
图像篡改被动检测技术一览:基于特征提取和卷积神经网络的篡改检测

极市导读
本文聚焦于归纳和总结数字图像篡改被动检测方法,对基于特征提取和基于卷积神经网络的两类篡改检测方法进行全面论述,分析其中不足与问题,并讨论了数字图像篡改被动检测技术未来的发展趋势。>>加入极市CV技术交流群,走在计算机视觉的最前沿
目录
0 前言 1 基于特征提取的传统篡改检测 1.1 复制黏贴篡改检测方法 1.2 拼接组合篡改检测方法 2 基于卷积神经网络的篡改检测 3 未来发展趋势 面向互联网共享环境下的数字图像篡改检测研究 面向大规模图像数据集的数字图像篡改检测研究
0前言
随着图像编辑技术的不断发展,人们可以轻松地篡改图像内容或者操纵图像生成过程,使得图像的真实性和完整性受到挑战,严重影响了人们对新闻报道、军事经济中图像真实度的信任。在已有的研究范围里,学者们将图像内容篡改类型总体分为两类:
(1)复制粘贴篡改(Copy-move)
(2)拼接组合篡改(Splicing)
复制粘贴篡改是指是在同一幅图像上,将部分区域复制粘贴到该图中的其它位置;拼接组合篡改是指将一幅图像中的某个区域拷贝到另一幅图像中以生成新的图像。
数字图像篡改检测按照是否预先在数字图像中嵌入附加信息可以分为主动检测和被动检测(也叫盲检测)两种[1],篡改主动检测技术主要包括数字签名技术和数字水印技术,这两种方法的共同点是:需要图像提供方进行摘要信息的提取或者水印的嵌入,即在实际检测时需要图像提供方进行配合,这一条件在实际操作中很难满足。因此无须对数字图像进行预前处理的数字图像篡改被动检测技术成为当前图像检测领域的研究热点。数字图像篡改被动检测技术大体上被分为两类:
(1)基于特征提取的传统篡改检测技术
(2)基于卷积神经网络的篡改检测技术
在早期的研究中,研究者大多将注意力集中在图像本身的统计信息和物理特性上,采用基于图像的特征提取方法来检测篡改区域,比如从镜头失真矫正、颜色插值、传感器噪声等图像生成过程中不同的处理信号入手,大量的篡改被动检测算法和数学模型被提出[2-5],在信息受限的场景中得到良好的应用,进一步地促进了数字图像取证领域的发展。但是传统的篡改检测技术只是针对图像的某一种属性进行设计,使得最终的检测率不是很高并且鲁棒性也较差,导致基于特征提取的篡改检测算法很难在实际当中高质量、高效率地解决图像的信息安全问题。
近年来,随着深度学习技术的不断发展,尤其以AlexNet为代表的卷积神经网络(Convolutional Neural Network,CNN)[6]在特征提取方面的优异表现,加之其在图像分类、语义分割、物体识别等计算机视觉任务上取得的可观成绩,一些研究学者尝试使用深度学习技术解决数字图像的篡改检测问题。基于卷积神经网络的篡改检测技术利用深度学习网络的多层结构和强大的特征学习能力实现不依赖于图像的单一属性的篡改检测,弥补了基于特征提取的传统图像篡改检测技术适用度不高的缺点。基于卷积神经网络的篡改检测技术不仅可以定位篡改区域,而且还能给出相应的篡改类型,在现有的用于数字图像取证的公开数据集的实验中,基于卷积神经网络的篡改检测算法效果优于传统图像的篡改检测算法,并表现出较好的鲁棒性。
现有数字图像篡改检测被动检测相关综述主要聚焦于传统检测方法,如Chu等[6]阐述了目前国内外学者在JPEG图像篡改的被动取证技术方面的主要研究成果,基于篡改和方法的不同,将目前检测方法分为双重JPEG压缩检测方法和JPEG块效应不一致性检测方法。Du等[7]总结了目前基于底层线索和基于学习的感知哈希图像篡改检测方法,并根据方法的不同特点进行更为细致的分类。整体缺乏对利用卷积神经网络来设计图像篡改检测方法的阐述。本文聚焦于归纳和总结数字图像篡改被动检测方法,分析其中的不足和面临的问题,对现有的代表性工作和方法尤其是基于卷积神经网络的方法的主要框架进行论述。讨论数字图像篡改被动检测技术未来的发展趋势并给出结论。
