
基于卷积神经网络的地铁平台人群计数
点击下方“AI算法与图像处理”,一起进步!
重磅干货,第一时间送达
1.文章简介
本次介绍的是一篇2021年发表的名为《ConvolutionalNeural Network for Crowd Counting on Metro Platforms》的有关计算机视觉的文章
2.摘要
随着城市轨道交通的使用增加,地铁站台上的客流在高峰期往往会急剧增加,出于安全原因,监控这些地区的客流非常重要。为了解决地铁站台客流检测问题,文章提出了一种基于卷积神经网络的网络,称为MP(Metro Platform)-CNN,以准确统计地铁站台上的人数。
该方法由三个主要部分组成:
1. 前端使用一组卷积神经网络提取图像特征
2. 多尺度特征提取模块用于增强多尺度特征
3. 转置卷积用于上采样以生成高质量密度图
由于现有的人群统计数据集不能满足文章研究所需,因此,我们从地铁站台的监控视频中收集图像,形成包含627幅图像的数据集,其中有9243个带注释的头部。大量实验结果表明,该方法在自建数据集上表现良好,估计误差最小。
3.模型
模型结构

文章使用VGG-16的前13层作为特征提取的前端网络,并且只有一个3 × 3卷积核。选择VGG作为前端有两个原因:
一方面,它具有优秀的特征提取能力和对分类任务较强的迁移学习能力;
另一方面,VGG具有灵活的架构,这使得连接到后端网络以生成密度图变得容易。
经过前端网络中的一系列卷积层和汇集层,输出特征图的大小是原始输入的1/8。
如果继续叠加更多的卷积图层和汇集图层,输出要素图的大小可以进一步缩小,生成高质量的密度图变得困难。因此,在前端处理后,文章引入了MFEM,它可以在保持输出密度图分辨率的同时提取更深层次的信息。本模块中使用了下图中(b)所示的扩张卷积:
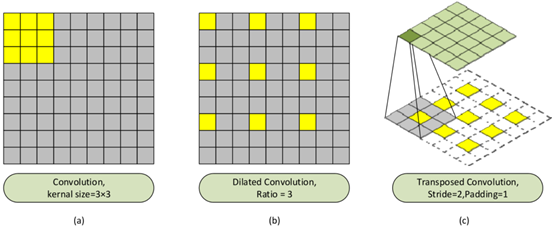
由于在特征提取过程中对图像进行下采样,输出特征的分辨率降低,并且丢失了相当多的细节,所以为了获得高分辨率密度图,文章使用一组转置卷积在MFEM后对图像进行上采样。转置卷积不是普通卷积的完全逆过程,而是特殊卷积。首先通过按照一定的比例用0填充图像来扩展图像大小。然后旋转卷积核,并执行正向卷积,如上图(c)所示。与以前的方法不同,文章选择了一种可学习的换位卷积,而不是双线性插值算法进行上采样。转置卷积不同于双线性插值,它有可以学习的参数,这意味着它可以比双线性插值学习更多的特征。
转置卷积层用于恢复图像的空间分辨率。每个转置的卷积图层都会使feature map的大小加倍,与之前的max-pooling层相对应。网络中使用三个转置卷积层来生成与输入图像大小相同的高分辨率密度图。这提供了详细的空间信息,以便在训练模型时促进特征学习。
多尺度特征提取模块(MFEM)
由于地铁站台上候车乘客的复杂分布、摄像头的视角以及其他问题,拍摄图像中乘客的头部大小各不相同。此外,来自站台、电梯和其他小型设施上的屏蔽门的反射会导致背景信息的复杂变化。
本文引入多尺度特征提取模块来解决这一问题。所提出的MFEM改进了多尺度特征提取,以增强特征图的每一层中的信息。

如上图所示,MFEM首先通过1 × 1卷积压缩特征图的通道,然后通过扩张卷积处理压缩后的特征图,不同的扩张比为1、2、3和4,以处理图像中的多尺度特征和头部大小的变化。本文中固定高斯核的大小设置为15。在生成的密度图中,每个注释头的大小为15×15,用一些0填充图像不会影响计数结果。扩张卷积在保持参数个数不变的情况下,扩大了卷积核的感受野,这样做可以加快运行速度。扩张卷积的示意图如上面的图中的(b)所示,其中扩张比为3。提取的多尺度特征图通过拼接操作和3× 3卷积进行融合,处理后的特征图像的大小与输入图像的大小相同。
这部分设计的关键部分是扩张的卷积层,扩张卷积可以定义如下:
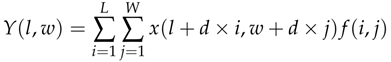
y(l,w)是来自输入x(l,w)的扩张卷积的输出,滤波器f(I,j)的长度和宽度分别为L和W,参数d代表扩张速度。当d=1时,扩张的卷积转化为正常的卷积。
生成ground truth的方法
在人群计数研究中,使用的数据集通常由原始图像和注释文件组成。人群图像的注释包括每个乘客头部中心的点,记录每个头部的二维(2D)坐标和头部总数。这需要将这些离散坐标点转换成密度图,以预测乘客密度.
ground-truth density map是通过将每个δ函数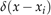 与归一化高斯核Gσ卷积生成的:
与归一化高斯核Gσ卷积生成的:
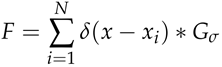
其中x代表给定图像中的每个像素,是第i个注释点,N是所有注释点的集合。密度图的积分等于图像中的人数。文章使用固定的高斯核来生成ground-truth density maps,高斯核的扩展参数σ设置为15。
所有像素值的总和给出了输入图像中人群中的人数。p表示乘客数量,定义如下:
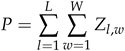
其中L代表密度图的长度,W代表密度图的宽度。此外,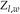 是生成的密度图中
是生成的密度图中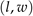 处的像素
处的像素
训练细节
以端到端的方式训练MP-CNN,在ImageNet上训练的VGG网的权重参数用于预处理。作者在NVIDIAQuadro P4000 GPU上进行实验,使用pytorch框架,batch size=1,epoch=500,损失函数定义如下:

θ表示所提出的MP-CNN中的一组参数,N是训练图像的数量,Xi表示输入图像,fidenotes表示图像Xi的ground-truth density map,代表由MP-CNN生成的估计密度图,用θ为样本参数化,L是估计密度图和ground-truth density map之间的损失。
训练细节
以端到端的方式训练MP-CNN,在ImageNet上训练的VGG网的权重参数用于预处理。作者在NVIDIAQuadro P4000 GPU上进行实验,使用pytorch框架,batch size=1,epoch=500,损失函数定义如下:
θ表示所提出的MP-CNN中的一组参数,N是训练图像的数量,Xi表示输入图像,fidenotes表示图像Xi的ground-truth density map,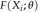 代表由MP-CNN生成的估计密度图,用θ为样本参数化,L是估计密度图和ground-truth density map之间的损失。
代表由MP-CNN生成的估计密度图,用θ为样本参数化,L是估计密度图和ground-truth density map之间的损失。
4.实验
数据集
在几个人群计数基准数据集以及本文收集的数据集(地铁平台)上评估了文章提出的模型:ShanghaiTech Part A and Part B,UCF-QNRF,UCF-CC-50,还有文章建立的Metro Platform,这些数据集的比较如下:
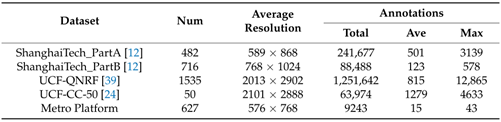
Num是图像的数量,Total是标记的总人数,Ave是平均人群计数,Max是最大人群计数
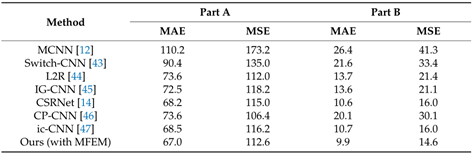
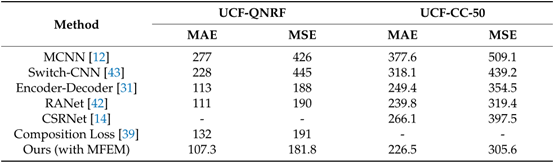
使用平均绝对误差(MAE)和均方误差(MSE)作为度量标准,来评估这些方法在计算人群成员方面的准确性,在实验中引入了在密集人群数据集上训练的模型作为预处理模型,不同方法的性能比较如下表:

不同方法得到的密度图如下:

不同方法在ShanghaiTech Part A and Part B上的表现结果:
不同方法在UCF-QNRF,UCF-CC-50上的表现结果:
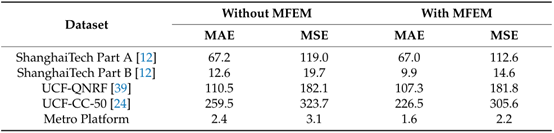
多尺度特征提取模块的消融实验结果:
5.结论
文章提出了一种新的方法来计算地铁站台上人群的数量,称为MP-CNN。引入了MFEM来增强多尺度网络的特征提取能力,解决了图像中不同遮挡和乘客头部大小变化的问题。该方法对地铁站台的公共安全具有重要意义;地铁工作人员可以根据乘客数量引导和疏导人流。通过对比实验验证了所提出的MFEM算法的有效性。特别是为了评估它在地铁平台上的有效性,文章收集并标记了一个新的数据集,称为地铁平台数据集,由9243个带注释的人的627幅图像组成。大量实验的结果表明,文章提出的方法在所提出的Metro Platform数据集上提供了出色的结果,并且可以在四个主要人群计数基准中与最先进的方法竞争。
Attention
努力分享优质的计算机视觉相关内容,欢迎关注:
个人微信(如果没有备注不拉群!)
请注明:地区+学校/企业+研究方向+昵称
下载1:何恺明顶会分享
在「AI算法与图像处理」公众号后台回复:何恺明,即可下载。总共有6份PDF,涉及 ResNet、Mask RCNN等经典工作的总结分析
下载2:终身受益的编程指南:Google编程风格指南
在「AI算法与图像处理」公众号后台回复:c++,即可下载。历经十年考验,最权威的编程规范!
下载3 CVPR2021
在「AI算法与图像处理」公众号后台回复:CVPR,即可下载1467篇CVPR 2020论文 和 CVPR 2021 最新论文
点亮  只需一秒,我却能开心一天
只需一秒,我却能开心一天