
剑桥大学:机器学习模型部署都有哪些坑?
↑↑↑点击上方蓝字,回复资料,10个G的惊喜
来源:机器之心 本文约2500字,建议阅读6分钟 在生产环境中部署机器学习模型是一个复杂的过程,需要考虑诸多因素,也存在很多挑战。近日,来自剑桥的研究者梳理了该流程常见的问题。

论文地址:
https://arxiv.org/pdf/2011.09926.pdf
用例研究型论文:这类论文提供单个机器学习部署项目的经过,通常会深入讨论作者面临的每个挑战以及克服方式。 综述文章:这类文章描述了机器学习在特定领域或行业中的应用,通常总结了在所涉及领域中部署机器学习解决方案最常遇到的挑战。 经验总结型论文:作者通常会回顾他们在生产中部署机器学习模型的经验。
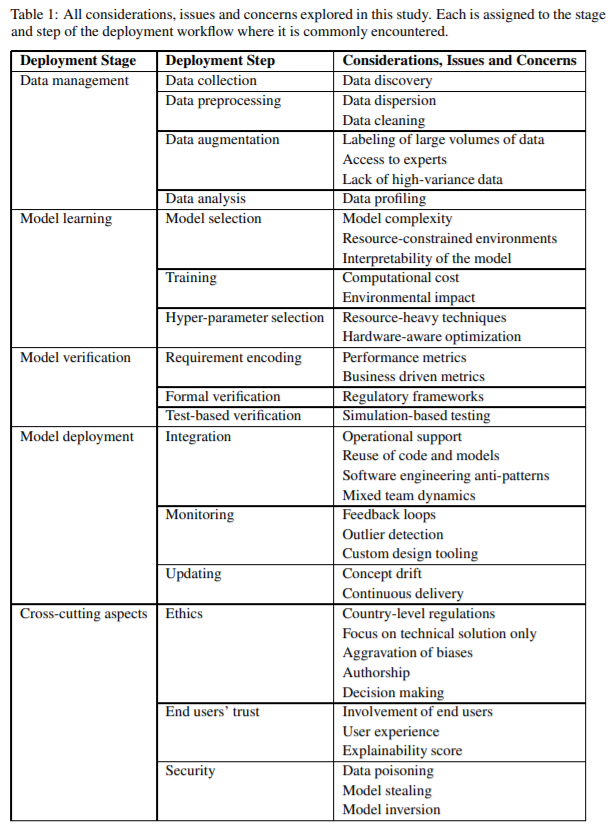
数据管理:重点是准备构建机器学习模型所需的数据。 模型学习:模型选择和训练。 模型验证:确保模型符合特定功能和性能要求。 模型部署:将训练好的模型集成到运行模型所需的软件基础架构中。此阶段还涵盖模型维护和更新的问题。
也可以加一下老胡的微信 围观朋友圈~~~
推荐阅读
(点击标题可跳转阅读)
老铁,三连支持一下,好吗?↓↓↓
评论