
【机器学习基础】机器学习模型评估教程!
如何在投入生产前评估机器学习模型性能?

想象一下,你训练了一个机器学习模型。也许,可以从中选几个候选方案。
你在测试集上运行它,得到了一些质量评估。模型没有过度拟合,特征也有意义。总的来说,在现有的有限数据下,它们的表现尽善尽美。
现在,是时候来决定它们是否好到可以投入生产使用了。如何在标准性的质量评估外,评估和比较你的模型呢?
在本教程中,我们将通过一个案例,详细介绍如何评估你的模型。
案例:预测员工流失情况
我们将使用一个来自Kaggle竞赛的虚构数据集,目标是识别哪些员工可能很快离开公司。(数据集与代码下载,在后台回复日期"210411 "获取)
这个想法听起来很简单:有了预警,你可能会阻止这个人离开。一个有价值的专家会留在公司——无需寻找一个新的员工,再等他们学会工作技巧。
让我们试着提前预测那些有风险的员工吧!
首先,检查训练数据集。它是为方便我们使用而收集的。一个经验丰富的数据科学家会产生怀疑!我们将其视为理所当然,并跳过构建数据集的棘手部分。
我们有1470名员工的数据。
共35个特征,描述的内容包括:
员工背景(教育、婚姻状况等)。
工作细节(部门、工作级别、是否出差等)。
工作历史(在公司工作年限、最后一次晋升日期等)。
薪酬(工资、股票意见等)。
以及其他一些特征。
还有一个二元标签,可以看到谁离开了公司。这正是我们所需要的!我们将问题定义为概率分类任务。模型应该估计每个员工属于目标 "流失 "类的可能性。

在研究模型时,我们通常会将数据集分成训练和测试数据集。我们使用第一个数据集来训练模型,用其余的数据集来检查它在未知数据上的表现。
我们不详细介绍模型训练过程。这就是数据科学的魔力,我们相信你是知道的!
假设我们进行了很多次实验,尝试了不同的模型,调整了相应的超数,在交叉验证中进行了区间评估。
我们最终得到了两个合理的模型,看起来同样不错。
接下来,检查它们在测试集上的性能。这是我们得到的结果。
随机森林模型的ROC AUC值为0. 795分
梯度提升模型的ROC AUC评分为0.803分。
ROC AUC是在概率分类的情况下优化的标准指标。如果你寻找过Kaggle这个用例的众多解决方案,这应该是大多数人的做法。

我们的两个模型看起来都不错。比随机拆分好得多,所以我们肯定可以从数据中得到一些线索。
ROC AUC分数很接近。鉴于这只是一个单点估计(single-point estimate),我们可以认为性能相似。
那么问题来了,两者之间我们应该选哪个呢?
同样的质量,不同的特点
让我们更详细地分析这些模型。