1 基于特征提取的传统篡改检测
传统的篡改被动检测技术基于图像统计信息和物理特征分别对复制黏贴和拼接组合的两种篡改手段提出相应的检测方法。研究学者根据篡改手段和图像属性的不同,将检测方法分成五个类别,即基于重叠块的检测方法、基于特征点的检测方法、基于图像属性的检测方法、基于设备属性的检测方法和基于压缩属性的检测方法。图像篡改检测类型及技术如图1所示:
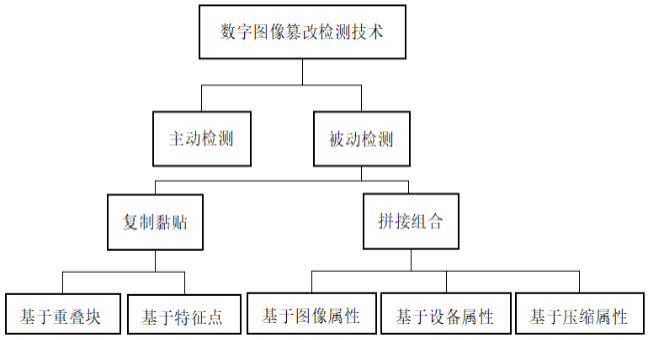
图1 图像篡改检测类型及技术
1.1复制黏贴篡改检测方法
复制粘贴篡改的一般原理是将同一幅图像中相似的物体,平移到图像的另一个区域中。由于此类篡改操作对图像的变动较小,因此不易被人发现。复制粘贴篡改定义如图2所示:
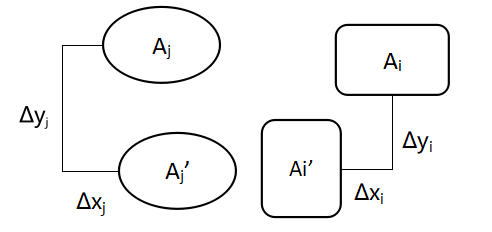
图2 复制粘贴示意图
令 表示原始图像, 表示复制粘贴篡改之后的图像。 和 表示原始区域, '和 '表示复制区域。
图像的原始区域和复制区域分别有位移差 和 则篡改图像可以表示为式 1 :
其中(x, y)表示像素点,f(x,y)表示图像在点(x, y)处的像素值,∆x、∆y是对应分量的坐标点差值,是系统参数。
1.1.1基于重叠快的篡改检测方法
基于重叠块的篡改检测方法是将输入的图像划分为相互重叠的像素块,每一个像素块根据不同的变换计算规则得出相应的变换值,该变换值作为此像素块的特征值,由此作为检测该区域是否被篡改的依据。因此该方法的重点是依据相关数学原理在特征提取的过程中计算得到块特征。根据具体实现方法的不同,可将基于重叠块的检测方法再次细分为:(1)单一几何变换法;(2)复合几何变换法。
下面分别针对这两个角度阐述相关工作。
(1)单一几何变换法。单一几何变换法是指基于一种数字图像变换理论,实现高效快速地篡改检测。Fridrich等[7]提出一种基于频率的复制粘贴篡改检测方法,先将图片分割成相互重叠的块,利用离散余弦变换(Discrete Cosine Transform,DCT)提取出各个图像块的特征向量。通过匹配和滤波,两个相似的特征向量分别对应图像中两个相似区块,即复制粘贴篡改区域。Luo等[8]通过比较相似重叠快,使用主成分分析(Principle Component Analysis)的方法最终确定可能的重复区域,并且可以对经过处理的图像(比如对图像进行模糊化、噪声污染等)进行较好的复制粘贴篡改检测。
(2)复合几何变换法。为了进一步提高检测的准确性,一些工作融合不同的几何变换理论,使提取的图像块特征更接近于期望值。如Li G等[9]提出了一种基于离散小波变换(Discrete Wavelet Transform,DWT)和奇异值分解(Signal value Decomposition,SVD)的复制粘贴被动检测方法,首先将离散小波变换用于图像分割,通过奇异值分解对小波中的低频分量进行降维表示,然后按照字典顺序对向量进行分类,复制粘贴的图像块将分类在相邻列表,该方法通过降维操作不仅可以降低计算的复杂度,而且对于高度压缩的图像或者边缘处理的图像,也能准确定位篡改区域。在具体实现上与单一几何方法不同,作者充分利用DWT和SVD分别在图像块分割和降维特征提取方面的优势,实现了在检测效率和检测质量均良好的性能。
1.1.2基于特征点的篡改检测方法
1.2拼接组合篡改检测方法
