
【收藏】机器学习回归模型相关重要知识点总结!
回归分析为许多机器学习算法提供了坚实的基础。在这篇文章中,我们将总结 10 个重要的回归问题和5个重要的回归问题的评价指标。
一、线性回归的假设是什么?
线性:自变量(x)和因变量(y)之间应该存在线性关系,这意味着x值的变化也应该在相同方向上改变y值。 独立性:特征应该相互独立,这意味着最小的多重共线性。 正态性:残差应该是正态分布的。 同方差性:回归线周围数据点的方差对于所有值应该相同。
二、什么是残差,它如何用于评估回归模型?
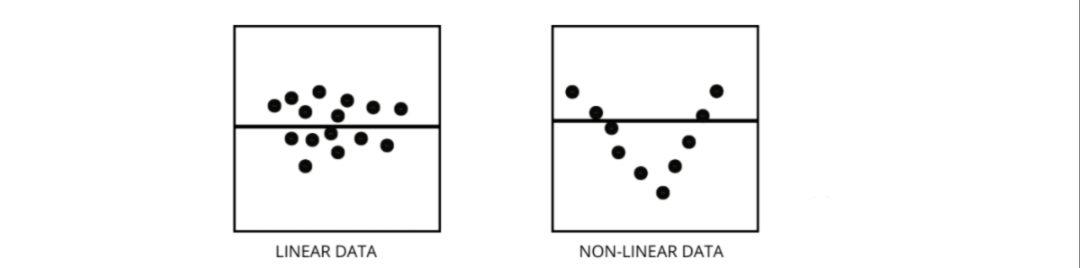
三、如何区分线性回归模型和非线性回归模型?

残差图; 散点图; 假设数据是线性的,训练一个线性模型并通过准确率进行评估。
四、什么是多重共线性,它如何影响模型性能?
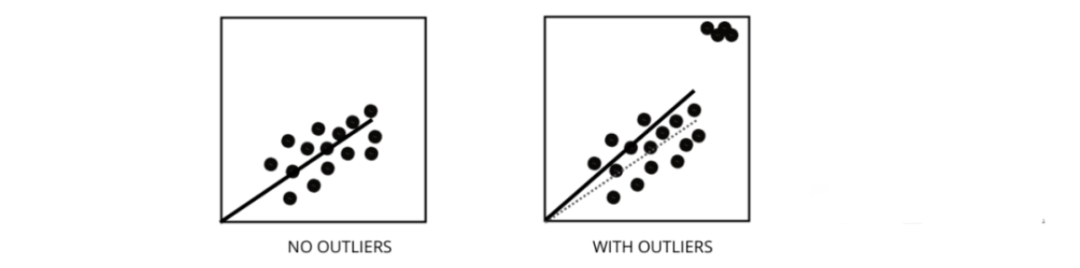
五、异常值如何影响线性回归模型的性能?
六、什么是 MSE 和 MAE 有什么区别?
七、L1 和 L2 正则化是什么,应该在什么时候使用?
八、异方差是什么意思?
九、方差膨胀因子的作用是什么的作用是什么?
十、逐步回归(stepwise regression)如何工作?
十一、除了MSE 和 MAE 外回归还有什么重要的指标吗?