我们将使用Evidently开源库来比较模型并生成性能报告。
如果你想一步一步地跟着做,可以在文末打开这个完整的upyter Notebook。
首先,我们在同一个测试数据集上训练两个模型并评估性能。
接下来,我们将两个模型的性能日志准备成两个pandas数据框(DataFrames)。每个包括输入特征、预测类和真实标签。
我们指定了列映射来来定义目标的位置,预测的类别,以及分类和数字特征。
然后,我们调用evidently tabs来生成分类性能报告。在单个的dashboard中显示两个模型的性能,以便我们可以比较它们。
comparison_report = Dashboard(rf_merged_test, cat_merged_test, column_mapping = column_mapping, tabs=[ProbClassificationPerformanceTab])
comparison_report.show()
我们将较简单的随机森林模型作为基准,对于这个工具来说,它成为 "参考(Reference)"。第二个梯度提升被表示为 "当前(Current)"的评估模型。
我们可以快速看到两个模型在测试集上的性能指标汇总。
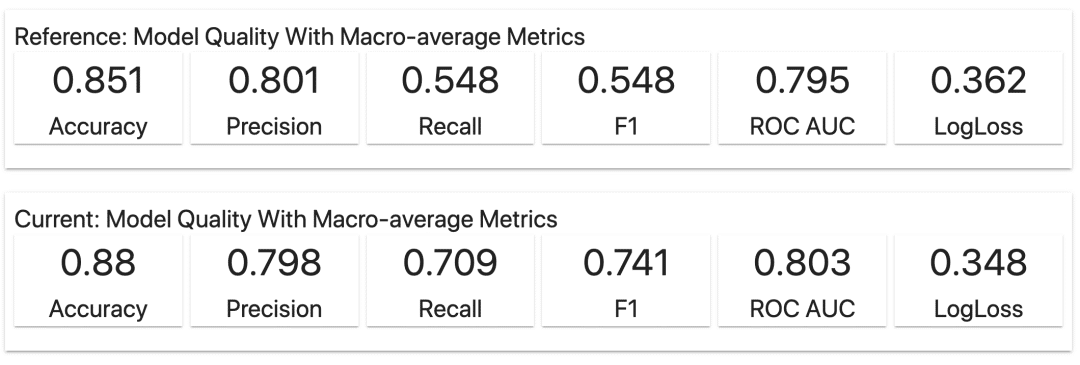
现实情况不是Kaggle,所以我们并不总是关注第二位数。如果我们只看准确率和ROC AUC,这两个模型的性能看起来非常接近。
我们甚至可能有理由去偏爱更简单的随机森林模型,源于它更强的可解释性,或者更好的计算性能。
但F1-score的差异暗示可能还有更多故事。模型的内部运作方式各不相同。
重温类别不平衡问题
精明的机器学习者知道其中的窍门。两个类别的规模远不相等。在这种情况下,准确度的衡量标准是没有太大意义的。即使这些数字可能在 "论文"上看起来很好。
目标类通常是一个次要的类。我们希望预测一些罕见但重要的事件,比如:欺诈、流失、辞职。在我们的数据集中,只有16%的员工离开了公司。
如果我们做一个朴素的模型,只是把所有员工都归类为 "可能留下",我们的准确率是84%!
ROC AUC并不能给我们一个完整的答案。相反,我们必须找到更适合预期模型性能的指标。
何谓"好的"模型?
你知道其中的答案:这要视情况而定。
如果一个模型能简单地指出那些即将辞职的人,并且永远是对的,那就太好了。那么我们就可以做任何事情了!一个理想的模型适合任何用例——但这往往不会在现实中出现。
相反,我们处理不完美的模型,使它们对我们的业务流程有用。根据应用,我们可能会选择不同的标准来评估模型。
