
ICCV 2021 | 悉尼大学&商汤提出GUPNet:单目3D目标检测新网络
点击下方卡片,关注“新机器视觉”公众号
视觉/图像重磅干货,第一时间送达
本文是我们ICCV2021的工作,作为白菜的渣作还是硬着头皮来宣传啦。本文目的在于讲解我们原始的motivation,可能会有部分与原始论文不同的视角,希望可以方便大家理解以及节省大家阅读正文的时间。
摘要:几何投影是单目3D物体检测任务中一种强大且常见的深度估计方法。它根据估计的物体高度导出深度,这使得数学先验被引入到深度估计模型中。但是,该过程同样引入了误差放大问题,其输入的物体高度存在的估计误差会被放大,并加大反映在输出端的深度数值上。这种特性导致深度推断具有不可控性,并且还会损害模型的训练效率。
在本文中,我们提出了一个几何不确定性投影网络 (GUP Net) 来尝试解决误差放大效应在推理和训练阶段带来的负面影响。具体来说,我们提出了 GUP 模块来获得推断深度的基于几何的不确定性,其为每个深度提供高度可靠的置信度,其不仅有利于推理阶段的得分计算,而且有利于模型的学习。
此外,在训练阶段,我们提出了一种分层任务学习策略来减少误差放大引起的不稳定性。该学习算法通过监控每个任务的学习情况来动态地给每个任务分配不同的学习权重。每个任务的训练的多少取决于其前置任务的训练情况,该方案可以显着提高训练过程的稳定性和效率。
实验证提出的方法可以推断出比现有方法更可靠的物体深度数值,并且表现优于最先进的基于图像的单目 3D 检测器约3.74%和4.7%的性能(在KITTI数据集的汽车和行人类别上的AP40性能)。
作者介绍:陆岩,悉尼大学工程学博士生,研究方向为多模态数据处理,3D计算机视觉。

http://arxiv.org/abs/2107.13774
代码链接(即将开源):
https://github.com/SuperMHP/GUPNet
(1) 什么是单目3D物体检测:3D物体检测是一个体系很大的计算机视觉任务。它的主要目标为从输入信号中估计出物体的位置,大小以及方位角,其数学形式为:
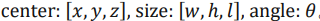
而根据输入信号的不同,我们可以讲3D物体检测进行如下分类:以图像和激光雷达点云共同作为输入的多模态3D物体检测,输入多张图片的多目3D物体检测,仅输入激光雷达的点云3D物体检测以及仅输入单张图像的单目3D物体检测。
链接:https://zhuanlan.zhihu.com/p/106170250
(2) 单目3D物体检测在做什么以及潜在的问题:本文要处理的问题为单目3D物体检测(下文简称mono3Ddet)问题。这个任务相比于传统的3D物体检测而言,其本质是个病态问题(ill-posed),所以获得真正精确的depth从理论上就有极大的困难。总得来说,这个任务的难度比以往的标准3D物体检测以及2D物体检测都要高一些,其问题的根源在于depth的不适定,所以现阶段的主流工作均在解决depth估计的问题,本文也并不例外。
(3) 单目3D物体检测的核心难点是景深计算(Depth estimation):在mono3Ddet所有的7DoF参数中,z (depth)是引起性能低下的根本原因,虽然诸如size与angle也是病态的估计问题,但是他们对mono3Ddet的质量下降其实贡献并不多,这一点已经被AM3D等工作证明过[4][5]。
(4) 单目3D检测中投影模型是一种很常见的引入几何信息的方法:几何投影模型是一种最常见的depth prior,也就是说我们在估计depth的时候,可以通过以下关系得到:
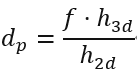
其中f是相机焦距,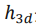 是物体的3D高度,
是物体的3D高度,是物体的2D高度。在该关系下,depth估计可以转化为先估计
与,再通过投影的方式得到,这种做法也在诸多3D物体检测中得以验证,是一种有效的引入depth先验知识的策略。
(5) Score是提高单目3D检测性能的重要途径之一:过去有不少mono3Ddet的方法忽略了3D score对结果的影响,例如pseudo lidar的AM3D和PatchNet。它们都使用了前端2D score作为自己的最终3D检测得分,而诸如MonoDis这类使用了得分的方法,往往并没有在paper里强调3D得分的作用,这种make sense的做法可能会被大家忽略,实际上在mono3Ddet里,Score是极为重要的东西,因为检测类算法最终的评估指标是AP而不是Acc,所以,单纯地“做对”一定数量的样本是没有用的,只有高得分样本做对才有用。
那么回到本文,本文所要解决的问题其实是投影模型中的误差放大(error amplification)现象,这里定性地说明下什么是误差放大,也即输入(前端估计的高度)的误差会被乘倍数的放大并在输出端(计算出的depth)。例如我们对投影模型的输入加入一个微小的偏置,其输出则会变成原始的投影结果与偏置项引发的depth误差的和:
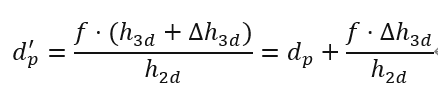
那么这一项直接看不够直观,实际上我们对该式子进行了定量地测试,我们将设置为0.1(一个不算大的误差)。然后观察这样一个0.1的偏置对depth结果会产生多大的抖动,结果如下:
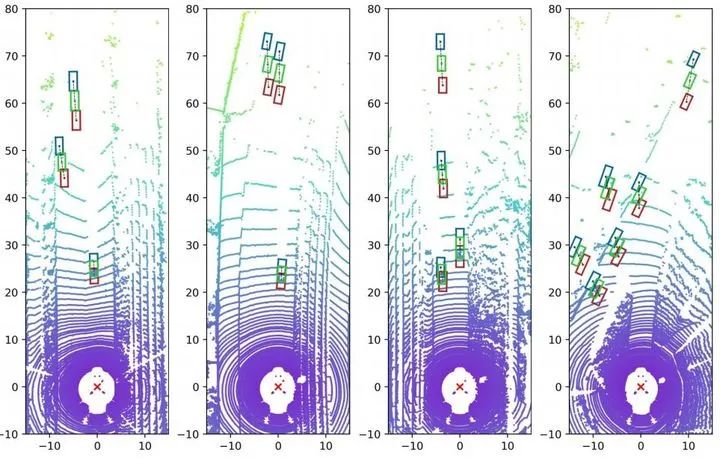
图1. 绿色的框代表原始投影结果,蓝色与红色框对应加入0.1的bias后的投影结果
可以看出,0.1的偏差引入的误差对于iou要求在0.7以上的3D物体检测而言是比较大的。其最大甚至可以引入几米的误差。那么这样一个事情会带来哪些危害呢?我们认为:使得depth的估计不确定性高,也即其输出可靠性差。输出可靠性差会使得其得分/不确定性难以预测。那么这件事会对物体检测产生训练与测试两个方面的不同影响。
1). 对于测试而言(Inference Stage),在前文我说明了一个结论:好的高质量的得分是AP高的必要条件。而误差放大引起的不稳定性会使得高品质的得分的非常难以获得,因为实际在3D物体检测中,大部分情况下,获得得分的途径是使用神经网络进行端到端回归(例如直接预测每个box的IOU value或者对每个box预测uncertainty),其本质上是要求神经网络可以根据输入特征对当前物体的检测难度进行一个动态的评估。这里给出一个具体的例子说明这个问题:
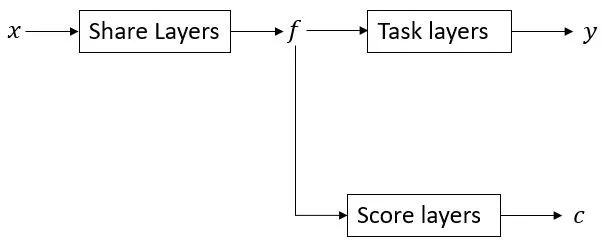
图2. 常见的uncertainty estimation pipeline
任何种类的mono3Ddet模型都可以拆成上图的样子,其中task layers对应与task相关的节点。而score layers则对应与得分相关的节点,其输出 c 为得分,一般使用不确定度loss训练或者使用iou loss[1]训练等。可以想象,从input x 上直接估计出得分显然是个病态问题,因为最终得分对于输入而言是一个不可知(agnostic)的量,因此,我们认为,得分估计问题可以等价于对输入特征进行难度估计。然而,因为几何投影模型引入的误差放大效应的存在,使得这件事情的难度大幅提高。特征层面一个及其微弱的扰动会使得depth估计结果抖动极大,因此得分估计这件事就变成了:push神经网络去对特征微小的抖动进行区分。如下图:
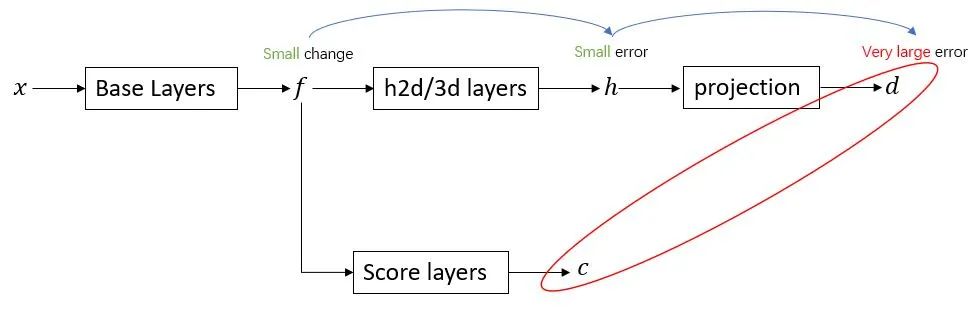
图3. error amplification给score估计带来的问题
举例来说,假设feature f 可以产生一个很好的depth估计结果,此时神经网络需要Score layers的输出可能拉高,以反应其回归的高质量。然而假设存在对于一个微小的扰动使得feature f 产生了一个很小的波动,其同样引起了 h 的一个很小的扰动,这个扰动从数值上看可能微不足道,但是它却被投影模型放大从而产生了非常巨大的depth偏移(例如0.01的 h 的扰动可能引起0.5m的depth偏移,但这足以使得iou暴降),此时却要求神经网络给出很低的得分,因此得分估计变得较为困难。而且除此以外,在现有的单目3d物体检测方法中,得分也即uncertainty,往往也是训练loss的一部分,因此得分质量差会对训练和测试均产生不同程度的影响。
2). 除此以外,对于训练而言,误差放大会使得depth的训练在前期较为不稳定,因为在前期,模型对于高度的预测是非常糟糕的,这时候就会在depth输出端产生极其巨大的输出扰动,对整个模型产生影响。
所以,面对这两个问题,我们提出了基于不确定度的几何投影模型(Geometry Uncertainty Projection Network,下文简称GUPNet)。
本节我将重点讲解原始论文GUP module以及HTL的部分,其他部分大家可以参考原文。首先,我们的baseline是CenterNet的魔改版本,具体细节等价于MonoPair删除Pair relation后剩余的部分,大家可以参考MonoPair的原文,此处不在赘述。在这里我先给出我们的网络框架:
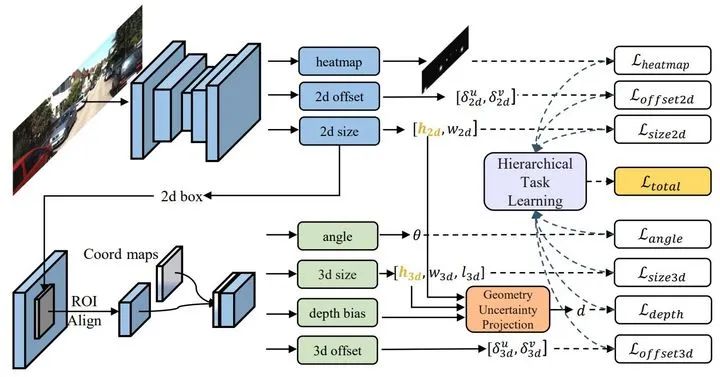
图4. GUPNet网络结构
输入图像首先经过backbone net提取出2d的bounding box,然后该bounding box经过ROI Align后提取出ROI特征,该特征会与3D坐标系进行concatenate从而获得最终的ROI特征,所有的3D信息推断均会在此ROI特征上进行。我们首先估计出3D box除了depth以外的所有参数。然后2D与3D bounding box的高度将被输入到GUP模块中提取出最终的depth,训练阶段HTL将会对每个部分进行控制从而实现multi-task learning。
Backbone Network
我们的backbone网络结构为常规单目3D检测的网络结构,前端的2D检测器是基于CenterNet,其输入一个2D heatmap以及2D box的长宽和位置修正量。之后对每个2D的ROI,使用ROI Align获得特征,再与坐标图结合即获得了全部的2D Roi。之后偏航角,3D box尺寸以及3D投影中心点的offset会被3D头计算。
GUP Module
为了实现对depth进行更好的uncertainty的估计,我们认为把投影过程体现在uncertainty的计算过程中尤为重要。为什么端到端的uncertainty评估不好呢,其本质就是因为投影过程对于uncertainty regression部分而言是agnostic的,其没有直接参与到投影过程的计算中,因此使得不确定度的估计质量不高(此处如果没有说明清楚的话,还请各位老师同学在评论区指出)。因此在本文中,我们采用基于概率模型的方法对不确定度的估计同样引入投影先验,我们首先假设投影过程中的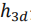 是拉普拉斯分布
是拉普拉斯分布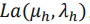 ,也即:
,也即:
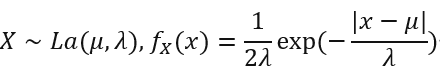
将此式代入投影模型,可计算获得输出depth为:
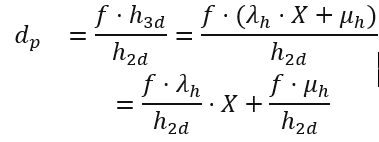
其中是一个归一化拉普拉斯分布La(0,1)。从上式可以得到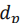 的均值
的均值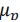 和标准差
和标准差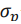 分别是
分别是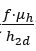 和
和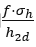 ,其中
,其中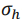 是拉普拉斯分布
是拉普拉斯分布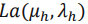 的标准差,它与
的标准差,它与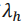 的关系为:
的关系为:。对于结果
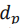 而言,其均值
而言,其均值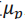 对应投影depth结果,而标准差
对应投影depth结果,而标准差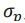 则反应了投影不确定度。在此基础上,为了更精准的depth输出,我们额外让神经网络预测出一个depth的修正值(depth bias),我们假设该修正值也是拉普拉斯分布
则反应了投影不确定度。在此基础上,为了更精准的depth输出,我们额外让神经网络预测出一个depth的修正值(depth bias),我们假设该修正值也是拉普拉斯分布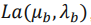 ,因此最终depth则变成:
,因此最终depth则变成:
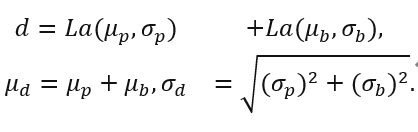
那么这时输出端的不确定度就同时反应了投影模型放大的输入端的不确定性以及网络bias引入的不确定度。为了获得最终得分,我们对该不确定度做了一个指数变换,把它映射到0~1之间:
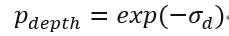
该得分的计算过程相较于图2的版本,其计算过程引入了投影模型的先验,因此由投影模型引起的误差放大效应可以被一定程度上解决,因为由估计误差引起的放大误差会被很好的反应在计算的不确定度中,所以基于此不确定度得到的得分质量将大幅上升。
上述结论在我们的ablation中得以体现,此处整理如下:
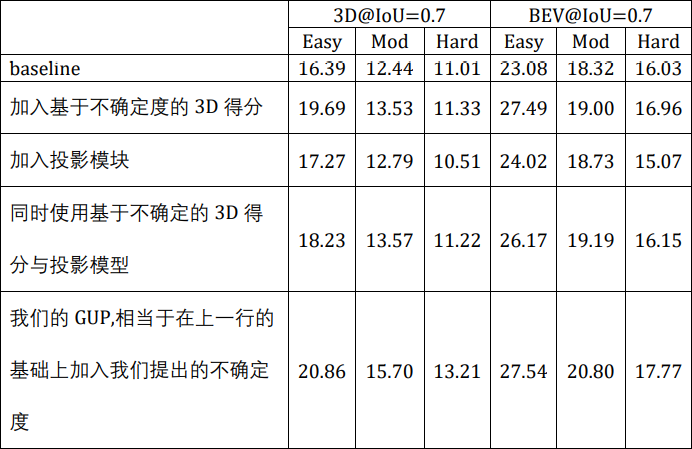
上表对应原始论文表3的(b)~(f)行。第一行是我们的baseline,第二行证明了单独用不确定度作为得分很有效(也安利给各位做单目3D检测的小伙伴尝试,真的很能提点)。第三行为单独的投影模型,也可以涨点(涨点量不多推测是因为我们的baseline中存在坐标map,本身就有一定的几何先验)。所以既然单独的不确定度得分和投影模块可以涨点,我们很自然地认为combine他们可以涨点,结果在第四行,居然事与愿违。反而不如普通第二行的模型高。之所以会这样,就是因为第二行的模型对应本blog的图2,第四行对应本blog图4。一场图4受到了误差放大的影响,得分难学了很多。而第五行则是我们的GUP module(相当于在第四行的基础上加入我们的几何不确定度)的结果。其效果明显好转,至少超过了简单的combination,使得投影模型与不确定度得分可以很好地并存。
Hierarchical Task Learning
GUP Module可以较好地处理inference时得分质量的问题。但是在训练阶段,误差放大依然会带来一些问题,一个最典型的问题就是在训练初期,的估计质量非常低,因此本身就已经很大的的误差将会在输出端引起巨量的误差,使训练直接走偏到其他方向。因此我们提出了一个多级task学习(HTL)策略来进行multi-task learning(MTL)。
以往的MTL算法大多都是假设task之间是独立的[2],或者至少认为task之间应当享有平衡的资源[3]。然而这些在我们的模型中均不合理,我们试图将[2][3]的方法引入我们的模型,结果性能不升反降(可参考原文表4)。原因很简单,对于Task Uncertainty[2],它的task之间独立的假设在我们的方法上完全不成立,我们的方法画成一个graph的话,如下图:
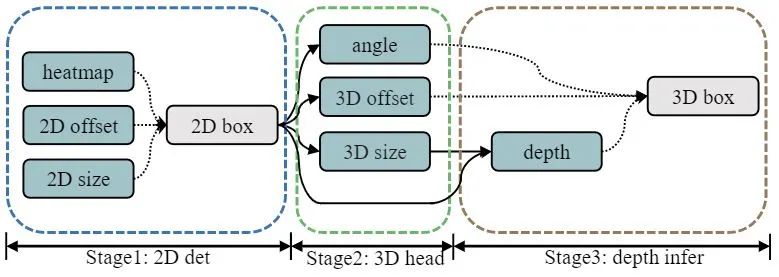
图5. Task Graph
可以看出来,task之间存在级联关系,级联的task本身就不可能独立,因此强行独立的假设会破坏Task Uncertainty的原本假设,因此带来性能退化。而对于GradNorm[3],其本质是希望平衡每个task对loss的贡献量,但是这在mono3Dder中同样难以成立,因为不同loss的尺度差异很大,诸如depth的单位是m,且范围很广,他的loss数值就会很大,而对于这种本身范围就很小的输出,他的损失函数数值也会很小。因此梯度之间的关系也会不同,强行平衡各个term的贡献会使得depth估计训练不充分,下降性能。
因此,我们针对GUPNet设计了HTL算法,其总体的思路为,一个task的训练要有它的先制任务(pre-task)的训练状态决定,如果先制任务训练完成,则当前任务展开训练。这种做法就类似于学校上课,一年级课程上完了再上二年级一样,所以总得来说,我们需要两个元素实现这件事情:
1). 任务学习状态评估:用于评估先制任务的学习状态,
2). 当前任务控制器:当先制任务学习达标后,提高当前任务的权重。
任务学习状态评估:对于第个任务的学习状态的评估,我们首先计算如下函数:
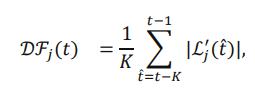
这个函数的本质就是对于一个loss曲线,在t时刻,取一个过去时刻长度为K的滑窗,然后平均每个时刻的变化率(导数),从而获得滑窗内的平均变化率。之后对于该时刻的学习状态评估即为:
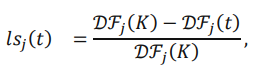
其含义为计算当前滑窗内的平均变化率与初始时刻滑窗平均变化率的关系,其可以图解为下图:
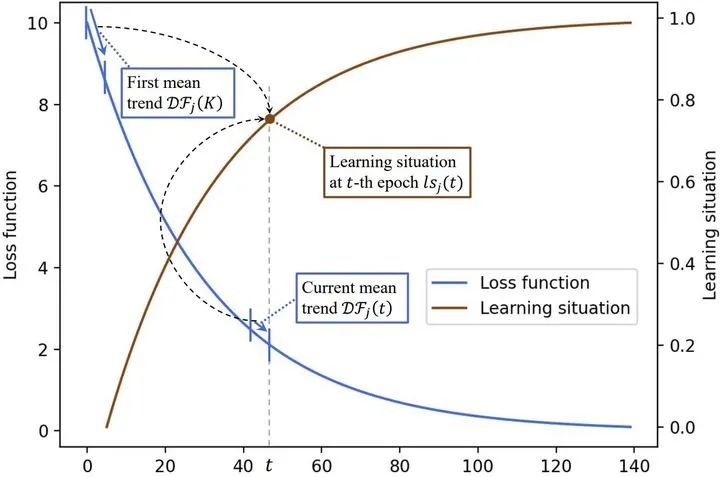
图6. HTL中的任务状态评估图解
本质上即为比较两个滑窗内变化率的关系,较一致时说明训练不充分,反之则说明训练较为充分。
当前任务控制器:
而对于第i个任务,我们使用如下的线性函数控制他的训练:
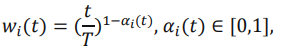
之所以使用该函数是因为形式简单且无需调整超参数,其中为总epoch数,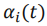 为该任务所有前置任务的学习状态评估值的乘积:
为该任务所有前置任务的学习状态评估值的乘积:
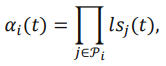
可以看出,前置任务学习充分的话,会加速最终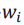 的提升速度,而线性函数也保证了的上升是平滑的而非跳边的。对于每个task,我们都可以获得这样一个权重,最终总损失函数如下:
的提升速度,而线性函数也保证了的上升是平滑的而非跳边的。对于每个task,我们都可以获得这样一个权重,最终总损失函数如下:
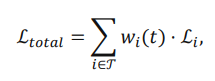
本文探究了基于几何的不确定度在单目3D检测中的应用,但是在实际实现中,我们只考虑了3D高度对结果的不确定度的影响,而没有考虑2D,这是因为一方面2D高度结果较之3D比较稳定,二来,引入基于分布的2D高度会使结果变得较为复杂,优化难度变高,在我们目前的实验中,难以取得较大幅度的性能提高,也欢迎大家关注我们未来的工作,我们未来会着重针对这个问题进行进一步的研究。
以上就是本工作的全部内容介绍,总得来说,GUP module尝试通过公式计算不确定度从而使得其转换出的3D得分可靠性上升。而HTL则通过一种手工策略,尝试更加针对性地解决GUPNet的串行multi-task learning的问题。以上即为本文的内容,欢迎大家讨论。
[1] Jiang B, Luo R, Mao J, et al. Acquisition of localization confidence for accurate object detection[C]//Proceedings of the European conference on computer vision (ECCV). 2018: 784-799.
[2] Kendall A, Gal Y, Cipolla R. Multi-task learning using uncertainty to weigh losses for scene geometry and semantics[C]//Proceedings of the IEEE conference on computer vision and pattern recognition. 2018: 7482-7491.
[3] Chen Z, Badrinarayanan V, Lee C Y, et al. Gradnorm: Gradient normalization for adaptive loss balancing in deep multitask networks[C]//International Conference on Machine Learning. PMLR, 2018: 794-803.
[4] Ma X, Wang Z, Li H, et al. Accurate monocular 3d object detection via color-embedded 3d reconstruction for autonomous driving[C]//Proceedings of the IEEE/CVF International Conference on Computer Vision. 2019: 6851-6860.
[5] Ma X, Zhang Y, Xu D, et al. Delving into Localization Errors for Monocular 3D Object Detection[C]//Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 2021: 4721-4730.
—版权声明—
仅用于学术分享,版权属于原作者。
若有侵权,请联系微信号:yiyang-sy 删除或修改!