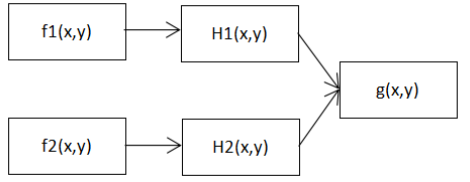
图3 拼接组合示意图
其中(x, y)表示像素点,f(x,y)表示图像在点(x, y)处的像素值。
1.2.1基于图像属性的篡改检测方法
1.2.2基于设备属性的篡改检测方法
现代多种数字设备(如数码相机、扫描仪、手机等)都可以生成数字图像,不同成像设备来源的数字图像虽然在视觉上并没有太大差异,但是由于各种设备特征的不同(如感光元件、颜色插值等),其产生的数字图像也会有不同的可分辨性特征,通过对这些设备属性特征的提取,使用相应的取证算法进行篡改检测。该方法可以从两个角度来实现,其一是根据彩色滤波阵列(Color Filter Array,CFA),其二是根据相机的传感器噪声(Sensor Noise)。数字图像成像过程如图4所示:
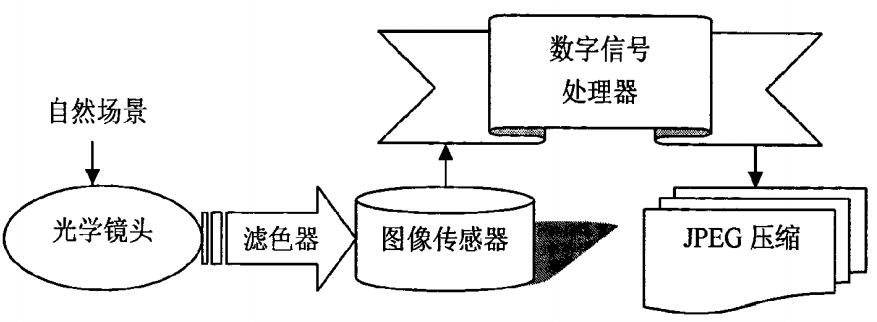
图4 数字图像成像过程
1.2.3基于压缩属性的篡改检测方法
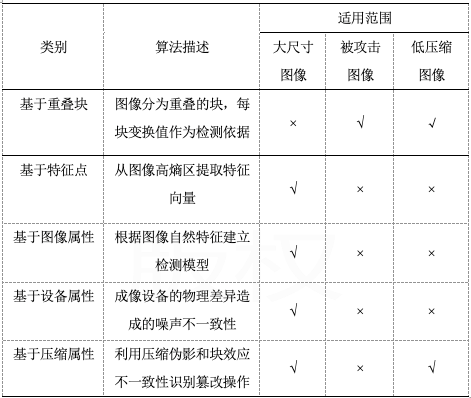
表1 传统篡改检测算法比较
其中,被攻击图像指的是经过处理的图像,比如对图像进行模糊化、噪声污染等。
2 基于卷积神经网络的篡改检测
近年来,随着深度学习技术的不断发展,卷积神经网络(Convolutional Neural Networks, CNN)[30]在特征提取方面的优异表现引起了图像取证领域学者的注意。在数字图像篡改检测方面,传统的篡改检测方法只是基于某种特定图像操作所引起的图像特征改变来进行分析,而卷积神经网络的优点在于其具有强大的特征学习能力,学习到的数据更能反映出数据的本质特征,有利于结果的分类和可视化。
Rao等[31]首次将卷积神经网络用于数字图像的篡改检测,该方法利用CNN从输入的RGB彩色图像中自动学习特征层次表示,为了保留更细微的篡改痕迹,作者使用Fridrich提出的空间丰富模型(Spatial Rich Model,SRM)[32]初始化网络参数,并采用特征融合技术得到最终判别特征。提出的方案与其它传统方法的检测性能进行了比较,如表2所示:

表2 首次基于CNN方法与传统方法的篡改检测准确率的比较
由表2可知,基于卷积神经网络的图像篡改检测算法在三个公开的数据集上的检测准确率均高于其他三个最新的传统篡改检测算法。由此,利用卷积神经网络提取数字图像的特征信息,可以更好地完成篡改图像的检测,随之研究者们提出了更多可观的思路和方案。
Zhang等[36]提出了一种两阶段的基于卷积神经网络的深度学习方法来学习篡改特征,第一阶段使用自动编码器模型来学习每个单独的篡改特征,第二阶段整合每个篡改特征的上下文信息以便更准确的进行检测,该方法不仅在JPEG文件格式的图像集上表现突出,而且对于CASIA数据集中的TIFF文件格式的图像上也实现了一定准确率的篡改检测。BAPPY等[37]从两阶段设计算法的思想中受到启发,采用了一个混合的CNN-LSTM模型来捕捉篡改区域和非篡改区域之间的区分特征,LSTM(Long Short Term Memory networks,长短期记忆模型)[38]是一种能够记录图像上下文信息的网络模型,作者的思路是将LSTM和CNN中卷积层的结合来理解篡改区域与非篡改区域共享的边界上像素之间的空间结构差异性,通过对网络端对端的训练以及利用反向传播机制让网络学习参数,整个框架能够检测包括复制粘贴和拼接组合不同类型的图像篡改操作。
Bondi等[39]结合图像成像设备属性的特点,提出了一种利用不同摄像机模型在图像上留下的特征足迹进行图像篡改检测和定位的算法,该算法的基本原理是,原始图像的所有像素都应该被检测为使用单一设备拍摄,相反如果通过拼接组合的篡改方式进行图像的合成,则可以检测出多个设备的痕迹。算法利用卷积神经网络从图像块中提取摄像机模型特征,然后利用迭代聚类的方法对特征进行分类以检测图像是否被伪造,并对篡改区域实现定位。该方法对于拼接组合篡改方式的图像具有很好的检测效果,但是对于复制粘贴的篡改图像,由于复制的部分来源于同一幅图像区域导致该方法不适用。
Liu等[40]提出了一种新的深度融合网络,通过跟踪篡改区域的边界来定位篡改区域。首先训练一组称为基网的深度卷积神经网络,分别对特定类型的拼接组合篡改进行响应,然后选取若干层基网络作为深度融合神经网络(Fusion Network,FN),融合网络通过对少量图像进行微调后,能够识别出图像块是否由不同的来源合成的。该方法中作者用大尺寸图像块作为网络的输入来揭示篡改区域的属性,但是当被篡改区域的尺寸较小时,该方法可能会失效。
为了学习更丰富的图像篡改特征,Zhou等[41]提出了一种双流Faster-RCNN网络,并对其进行端到端的训练,以检测给定的篡改图像区域。同时借助Faster-RCNN在目标检测领域的应用[42,43],该网络不仅能准确定位篡改区域,还能标注出篡改类型,如是否为复制粘贴篡改等。网络结构如图5所示:
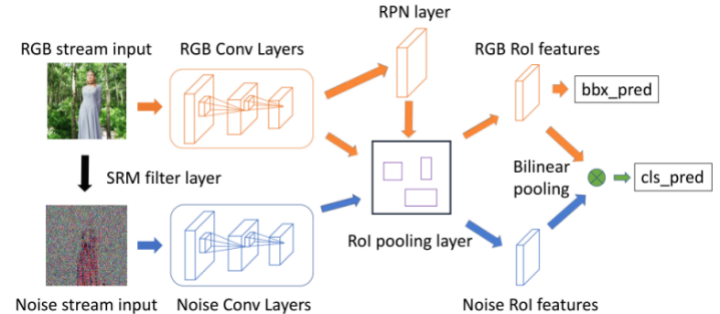
图5 双流Faster-RCNN网络结构示意图
其中,双流之一是RGB流,其目的是从输入的RGB图像中提取特征,以查找篡改伪影,如强对比度、非自然边界等。双流之二为噪声流,是利用富文本分析模型(SRM)滤波层中提取的噪声特征来揭示真实区域和篡改区域之间的噪声不一致性特征,然后通过双线性池化层融合来自两个流的特征,以进一步合并这两种模式的空间特性,提高检测准确性。该算法的贡献为(1)展示了Faster-RCNN网络如何适应图像篡改检测的双流模式;(2)证明了RGB流和噪声流对于检测不同的篡改方式是互补的。为之后做此方向继续深入研究的学者供了创新思路。
虽然上述基于深层网络结构的图像篡改算法可以学习到更高级的语义信息,但对篡改区域的检测和定位效果并不理想。基于此,Bi等[44]提出了一种基于级联卷积神经网络的图像篡改检测算法,在卷积神经网络的普遍特性的基础上,利用浅层稀神经元的级联网络代替以往深层次单一网络。该算法分为两部分:
(1)级联卷积神经网络;
(2)自筛选后处理;前者学习图像中篡改区域和非篡改区域的属性差异,实现多层级篡改区域定位,后者对级联神经网络的检测定位结果进行优化。
算法检测流程如图6所示:

图6 基于级联卷积神经网络算法的检测流程

为了进一步提高基于卷积神经网络的篡改检测方法的性能和检测效率,2019年Bi等又提出了一种环形残差网络(RRU-Net)[45],可直接定位篡改区域而无需额外的预处理和后处理操作。该网络包含两个关键步骤:残差传播(Residual Propagation)和残差反馈(Residual Feedback),前者主要用于解决网络中梯度退化的问题,后者使篡改区域和非篡改区域的差异对比更加明显。作者提出残差反馈的背景是:在文献[41]中,Zhou使用SRM进一步放大差异,但存在一个缺点,即当被篡改区域和未被篡改区域来自同一相机品牌或型号时,由于它们具有相同或相似的噪声分布,SRM滤波器的帮助将非常小,而残差反馈的方法不仅仅关注一个或几个特定的图像属性,更加关注于输入信息中可辨识的特征。目前,该方法在检测效果上取得了良好的性能,并且在运算效率方面具有较大的优势。
3 未来发展趋势
推荐阅读