没有一个单一的衡量标准是理想的。但模型并不是存在于真空中——希望你可以从提出问题开始!
让我们考虑不同的应用场景,并在此背景下评估模型。
示例1:给每个员工贴标签
在实践中,我们可能会将该模型集成到一些现有的业务流程中。
假设我们的模型用于在内部人力资源系统的界面上显示一个标签,我们希望突出显示每个具有高损耗风险的员工。当经理登录系统时,他们将会看到部门中每个人的 "高风险"或 "低风险"标签。
我们希望为所有员工显示标签。我们需要的模型尽可能的 "正确"。但我们知道,准确度指标隐藏了所有重要的细节。我们将如何评估我们的模型呢?
超越准确度
让我们回到evidently的报告中,更深入地分析两种模型的性能。
我们能够很快注意到,两个模型的混淆矩阵看起来是不同的。
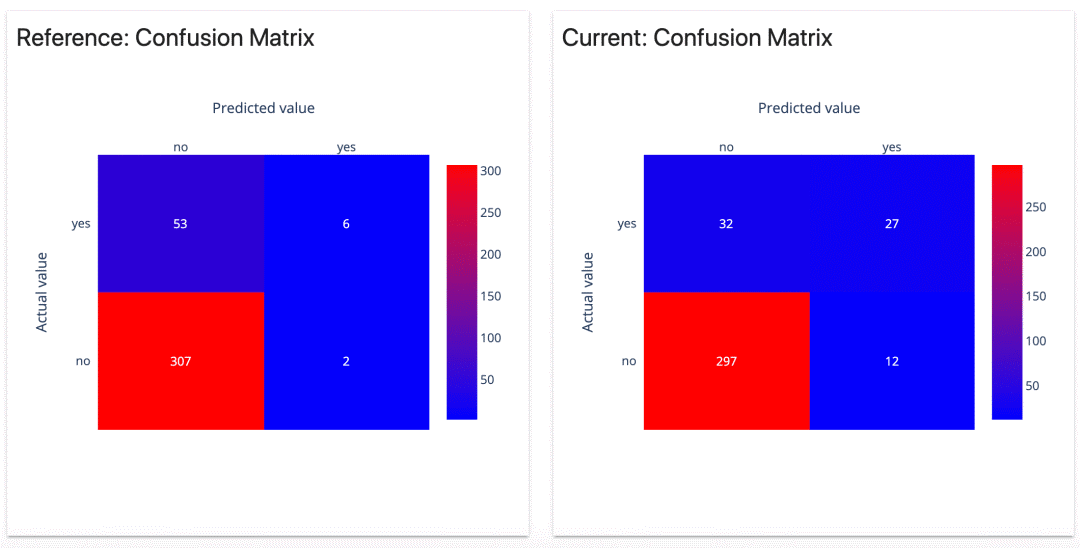
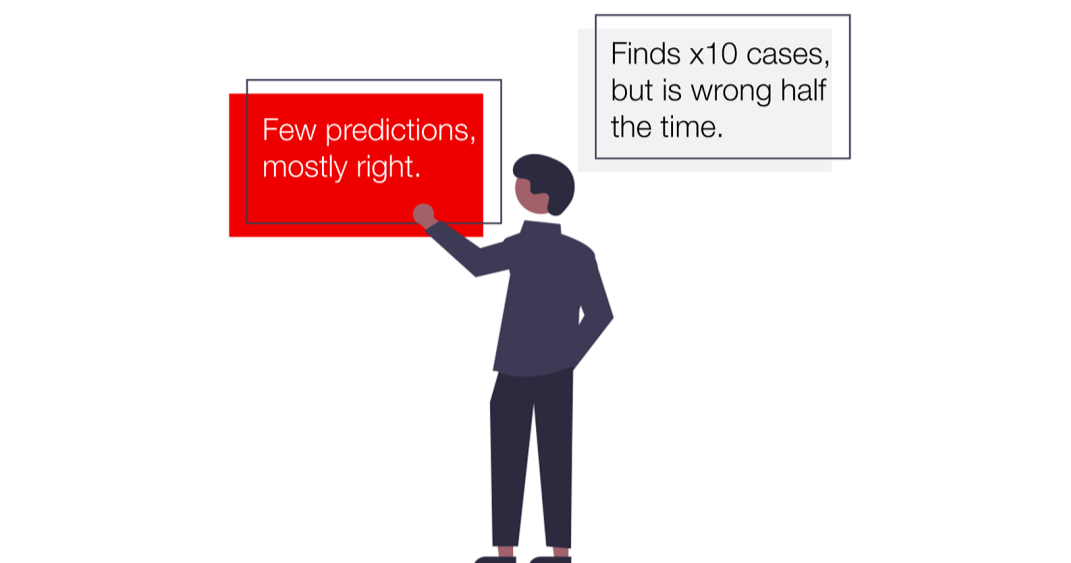
我们的第一个模型只有两个假阳性(false positives)。听起来很不错?的确,它没有给我们太多关于潜在辞职的错误提醒。
但是,另一方面,它只正确识别了6次辞职。其他的53个都被漏掉了。
第二个模型错误地将12名员工标记为高风险。但是,它正确预测了27个辞职。它只漏掉了32人。
按类别划分的质量指标图总结了这一点。让我们看看 "yes"类别。

但第二个模型在召回率中胜出!它发现45%的人离开了公司,而第一个模型只有10%。
你会选择哪个模型呢?
最有可能的是,在目标 "辞职"类别中,召回率较高的那一个会赢。它可以帮助我们发现更多可能离职的人。
我们可以容忍一些假阳性,因为解释预测的是经理。人力资源系统中已有的数据也提供了额外的背景。
更有可能的是,在其中增加可解释性是必不可少的。它可以帮助用户解释模型预测,并决定何时以及如何做出反应。
总而言之,我们将基于召回率指标来评估我们的模型。作为一个非ML标准,我们将添加经理对该功能的可用性测试。具体来说,要把可解释性作为界面的一部分来考虑。
示例2:发送主动警报
让我们想象一下,我们期望在模型上有一个特定的行动。
它可能会与同一个人力资源系统进行整合。但现在,我们将根据预测发送主动通知。
也许,给经理发送一封电子邮件,提示安排与有风险的员工会面?或者是对可能的留用环节提出具体建议,比如额外的培训等等。

在这种情况下,我们可能对这些假阳性有额外的考虑。
如果我们过于频繁地给经理们发送邮件,他们很可能会被忽略。不必要的干预也可能被视为一种负面结果。
我们该怎么办?
如果没有任何新的有价值的功能可以添加,我们就只能使用现有的模型。我们无法榨取更多的精度。但是,可以限制采取行动的预测数量,目标是只关注那些预测风险较高的员工。
精度-召回率权衡
概率模型的输出是一个介于0和1之间的数字,为了使用预测,我们需要在这些预测的概率上分配标签。二元分类的 "默"方法是以0.5为切入点。如果概率较高,标签就是 "yes"。
我们可以选择一个不同的阈值,也许,0.6甚至0.8?通过设置更高的阈值,我们将限制假阳性的数量。
但这是以召回率为代价的:我们犯的错误越少,正确预测的数量也越少。
这个来自evidently报告的类别分离图(Class Separation)让这个想法非常直观。它在实际标签旁边显示了各个预测概率。
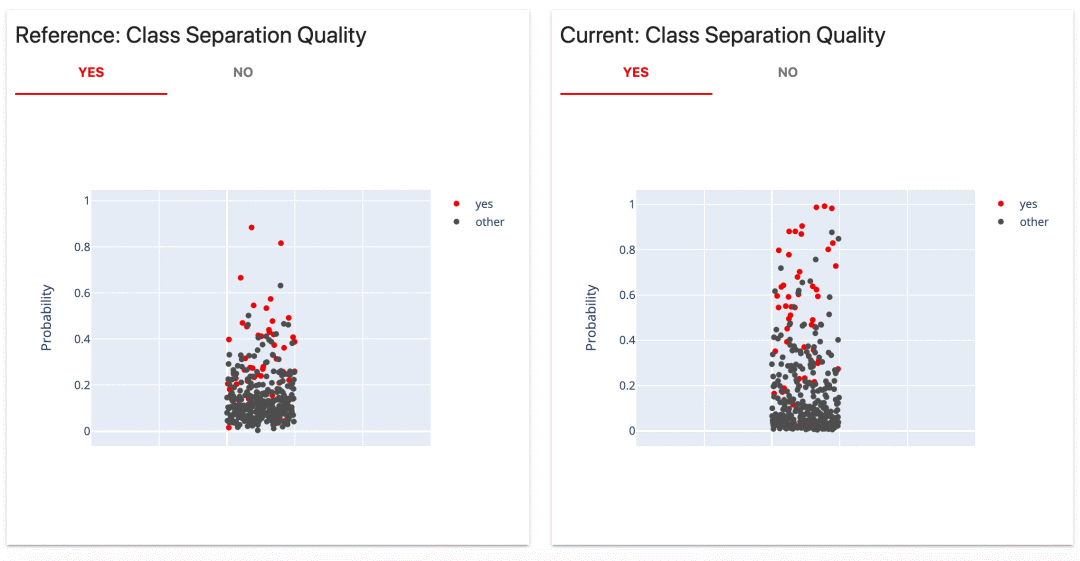
我们可以看到,第一个模型做出了几个非常自信的预测。稍微 "上调"或 "下调"阈值,在绝对数字上不会有太大的差别。
然而,我们可能会欣赏一个模型,并挑选出几个具有高置信度的案例的能力。例如,如果我们认为假阳性的成本非常高。在0.8处做一个分界点,就能得到100%的精度。我们只做两个预测,但都是正确的。
如果这是我们喜欢的行为,我们可以从开始就设计这样一个 "决定性 "的模型,它将强烈地惩罚假阳性,并在概率范围的中间做出较少的预测。(事实上,这正是我们在这个演示中所做的!)。
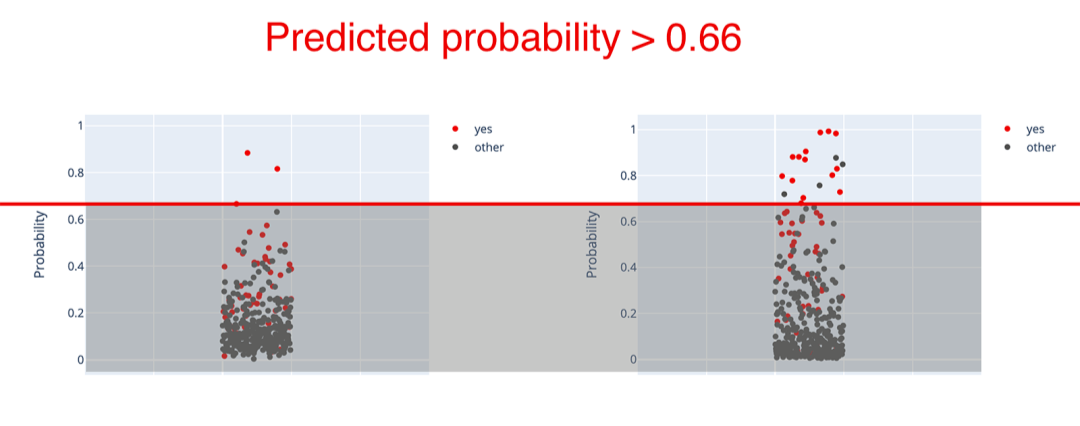
第二个模型的预测概率比较分散。改变阈值会产生不同的情况。我们只需看一下图示,就能做出大致的估计。例如,如果我们将阈值设置为0.8,就会让我们只剩下几个假阳性。
更具体地说,让我们看看精度-召回表。它旨在类似情况下选择阈值。它显示了top-X预测的不同情况。

例如,我们可以只对第二个模型的前5%的预测采取行动。在测试集上,它对应的概率阈值为66%。所有预测概率较高的员工都被认为有可能离职。
在这种情况下,只剩下18个预测。但其中14个将是正确的!召回率下降到只有23.7%,但现在的精度是77.8%。我们可能更喜欢它,而不是原来的69%精度,以尽量减少误报。
为了简化概念,我们可以想象一下类别分离图上的一条线。
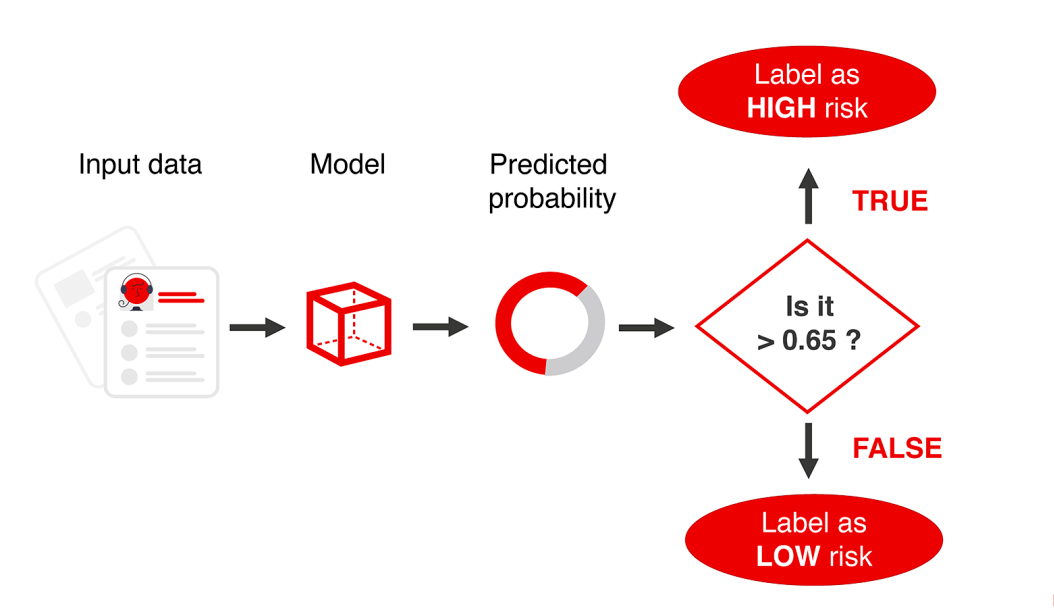
在实践中,我们可以通过以下两种方式之一进行限制:
只对topX预测采取行动
将所有概率大于 X 的预测分配给正类。
第一种方案可用于批量模型。如果我们一次生成所有员工的预测,我们可以对它们进行分类,比如说,前5%。
如果我们根据要求进行个别预测,那么选取一个自定义的概率阈值是有意义的。
这两种方法中的任何一种都可以工作,这取决于具体用例。
我们也可以决定用不同的方式来可视化标签。例如,将每个员工标记为高、中、低流失风险。这将需要基于预测概率的多个阈值。
在这种情况下,我们会额外关注模型校准的质量,这一点从类别分离图上可以看出。
综上所述,我们会考虑精度-召回率的权衡来评估我们的模型,并选择应用场景。
我们不显示每个人的预测,而是选择一个阈值。它帮助我们只关注流失风险最高的员工。
示例3:有选择地应用模型
我们还可以采取第三种方法。
当看到两个模型的不同图谱时,一个明显的问题出现了。图上的小点背后的具体员工是谁?两种模型在预测来自不同角色、部门、经验水平的辞职者时有什么不同?
这种分析可能会帮助我们决定什么时候应用模型,什么时候不应用模型。如果有明显的细分市场,模型失效,我们可以将其排除。或者反过来说,我们可以只在模型表现好的地方应用模型。
在界面中,我们可以显示 "信息不足 "这样的内容。这可能比一直错误要好!

低性能部分
为了更深入地了解表现不佳的片段,我们来分析一下分类质量表(Classification Quality Table)。对于每个特征,它将预测的概率与特征值一起映射。
这样,我们就可以看到模型在哪些方面犯了错误,以及它们是否依赖于单个特征的值。
我们举个例子。
这里有一个工作等级(Job Level)特征,它是角色资历的特定属性。

如果我们对1级的员工最感兴趣,那么第一个模型可能是一个不错的选择!它能以高概率做出一些有把握的预测。例如,在0.6的阈值下,它在这个群体中只有一个假阳性。
如果我们想预测3级的辞职情况,第二个模型看起来要好得多。
如果我们希望我们的模型对所有级别都有效,我们可能会再次选择第二个模型。平均而言,它在1、2、3级中的表现可以接受。
但同样有趣的是,这两个模型在第4级和第5级上的表现**。**对这些群体中的员工做出的所有预测,概率都明显低于0.5。两种模型总是分配一个 "负"的标签。
如果我们看一下真实标签的分布,我们可以看到,在这些工作级别中,辞职的绝对数量相当低。很有可能在训练中也是如此,模型并没有发现任何有用的模式。
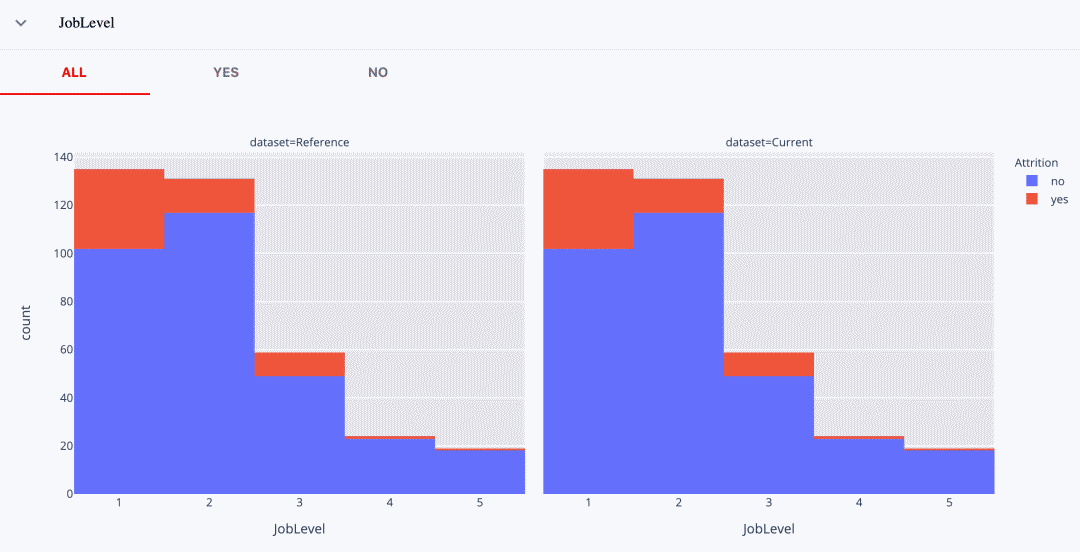
由于我们比较的是同一测试数据集上的性能,所以分布是相同的。
如果我们要在生产中部署一个模型,我们可以构建一个简单的业务规则,将这些片段(segments)从应用中排除。
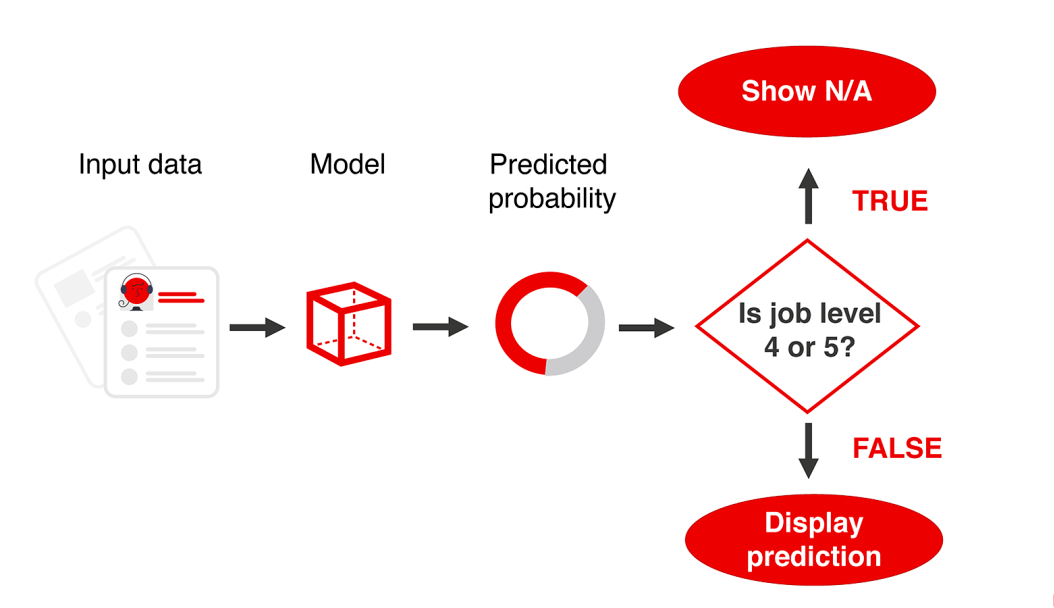
我们也可以利用这个分析的结果,把我们的模型放在一个 "性能改进计划"上。也许,我们可以添加更多的数据来帮助模型。
例如,我们可能有一些 "旧的"数据,而这些数据是我们最初从训练中排除的。我们可以有选择地增强训练数据集,用于表现不佳的部分。在这种情况下,我们会添加更多关于4级和5级员工辞职的旧数据。
综上所述,我们可以识别出模型失败的特定细分片段,我们仍然显示出对尽可能多的员工的预测。但知道模型远非完美,我们只对表现最好的那部分员工进行应用。
模型知道什么?
这张表同样可以帮助我们更详细地了解模型的行为。我们可以探索误差、离群值,并了解模型的学习情况。
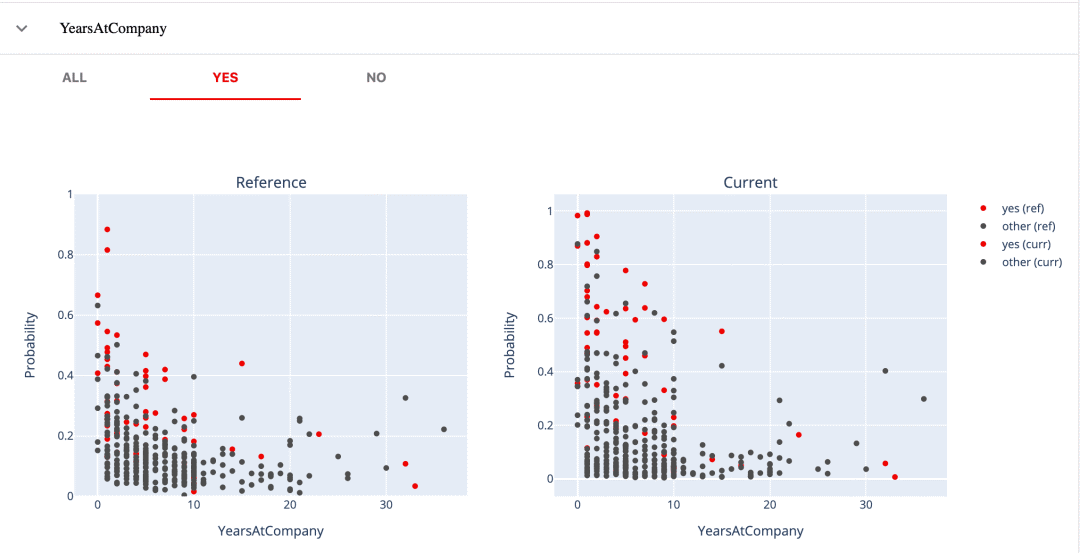
例如,我们已经看到,第一个模型只预测了少数有把握的辞职。第二个模型从我们的数据中 "捕捉"到了更多有用的信号。它是从哪里来的呢?
如果通过我们的特征,可以得到一个提示。
比如说,第一个模型只成功预测了那些相对新进公司的人的辞职,第二个模型可以检测出有10年以下工作经验的潜在离职者。我们可以从这个图中看到。
我们可以从股票期权等级(stock options level)中看到类似的情况。
第一个模型只成功预测了0级的员工。即使我们有不少重新加入的员工,至少也是1级的!第二种模型捕获到了更多等级较高的离职者。

但如果我们看加薪(即最近的加薪),我们会发现没有明显的细分,无论哪个模型的效果都更好或更差。
除了第一种模型的一般特征外,并没有具体的 "倾斜",做出较少的置信预测。

类似的分析可以帮助在模型之间进行选择,或者找到改进模型的方法。
就像上面工作级别的例子一样,我们可能有办法来增强我们的数据集。我们可能会添加其他时期的数据,或者包含更多的特征。在类别不平衡的情况下,我们可以尝试给特定例子更多的权重。作为最后的手段,我们也可以添加业务规则。
我们找到了赢家!
回到我们的例子:第二种模式是大多数情况下的赢家。

但谁会只看ROC AUC就被信服了呢?我们必须超越单一的指标来深入评估模型。
它适用于许多其他用例。性能比准确度更重要。而且并非总是可以为每种错误类型分配简单的"成本"来对其进行优化。像对待产品一样对待模型,分析必须更加细致入微。
关键是不要忽视用例场景,并将我们的标准与之挂钩。可视化可能有助于那些不以ROC AUC思考的业务相关者进行沟通。
提示:本教程不用于辞职预测,而是模型分析
如果你想解决类似的用例,我们至少要指出这个数据集的几个限制。
我们缺乏一个关键的数据点:辞职的类型。人们可以自愿离职、被解雇、退休、搬到全国各地等等。这些都是不同的事件,将它们归为一类可能会造成模糊的标签。如果把重点放在 "可预测"的辞职类型上,或者解决多类问题来代替,会比较合理。
关于所从事的工作,没有足够的上下文。一些其他数据可能会更好地表明流失情况:绩效评估、特定项目、晋升规划等。这种用例需要与领域专家一起精心构建训练数据集。
没有关于时间和辞职日期的数据。我们无法说明事件的顺序,并与公司历史上的特定时期有关。
最后提醒一点:像这样的用例可能是高度敏感的。
你可能会使用类似的模型来预测一线人员的流动率。目标是预测招聘部门的工作量和相关的招聘需求。不正确的预测可能会导致一些财务风险,但这些很容易考虑进去。
但如果该模型用于支持对单个员工的决策,其影响可能会更加关键。例如,考虑分配培训机会时的偏差。我们应该评估使用案例的道德规范(the ethics of the use case),并审核我们的数据和模型是否存在偏见和公平(bias and fairness)。
参考链接:
本文所用数据集地址:https://www.kaggle.com/pavansubhasht/ibm-hr-analytics-attrition-dataset Evidently开源库:https://github.com/evidentlyai/evidently Jupyter notebook地址:https://github.com/evidentlyai/evidently/blob/main/evidently/examples/ibm_hr_attrition_model_validation.ipynb 原文地址:https://evidentlyai.com/blog/tutorial-2-model-evaluation-hr-attrition
往期精彩回顾
本站qq群851320808,加入微信群请扫码: