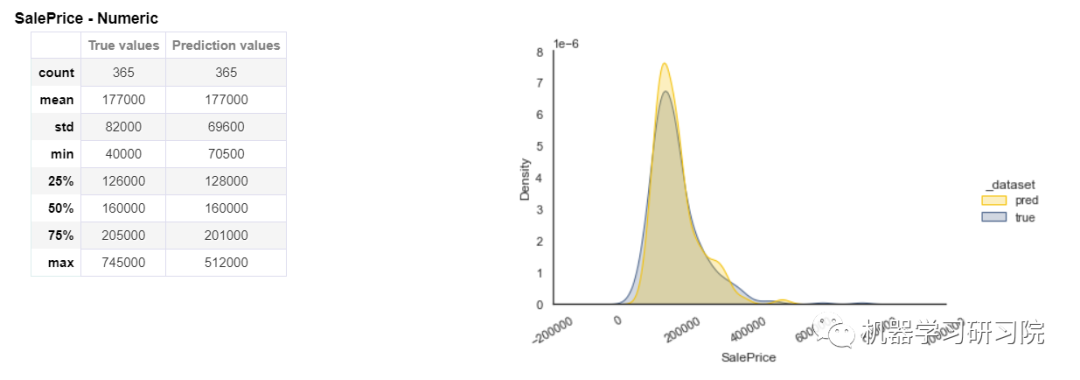
模型性能
在数据分析之后,我们正在训练机器学习模型。下图显示了我们预测的输出。在左侧,显示了真实值和预测值的统计数据,如计数、最小值、最大值、中值、标准偏差等。在右侧,显示了预测值和实际值的分布。
WebApp
经过模型训练后,我们也可以构建一个WebApp。这个网络应用程序显示了我们数据的完整仪表板,包括我们迄今为止所涵盖的内容。下图显示了仪表板。
项目地址:https://github.com/MAIF/shapash
写作最后
本篇文章简单介绍了shapash 的基本功能及绘图展示,相信大家对该python库有一定的认识。如果你还没有阅读过有关机器学习模型可解释性的shap的相关介绍,可以参阅如下两篇文章:
用 SHAP 可视化解释机器学习模型实用指南(上)
用 SHAP 可视化解释机器学习模型实用指南(下)
往期精彩回顾 本站qq群955171419,加入微信群请扫码: