参考论文:D4LCN:Learning Depth-Guided Convolutions for Monocular 3D Object Detection(CVPR2020)论文、代码地址:在公众号「3D视觉工坊」,后台回复「D4LCN」,即可直接下载。
参考paddle复现:3D目标检测(单目)D4LCN论文复现(https://aistudio.baidu.com/aistudio/projectoverview/public)Abstract
单目3D目标检测最大的挑战在于无法得到精确的深度信息,传统的二维卷积算法不适合这项任务,因为它不能捕获局部目标及其尺度信息,而这对三维目标检测至关重要.为了更好地表示三维结构,现有技术通常将二维图像估计的深度图转换为伪激光雷达表示,然后应用现有3D点云的物体检测算法.因此他们的结果在很大程度上取决于估计深度图的精度,从而导致性能不佳.在本文中,作者通过提出一种新的称为深度引导的局部卷积网络(LCN),更改了二维全卷积 (D4LCN),其中的filter及其感受野可以从基于图像的深度图中自动学习,使不同图像的不同像素具有不同的filter.克服了传统二维卷积的局限性,缩小了图像表示与三维点云表示的差距.D4LCN对于最先进的KITTI的相对改进是9.1%,单目3D检测的SOTA方法.Introduction
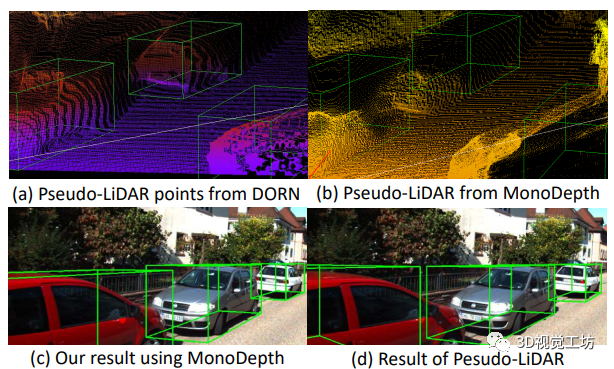
3D目标检测有许多应用,如自动驾驶和机器人技术.LiDAR设备可以获得三维点云,从而获得精确的深度信息.但是,LiDAR高成本和稀疏输出的特点让人们希望寻找到更便宜的替代品,这些替代品的其中之一维单目相机.虽然单目相机引起了人们的广泛关注,但在很大程度上不能够解决3D目标检测问题.实现上述目标的方法通常是分为基于2图像的方法和基于伪激光雷达点的方法两种.基于图像的方法通常利用几何体约束,包括对象形状、地平面和关键点.这些约束条件在损失函数中用不同的项表示,以提高检测结果.基于伪激光雷达的图像深度变换方法是通过模拟激光雷达信号的点云表示.如图1所示,这两种方法各有缺点,都导致了性能不理想.图1.(a)和(b)分别显示了监督深度估计器DORN和无监督单深度生成的伪激光雷达点.绿色框表示groundtruth(GT)3D框.如(b)所示,由于深度不准确而产生的伪激光雷达点与GTbox有较大的偏移量(c)和(d)显示了我们的方法和伪激光雷达使用粗深度图的探测结果.效果在很大程度上取决于估计深度图的精度,而我们的方法在缺少精确深度图的情况下可以获得准确的检测结果- 基于图像的方法通常无法获取有意义的局部对象尺度和结构信息,这主要是由于以下两个因素,远近距离的单眼视觉会引起物体尺度的显著变化.传统的二维卷积核很难同时处理不同尺度的对象(见图2).二维卷积的局部邻域定义在摄像机平面上,其中深度维数丢失.在这个非度量空间(e像素之间的距离没有一个明确的物理意义),过滤器无法区分对象和背景.在这种情况下,汽车区域和背景区域将被同等对待.
- 虽然基于伪激光雷达点的方法已经取得了一些进展,但它们仍然存在两个关键问题,这些方法的性能在很大程度上依赖于估计深度图的精度(见图1).从单目图像中提取的深度图通常是粗糙的(使用它们估计的点云具有错误的坐标),导致不准确的三维预测.换句话说,深度图的精度限制了三维目标检测的性能.伪激光雷达方法不能有效地利用从RGB图像中提取的高层语义信息,导致大量的虚警,这是因为点云提供了空间信息,却丢失了语义信息.
- 为了解决上述问题,我们提出了一种新的卷积网络D4LCN,其中卷积核由深度映射生成,并局部应用于单个图像样本的每个像素和通道,而不是学习全局内核来应用于所有图像.如图2所示,D4LCN以深度图为指导,从RGB图像中学习局部动态深度扩展核,以填补二维和三维表示之间的空白,其中每个核都有自己的扩张率.
图2.不同卷积方法的比较(a)是传统的二维卷积,它在每个像素上使用一个卷积核来卷积整个图像(b)对图像的不同区域(切片)应用多个固定卷积核.(c)使用深度图为每个像素生成具有相同接收场的动态核(d)表示我们的方法,其中滤波器是动态的,深度图为每个像素和通道特性图具有自适应接收场.它可以用比(C)更少的参数更有效地实现.我们的贡献(1)提出了一种新的三维目标检测组件D4LCN,其中深度图指导了单目图像的动态深度扩展局部卷积的学习(2)设计了一个基于D4LCN的单级三维物体检测框架,以更好的学习三维特征,以缩小二维卷积和基于三维点云的运算之间的差距(3)大量实验表明,D4LCN优于最先进的单眼3D检测方法,并在KITTIbenchmark上取得第一名.网络结构
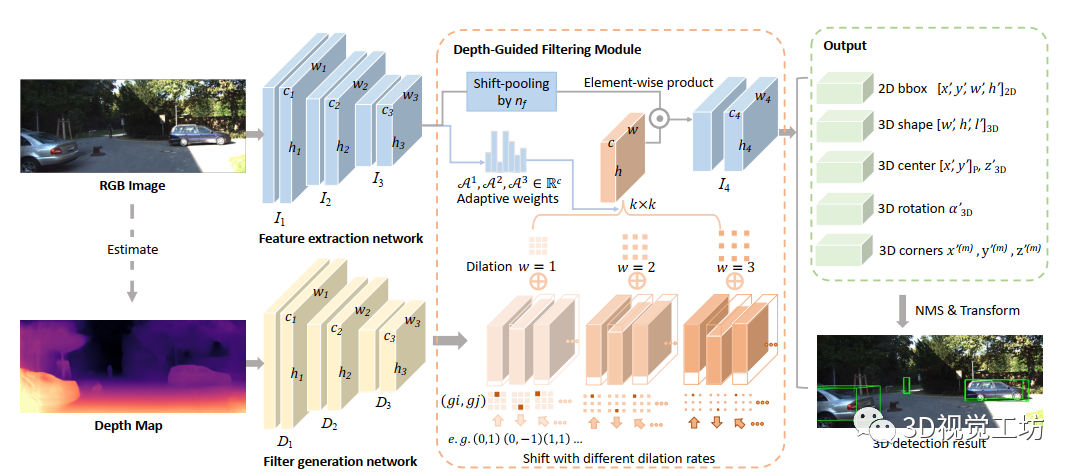
我们的框架由三个关键组件组成:网络主干、深度引导滤波模块和2D-3D head图3.单目三维物体检测框架.首先从RGB图像中估计出深度图,并与RGB图像一起作为输出两个分支网络的输入.然后利用深度引导滤波模块对每个残差块的信息进行融合.最后,采用一级非最大抑制探测头(NMS)进行预测损失函数

比较结果
我们在kitti数据集的官方测试集和两组验证集上进行了实验.表一包括排名前14位的方法,其中我们的方法排名第一.可以观察到:(1)我们的方法比第二个最好的竞争对手三维汽车检测的提高9.1%(2)大多数竞争对手在COCO/KITTI上预先训练的检测器(例如更快的rcnn)或采用多阶段训练来获得更好的2D检测和稳定的3D结果.而我们的模型是使用标准的ImageNet预训练模型进行端到端训练的.然而,我们仍然取得了最优异的三维检测结果,验证了我们的D4LCN学习三维结构的有效性.因为人是非刚体.其形状多变,深度信息难以准确估计.因此,对行人和骑自行车的人进行三维检测变得尤为困难,所有基于伪激光雷达的方法都无法检测到这两种类型的传感器,如表2所示.该方法在行人和骑车人的三维检测中仍取得了令人满意的效果.此外,我们还在图4中显示了与我们的D4LCN的不同滤波器相对应的活动映射.我们模型的同一层上的不同滤波器使用不同大小的感受野来处理不同规模的物体,包括行人(小)和汽车(大),以及远处的汽车(小)和附近的汽车(大).表2.D4LCN在三个数据分割上的多类3D检测结果.图4.D4LCN的不同滤波器对应的活动,分别表示1,2,3的扩张率.不同的滤波器在模型中有不同的函数来自适应地处理尺度问题.总结
本文提出了一种用于单眼三维目标检测D4LCN,其卷积核和感受野(扩张率)对于不同图像的不同像素和通道是不同的.这些核是在深度映射的基础上动态生成的,以弥补二维卷积的局限性,缩小二维卷积与基于点云的三维算子之间的差距.结果表明,该算法不仅能解决二维卷积的尺度敏感和无意义的局部结构问题,而且能充分利用RGB图像的高级语义信息.而且D4LCN能更好地捕获KITTI数据集上的三维信息,并能在KITTI数据集上进行单目三维目标检测.初衷
3D视觉工坊是基于优质原创文章的自媒体平台,创始人和合伙人致力于发布3D视觉领域最干货的文章,然而少数人的力量毕竟有限,知识盲区和领域漏洞依然存在。为了能够更好地展示领域知识,现向全体粉丝以及阅读者征稿,如果您的文章是3D视觉、CV&深度学习、SLAM、三维重建、点云后处理、自动驾驶、三维测量、VR/AR、3D人脸识别、医疗影像、缺陷检测、行人重识别、目标跟踪、视觉产品落地、硬件选型、求职分享等方向,欢迎砸稿过来~文章内容可以为paper reading、资源总结、项目实战总结等形式,公众号将会对每一个投稿者提供相应的稿费,我们支持知识有价!投稿方式
邮箱:vision3d@yeah.net 或者加下方的小助理微信,另请注明原创投稿。