
基于三维卷积神经网络的RGB-D显著目标检测
点击上方“小白学视觉”,选择加"星标"或“置顶”
重磅干货,第一时间送达


摘要RGB-D显著目标检测(SOD)近年来引起了越来越多的研究兴趣,并出现了许多基于编码器-解码器架构的深度学习方法。然而,现有的RGB-D SOD模型大多是在单编码器或解码器阶段进行特征融合,难以保证足够的跨模态融合能力。在本文中,作者首次尝试通过三维卷积神经网络对RGB-D SOD进行寻优。该模型名为RD3D,其目标是在编码器阶段进行预融合,在解码器阶段进行深度融合,以有效促进RGB流和深度流的充分融合。具体来说,RD3D首先通过一个膨胀的3D编码器对RGB和depth模态进行预融合,然后通过设计一个具有丰富的背投影路径(RBPP)的3D解码器,利用3D卷积的广泛聚合能力,进行深度特征融合。采用这种编码器和解码器的渐进融合策略,可以有效地利用两种模式之间的充分互动,提高检测精度。在6个广泛使用的基准数据集上进行的大量实验表明,在4个关键评价指标上,RD3D优于14种最先进的RGB-D SOD方法。
代码链接:https://github.com/PPOLYpubki/RD3D
作者的工作有三个主要贡献:
作者在编码器阶段提出了预融合的思想,并说明了它对最终性能的影响。作者建议通过3D cnn来解决这个问题,它可以有效地融合交叉模态特征,而不需要专门的或复杂的模块。
为了更好地利用3D卷积的广泛聚合能力,作者设计了一个包含丰富反投影路径(RBPP)的3D解码器。这样的3D解码器使得作者提出的RD3D成为一个完全3D的基于cnn的模型,也是第一个用于RGB-D SOD任务的3D基于cnn的模型。
作者表明,RD3D是第一个基于3D cnn的RGB-D SOD模型,在6个广泛使用的基准数据集上显著超过了14种最先进的(SOTA)方法。
提出的RD3D总体架构如下图所示。它遵循典型的编译码架构,由一个3D编码器和一个3D解码器组成。3D编码器基本上是一个由3D卷积扩展的类似ResNet/ vg的骨干。它的目标是跨模态特征的预融合,其输出是模态感知的多层次特征。另一方面,3D解码器通过3D卷积来解码特征。它遵循典型的UNet-like由上而下的时尚,但包含了丰富的投影路径(RBPP,蓝线箭头在下图)以及channelmodality关注模块(CMA,橙色模块在下图),最后解码后3 d曲线玲珑,译码器输出预测地图高亮突出对象(s)。注意到,由于三维卷积具有广泛的聚合能力,下图中没有使用任何显式的跨模态融合模块。
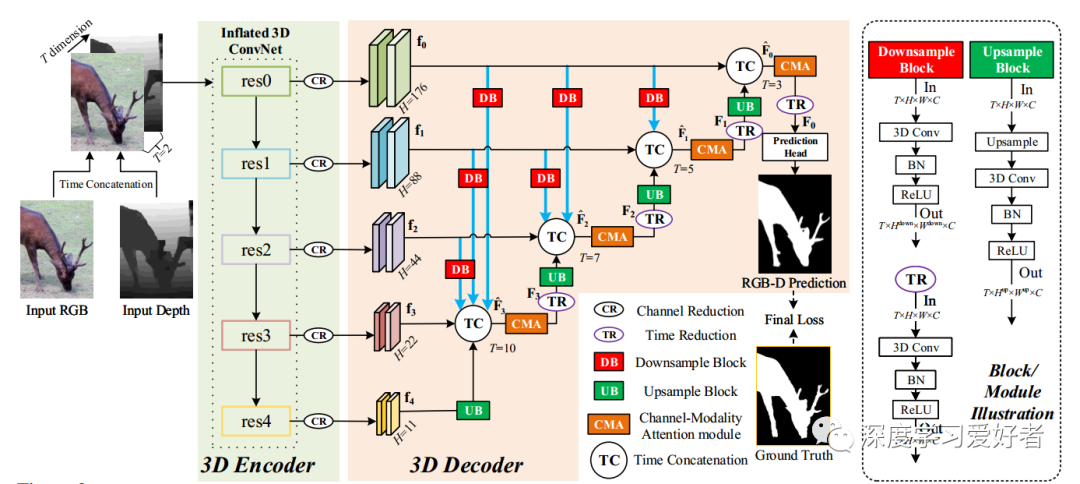
RGB-D SOD的RD3D方案框图。H为输出的各层次特征图的空间分辨率,T为时间维数。
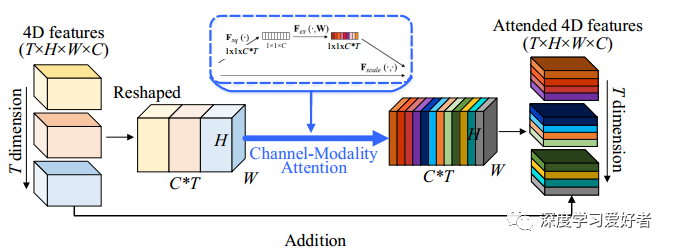
提出三D通道-模态注意模块,可同时参与通道和时间维度。

RD3D与最先进的SOTA方法的定性比较。GT表示地面真实值。

其他建筑和消融研究的视觉结果。一般来说,RD3D提供了最接近GT的结果。
作者提出了一种新的RGB-D SOD框架,称为RD3D,它基于3D cnn,以渐进的方式进行跨模态特征融合。RD3D首先利用3D卷积对RGB和depth进行预融合,然后通过增加丰富的背投影路径和通道模态注意模块的3D解码器对模态感知特征进行显式融合。在六个基准数据集上进行的大量实验表明,RD3D是第一个完全3D的基于cnn的RGB-D SOD模型,与现有的SOTA方法相比表现良好。详细的消融研究和讨论验证了RD3D的关键成分。在未来,作者希望RD3D能够鼓励更多基于3D cnn的RGB-D SOD设计。
论文链接:https://arxiv.org/pdf/2101.10241.pdf
每日坚持论文分享不易,如果喜欢我们的内容,希望可以推荐或者转发给周围的同学。
- END -
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~