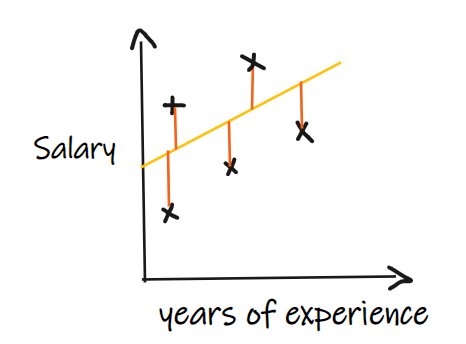
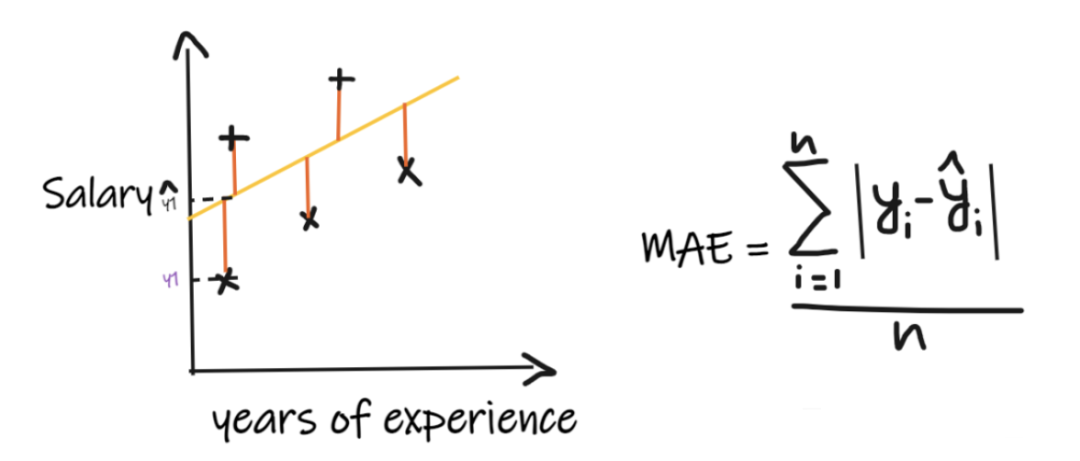
指标一:平均绝对误差(MAE)
指标二:均方误差(MSE)
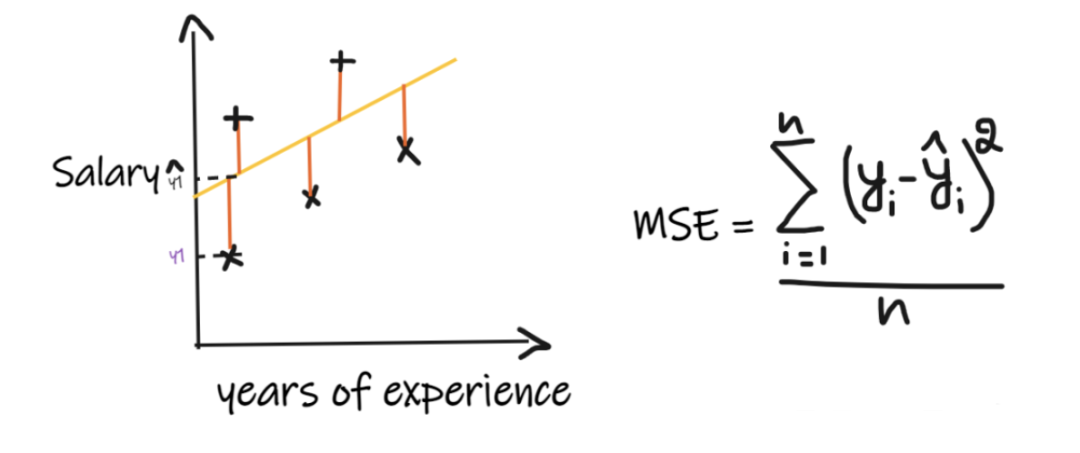
指标三:均方根误差 (RMSE)

指标四:R2 score
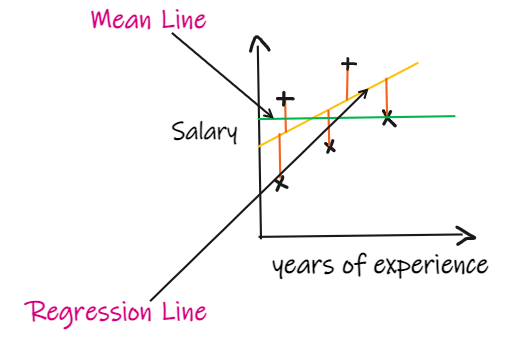
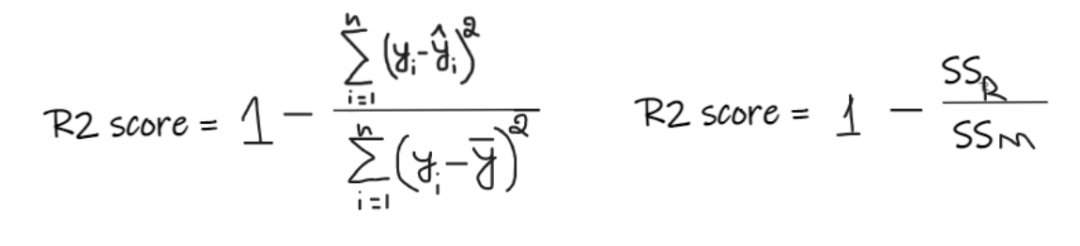
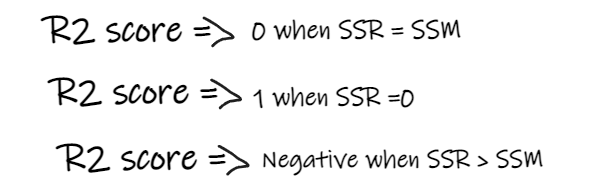
如果 R2 得分为 0,则意味着我们的模型与平均线的结果是相同的,因此需要改进我们的模型。 如果 R2 得分为 1,则等式的右侧部分变为 0,这只有在我们的模型适合每个数据点并且没有出现误差时才会发生。 如果 R2 得分为负,则表示等式右侧大于 1,这可能发生在 SSR > SSM 时。这意味着我们的模型比平均线最差,也就是说我们的模型还不如取平均数进行预测。
指标五:Adjusted R2 score


评论