
SSHFD:IBM提出的单阶段人体跌倒检测网络
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


这篇文章是由IBM研究院发表的有关于老人跌倒识别的文章。整体网络比较复杂,代码也没有开源,就不精读了,水一水了解个大概就行了吧。
论文地址:http://xxx.itp.ac.cn/pdf/2004.00797v2
跌倒可能会对老年人造成致命的后果,尤其是当跌倒的人由于意识丧失或受到其他伤害而无法寻求帮助时。自动跌倒检测系统可通过迅速的跌倒警报来提供帮助,并最大程度地减少家中老人独自在家中摔倒时的恐惧感。由于场景变化,不同的摄像机视角不同,遮挡和背景杂乱之类的挑战,现有的基于视觉的跌倒检测系统缺乏对未知环境的通用性。在本文中,探索了克服上述挑战的方法,并提出了一种Single Shot 人体跌倒检测器(SSHFD),这是一种基于深度学习的框架,可从单个图像中进行自动跌倒检测。这是主要是通过两项关键创新来实现的:首先,提出了基于人类姿势的跌倒表示法,该跌倒表示法不影响外观特征;其次,提出了用于3d姿势估计和跌倒识别的神经网络模型,这些模型可以克服被身体部位遮挡的人体关节,从而完成更准确的估计与识别。在公开的跌倒数据集上进行的实验表明,本文的框架成功地将从合成数据中学到的3d姿态估计和跌倒识别知识迁移到了真实世界数据中,展示了其在真实场景中准确检测跌倒的综合能力。
对于独居在家的老人来说,跌倒是最关键的危险之一,可能会造成严重的伤害,并且因为害怕再次跌倒而限制了正常的活动。自动跌倒检测系统可以在危险的情况下及时发出警报,还可以自动收集和报告跌倒事件,用于分析跌倒的原因,从而提高行动不便和受人监护的人的生活质量。
基于视觉的系统为跌倒检测提供了低成本的解决方案。它们不会对人体健康造成感官上的副作用,也不会像使用可穿戴设备的系统那样影响老年人的日常活动。在典型的跌倒检测方法中,从视觉数据中检测出人的行为,并学习特征来区分跌倒和其他活动。现有的方法大多利用从视频数据中提取的基于物理外观的特征来表示跌倒。然而,基于外观的特征在实际环境中的泛化性较差,因为外观特征的变化较大,不同的摄像机视角不同并且背景杂乱。此外,由于大规模公共跌倒数据集的不可用性,大多数现有的跌倒检测器都是使用模拟环境或使用受限数据集(由于隐私问题不能公开共享)进行训练和评估的。因此,这些方法并没有表现出在未见过的真实世界环境中进行跌倒检测的泛化能力。
在本文中,探索了克服上述挑战的方法,并提出了一个深度学习框架,称为 "Single Shot Human Fall Detector(SSHFD)",用于在未知的真实世界环境中进行精确的跌倒检测。本文的主要贡献如下。
1、提出一种基于人体姿态的跌倒表示法,该表示法与场景中人物的外观特征、背景、光照条件和空间位置无关。实验表明,在基于2D姿态和3D姿态的跌倒表示上训练的神经网络模型能够成功地推广到了未知的现实环境中进行跌倒识别。
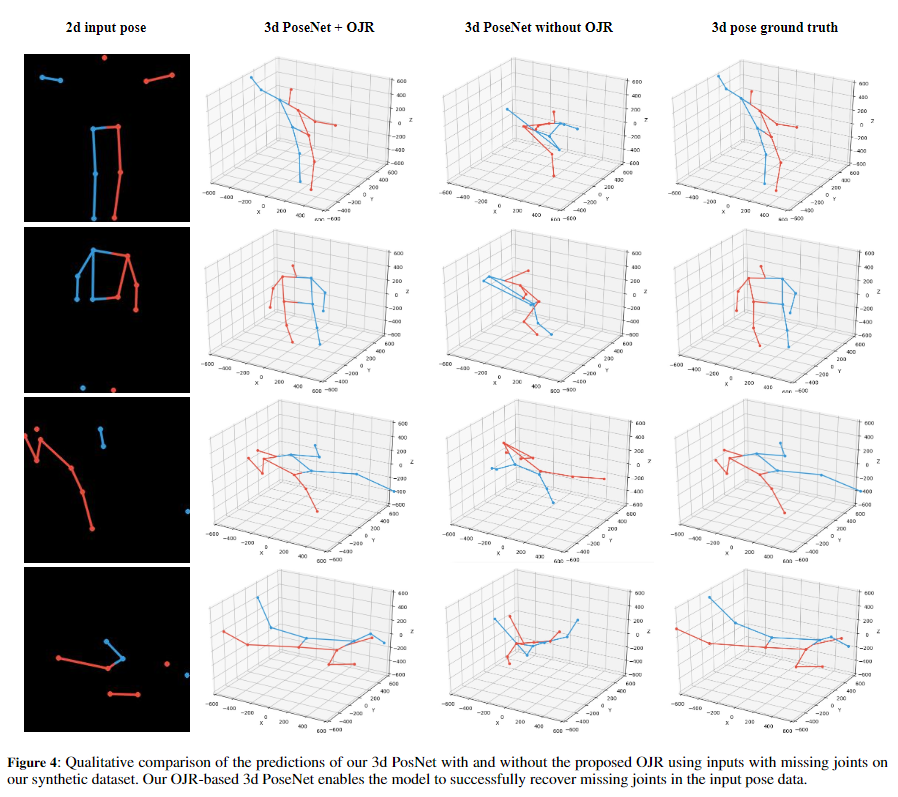
2、提出了3D姿态估计和跌倒识别的神经网络模型,该模型对部分遮挡具有鲁棒性。实验表明,本文的模型成功地从被遮挡的身体部位恢复了关节信息,并从不完整的输入数据中准确识别了跌倒姿态。
3、在公开的跌倒数据集上评估了本文的算法模型,其中证明了仅使用合成数据进行训练时,本文的框架显示了对未知的真实世界数据的跌倒识别的出色泛化能力。
与现有的方法相比,本文的工作不同之处在于:首先,本文的框架学习的是基于姿态的跌倒特征,对外观特征是不变的。这使得框架能够成功地将从纯合成数据中学习到的跌倒识别知识转移到具有未知背景和不同人类角色的真实世界数据中。本文的框架结合了2D和3D姿态知识,使得框架能够成功地处理2D姿态的模糊性(在不同的摄像机视角下),而不需要多个摄像机设置或深度传感器技术。最后,3D姿态估计和跌倒识别的神经网络模型对姿态数据中的缺失信息具有弹性。这使得框架能够准确地从人的姿势中分辨出跌倒和不跌倒的情况。
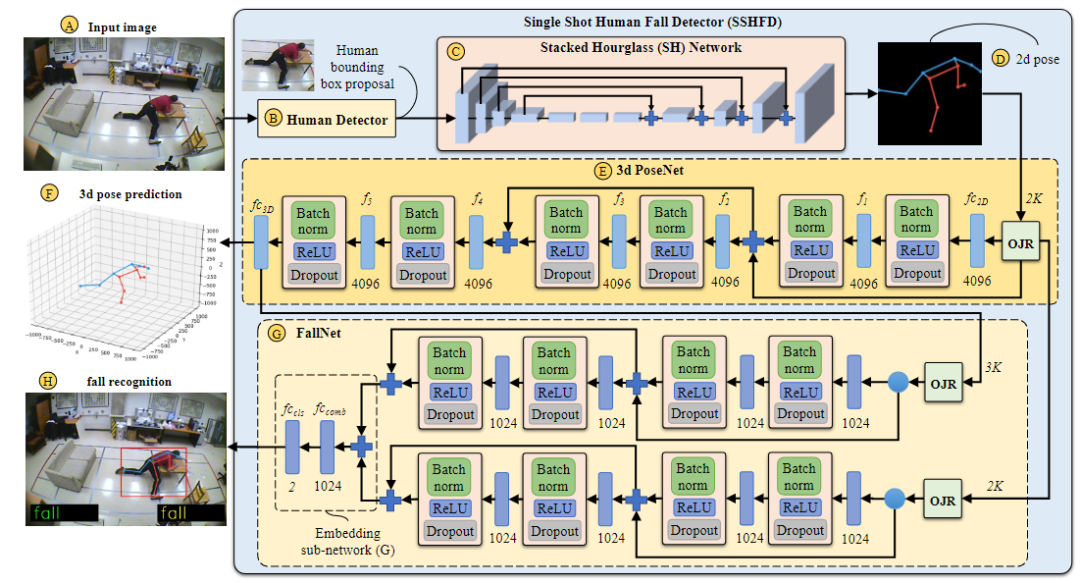
图1:Single Shot Human Fall Detector(SSHFD)概述。给定场景的单个RGB图像(A),SSHFD生成 human proposals(B),将其输入到堆叠的 Hourglass网络(C)中以进行2D姿态预测。接下来,将预测的2D姿态(D)送入神经网络(E)进行3D姿态预测(F)。最后,将2D姿态和3D姿态信息输入到神经网络(G)中以进行跌倒识别(H)。我们的模型集成了“Occluded Joints Resilience ”(OJR)模块,这些模块使模型对于姿势数据中丢失的信息具有鲁棒性。
1、The Proposed Fall Representation
本文的跌倒表示是基于二维图像空间和三维笛卡尔空间的关节位置。通过将关节估计值(在场景图像中预测)转换为224×224尺寸的固定参考图像来归一化二维姿势,如图1-D所示。然后将归一化后的2D姿态用于预测笛卡尔空间中的关节位置,如图1-F所示。三维预测相对于髋关节进行归一化处理。
2、The Proposed 2d Pose Estimation (Fig. 1)
2D姿态估算器由两个主要模块组成:i)human detector,它从输入图像生成人体候选边界框(human bounding box proposals);ii)堆叠的沙漏(SH,Stacked Hourglas)网络,它预测2D人体关节的位置,以及他们相应的置信度分数。
3、The Proposed 3D Pose Estimation (Fig. 1-E)

损失函数为:
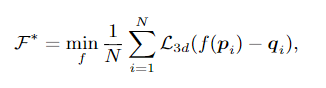
其中L3d代表MSE损失。图1-E显示了基于《A simple yet effective baseline for 3d human pose estimation》架构的3d姿态估计模型“ 3d PoseNet”的结构。它以将2维姿态转换为1024维特征的线性全连接层开始。接下来,有五个线性层f1-f5,每个层具有4096维,然后是批处理归一化BN层,一个ReLU激活函数单元和一个drop-out模块。最后一个层3D线性全连接层产生3K维输出。网络中定义了两个残差连接,这些残差连接将较低层的信息组合到较高层,并提高了模型的泛化性能。
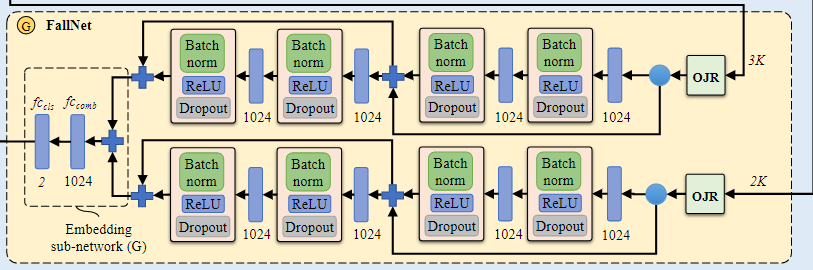
4、 The Proposed Fall Recognition (Fig. 1-G)
交叉熵损失函数:
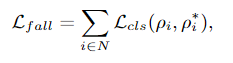
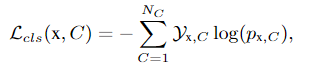
The Proposed Occluded Joints Resilience(OJR)
训练在RGB图像上的姿势估计器不可避免地会因图像不完美、遮挡、背景杂乱和不正确的标签值等因素而导致关节预测错误,由于网络模型中三维姿态网络和FallNet模型依赖于SH网络的输出,二维姿势预测的错误会影响三维姿势估计和跌倒识别的质量。为了克服这一挑战,提出了一种名为 "Occluded Joints Resilience(OJR) "的方法,该方法增加了模型对姿势数据不完整信息的鲁棒性。为了实现这一目标,OJR方法创建了一个遮挡图像Mi,并使用它将原始姿态数据转化为遮挡姿态数据。
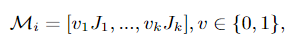
其中Ji =(xi,yi)表示身体关节的二进制变量,也就是第k个关节的可见性。在训练过程中,OJR方法会生成丰富的独特的遮挡图像库,这些图像会因训练样本而异,从而提高了网络对各种被遮挡情况的适应性。
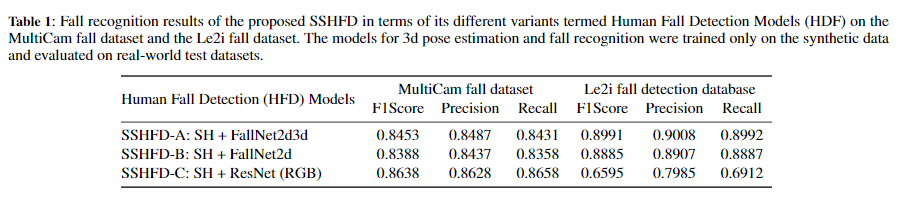

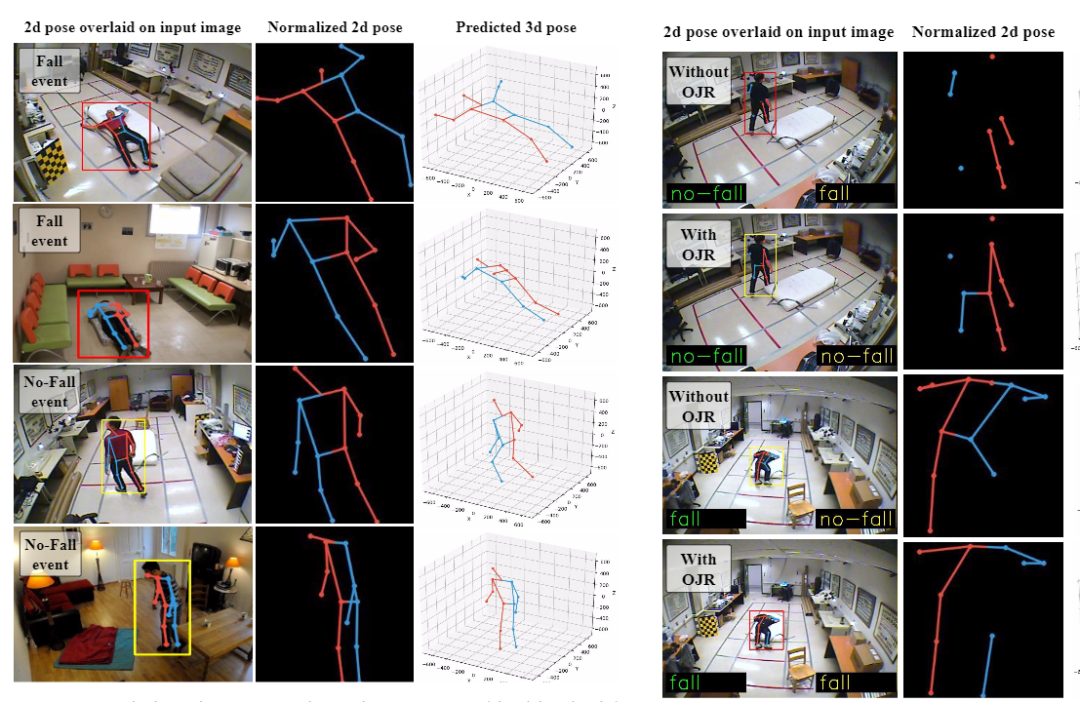
更多细节可参考论文原文。
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~