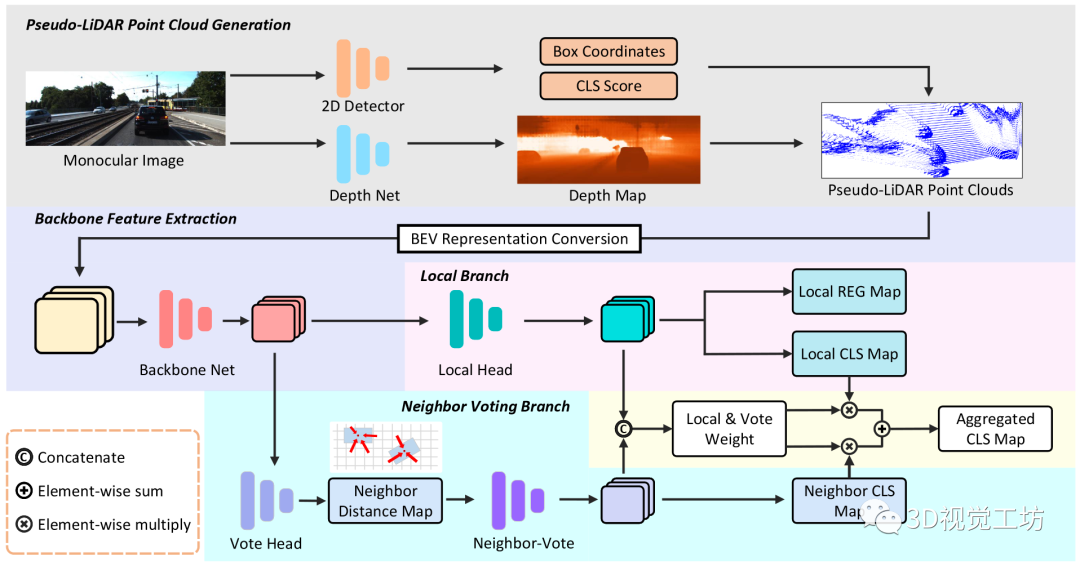
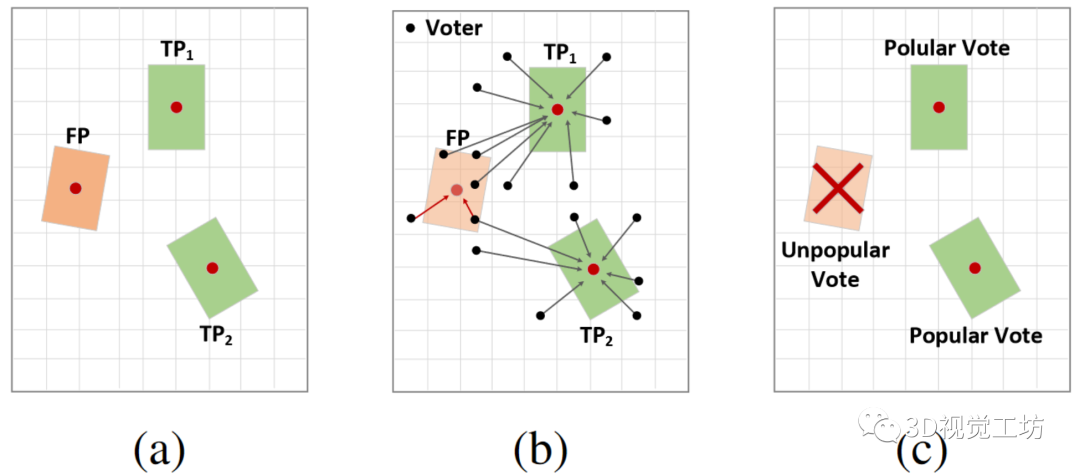
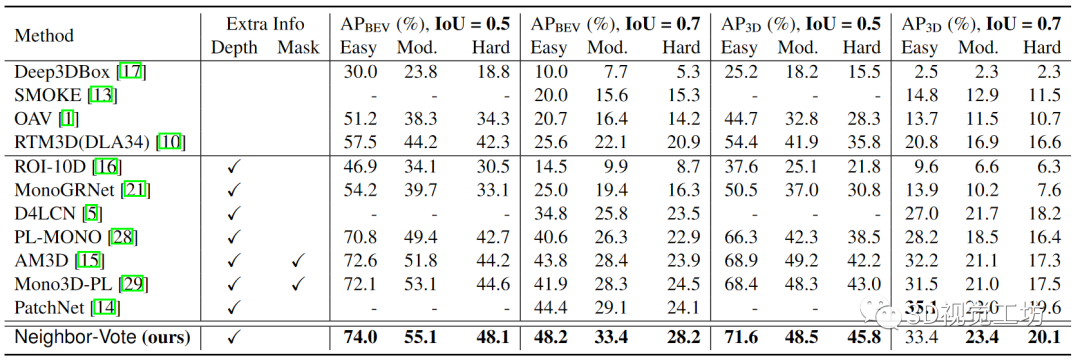
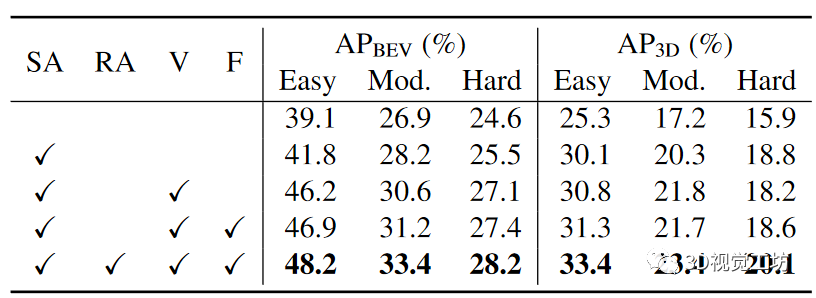
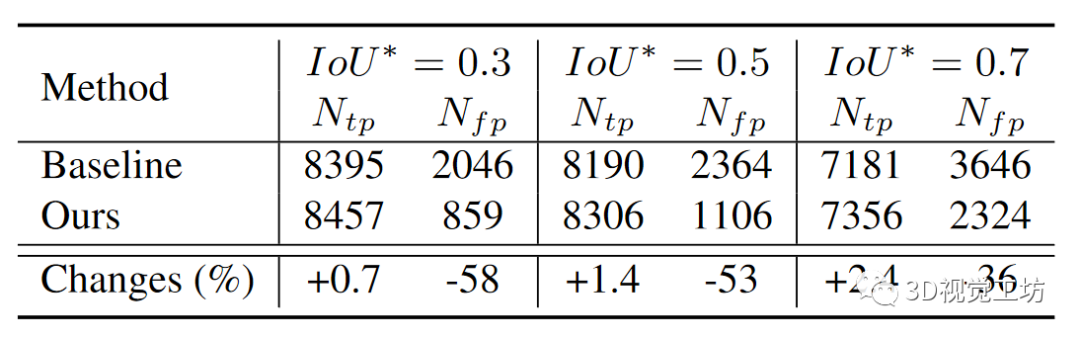
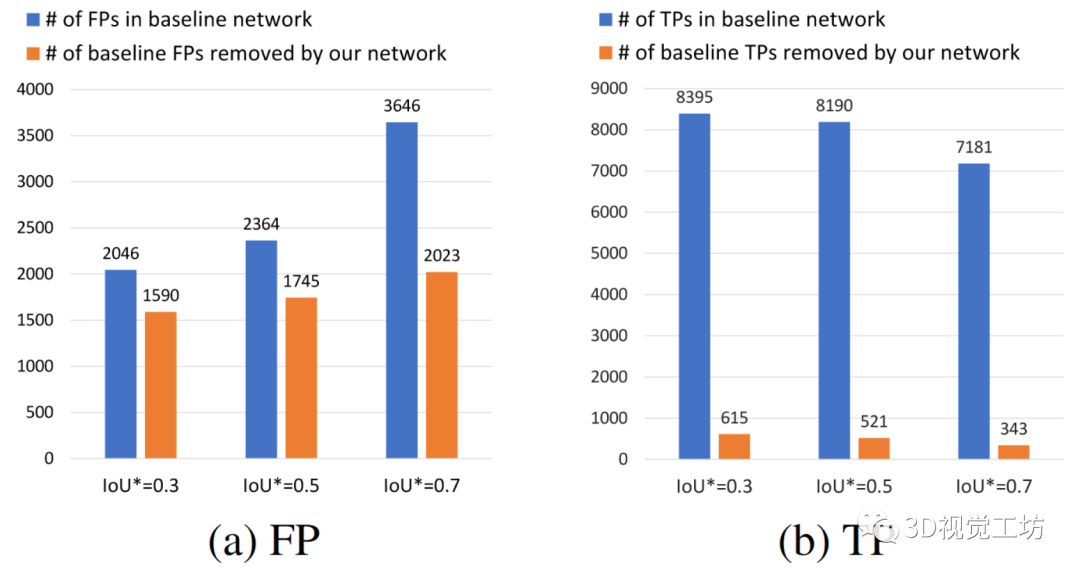
名字:Neighbor-Vote: Improving Monocular 3D Object Detection through Neighbor Distance Voting链接:https://arxiv.org/pdf/2107.02493.pdf摘要:随着摄像头在自动驾驶等新的应用领域的应用越来越广泛,对单目图像进行3D目标检测成为视觉场景理解的重要任务。单目3D目标检测的最新进展很多依赖于伪点云生成,即进行单目深度估计,将二维像素点提升为伪三维点。然而,单目图像的深度估计精度不高,必然会导致伪点云在目标内的位置发生偏移。因此,预测的边框可能存在不准确的位置和形状变形。在本文中,本文提出了一种新颖的邻居投票方法,该邻居预测有助于从严重变形的伪点云的改善目标检测。具体而言,每个特征点形成他们自己的预测,然后通过投票来构建“共识”。通过这种方式,本文可以有效地将邻居的预测与局部预测的预测相结合,实现更准确的3D检测。为了进一步放大ROI伪点和背景点之间的区别,本文还将2D前景像素点的ROI预测分数编码到相应的伪3D点上。本文在KITTI基准测试上验证本文提出的方法,在验证集上的鸟瞰检测结果优于目前的SOTA,特别是对于“困难”水平检测。1.引言3D目标检测是依赖于理解3D世界中的上下文的应用(例如自主驾驶)中最重要的任务之一。目前已出现很多基于点云的3D目标检测算法。尽管这些方法取得了优异的性能,然而,激光雷达仍然太昂贵,不能装备在每一辆车上。因此,廉价的替代品更受青睐,特别是相机,因为它们的价格低,帧率高。另一方面,由于深度信息的缺少,在RGB图像,尤其是单眼图像上进行3D检测,仍然是艰巨的挑战。为了解决这一挑战,目前已经存在方法:首先从单目图像估计深度信息,然后将2D像素转换到伪3D。随后3D目标检测器可以应用于伪点云上。与真实雷达点云相比,如上所述的伪点云存在一些问题。首先,由于单目深度估计必然存在不准确性,导致伪点云存在位置偏移和形状变形,这可能会破坏3D边框回归。其次,远距离目标深度估计的精度低于近距离目标深度估计的精度,导致远目标深度估计的失真明显增大。这些变形的伪点云将导致大量误检框的产生。本文提出了一种叫做Neighbor-Vote(邻居投票)的方法。具体而言,本文认为特征图上的目标周围的每个点都是“选民”。选民需要从自己的视角出发投票给一定数量的附近目标。通过这个投票过程,误检目标比真目标的得票率要低得多,因此更容易被识别。总之,本文做出了以下三点贡献: