
单目3D目标检测之入门
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达

来源:古月居
一、单目3D目标检测
1. 3D目标检测领域有哪些任务和方法?
为了更直观,我画了一个思维导图,点击链接后,注意需要切换一下思维导图状态。

在3D目标检测领域,根据输入信息的不同,大致可分为三类方法。
Point Cloud-based Methods (基于点云来做)
Multimodal Fusion-based Methods(点云和图像的融合)
Monocular/Stereo Image-based Methods(单目/立体图像的方法)
首先,基于点云的经典方法,比如VoxelNet(2018年)、PointPillars(2019年)、PointRCNN(2019年)等。
这类方法都是直接在点云数据上进行特征的提取和RPN操作,将2D目标检测中的网络结构和思想迁移到3D点云中。
点云和图像的融合方法是当前3D目标检测的主流。比较经典的算法有,2018年的MV3D、Frustum PointNets、2019年的Pseudo-LiDAR、2020年的PointPainting等算法。
这里的Pseudo-LiDAR(也叫为激光雷达)这篇文章对后来的单目3D目标检测领域的发展起到了促进的作用。
这里使用了双目图像来生成深度图,根据深度图得到点云数据,再进行目标检测任务。
Stereo Image-based方法中,主要是基于双目图像的3D目标检测,这一领域我不太了解,以后再做补充。
单目3D目标检测我是2021年刚接触的,比较出色的单目3D检测方法主要有:Mono3D PLiDAR、AutoShape、MonoRCNN、CaDDN等。
而在单目3D目标检测领域,又可细分为三类方法。关于单目3D目标检测的分类翻译自CaDNN这篇文章
直接法(Direct Methods)
所谓直接法就是直接从图像中估计出3D检测框,也无需预测中间的3D场景表示[9,52,4,32]。
更进一步的说就是,直接法可以结合2D图像平面和3D空间的几何关系来辅助检测[53,12,40,3]。
例如,可以在图像平面上估计出某对象的关键点,以帮助使用已知几何结构构建3D box[33,29]。[M3D-RPN][M3D-RPN: monocular 3D region proposal network for object detection. ICCV, 2019.][3]
引入深度感知卷积,它按行划分输入并学习每个区域的no-shared kernels,以学习3D空间中位于相关区域的特定特征。
可以对场景中的物体进行形状估计,从而理解三维物体的几何形状。
形状估计可以从3D CAD模型的标记顶点中被监督[5,24],或从LiDAR扫描[22],或直接从输入数据以自我监督的方式[2]。
直接法的缺点是检测框直接从2D图像中生成,没有产生明确的深度信息,相对于其它方法,定位性能较差。
基于深度的方法(Depth-Based Methods)
该方法先利用深度估计网络结构来估计出图像的像素级深度图,再将该深度图作为输入用于3D目标检测任务,[论文][Deep ordinal regression network for monocular depth estimation. CVPR, 2018.]。
将估计的深度图与原图像结合,再执行3D检测任务的论文有许多[38,64,36,13]。
深度图可以转换成3D点云,这种方法被称为伪激光雷达(Pseudo-LiDAR)[59],或者直接使用[61,65],或者结合图像信息[62,37]来生成3D目标检测结果。
基于深度的方法在训练阶段将深度估计从三维目标检测任务中分离,导致还需要学习用于三维检测任务的次佳的深度地图。
如何理解上边这句话呢?**对于属于感兴趣的目标的像素,应该优先考虑获取精确的深度信息,而对于背景像素则不那么重要,如果深度估计和目标检测是独立训练的,则无法捕捉到这一属性。
**所以将深度估计和目标检测任务融合成一个网络,效果会不会更好呢?
基于网格的方法(Grid-Based Methods)
基于网格的方法通过预测BEV网格表示(BEV grid representation)[48,55],来避免估计用做3D 检测框架输入的原始深度值。
具体来说,OFT[48]通过将体素投射到图像平面和采样图像特征来填充体素网格,并将其转换为BEV表示。
多个体素可以投影到同一图像特征上,导致特征沿着投影射线重复出现,降低了检测精度。
2. 什么是单目3D目标检测?

推荐参考博客:
单目3D目标检测论文笔记 3D Bounding Box Estimation - 知乎
ICCV 2021 | 悉尼大学&商汤提出GUPNet:单目3D目标检测新网络
3.发展情况
Kitti的3D目标检测排行中,Car类第一的为SFD,Moderate中达到了84.76%,但是Setting中没有激光点云的符号。排第7的BtcDet使用了该符号,所示直接处理点云的方法至少达到了82%多的AP。

点云和图像融合的方法,在Car类的Easy和Moderate类中的AP,其实跟直接处理点云方法的AP差别不是很明显。
双目或者说是立体视觉3D目标检测的方法的AP大概在53%左右。
单目3D目标检测的AP在16%多吧。

(更新时间,2021年11月12日)
如果要查找更加详细的论文和模型精度、建议直接看KITTI关于3D目标检测的榜单:The KITTI Vision Benchmark Suite (cvlibs.net)

这里还有一个纯单目3D目标检测的榜单(包含代码和论文):
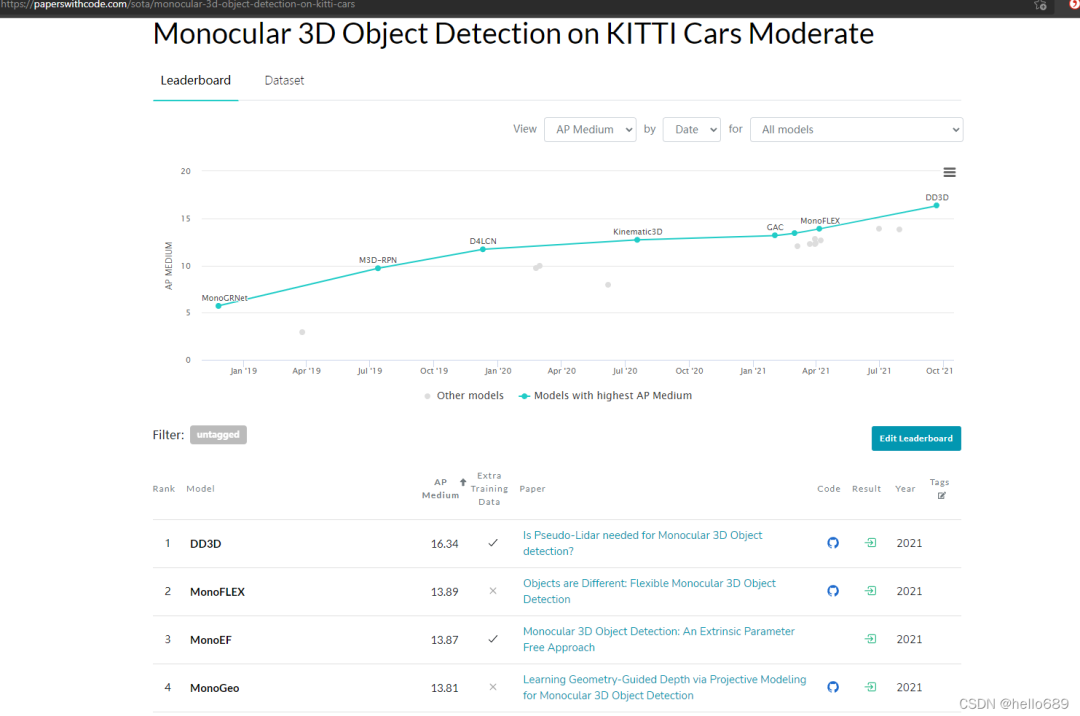
4. 为什么要做单目的3D目标检测?
为何最近单目3D目标检测也成为了一个小热点领域?起因可能是因为:
伪激光雷达技术的提出(pseudo-LiDAR),利用图像模拟出雷达点云图像;
单目深度估计的逐渐发展;
纯点云,图像2D,多传感器融合检测的研究逐渐成熟,或者说快要达到天花板了。
从传感这个角度来说,
主动获取深度信息:如激光雷达、RGB-D相机
价格昂贵,有效的距离小,并且线数再多的激光雷达获取的点云也是稀疏的,缺乏纹理信息的。况且激光雷达贵,一辆自动驾驶汽车装几个激光雷达、后期怎么维护保养,工业界最看重的是成本问题!!
再说说双目相机:
误差较大,要求时间同步,体积较大(基线安装有要求,如果坏了一个,那就等于报废)
再说说单目相机:
价格亲民
体积小,功耗低;
贴近实际应用需求。
并且,单目3D目标检测也不一定只能用于自动驾驶呀!只要设备上有摄像头,有3D检测的任务。
这里推荐大家一个单目深度估计的小应用场景:https://roxanneluo.github.io/Consistent-Video-Depth-Estimation/;单目3D检测最重要的一环就是单目深度估计,而单目深度估计在AR领域是广泛应用滴。
比如AR虚拟试衣间,或者京东淘宝上的一些AR试鞋,你拿手机摄像头对着自己脚,鞋自动覆盖到你脚上,这一块用到的应该是目标检测或者语义分割吧。
二、应用场景
推荐点击在线试鞋,体验一下AR技术吧。
单目3D目标检测的具体应用。我随后会单独整理在一篇博客中。
三、相关论文
3D目标检测综述:
Deep Learning for 3D Point Clouds: A Survey----2020年
3D Object Detection for Autonomous Driving: A Survey—2021年
更多的文献可查看知乎上的这篇文章:单目3D视觉目标检测论文总结 - 知乎 (zhihu.com),总结了100多篇单目3D目标检测领域的文章。
本专栏下,我将会持续不断的更新我读的一些论文和代码运行工作。
CaDDN:论文阅读 代码调试
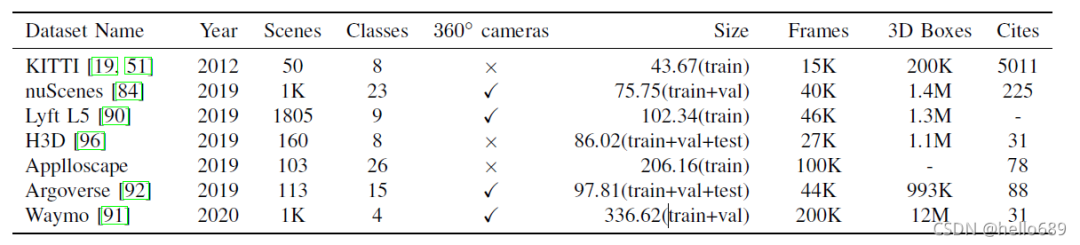
四、相关数据集
这里只列出比较常用的几个数据集的名字。数据集的详细说明在这篇博客中。
KITTI Dataset
Waymo Open
NuScenes Dataset
Cityscapes
Lyft L5
H3D
Applloscape
Argoverse
五、自动驾驶领域的相关企业
百度华为地平线,小鹏蔚来特斯拉。还挺押韵滴!
国外:Waymo、Cruise、Nuro、Argo;
国内:百度、华为、AutoX、图森未来、Pony(小马智行)、Weride(文远知行)、Didi(滴滴)、Momenta、纵目科技、智加科技、小鹏、蔚来、理想、嬴彻科技、魔视智能。
每个公司详细介绍:
国内:百度、华为、AutoX、图森未来、Pony(小马智行)、Weride(文远知行)、Didi(滴滴)、Momenta、纵目科技、智加科技、小鹏、蔚来、理想、嬴彻科技、魔视智能。
每个公司详细介绍,我将单独整理在一篇博客中,包括公司的背景、薪资情况、主要发展方向。
版权声明:本文为CSDN博主「hello689」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:
https://blog.csdn.net/jiachang98/article/details/121432839
下载1:OpenCV-Contrib扩展模块中文版教程
在「小白学视觉」公众号后台回复:扩展模块中文教程,即可下载全网第一份OpenCV扩展模块教程中文版,涵盖扩展模块安装、SFM算法、立体视觉、目标跟踪、生物视觉、超分辨率处理等二十多章内容。
下载2:Python视觉实战项目52讲
在「小白学视觉」公众号后台回复:Python视觉实战项目,即可下载包括图像分割、口罩检测、车道线检测、车辆计数、添加眼线、车牌识别、字符识别、情绪检测、文本内容提取、面部识别等31个视觉实战项目,助力快速学校计算机视觉。
下载3:OpenCV实战项目20讲
在「小白学视觉」公众号后台回复:OpenCV实战项目20讲,即可下载含有20个基于OpenCV实现20个实战项目,实现OpenCV学习进阶。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~