
利用Python对全国 40城 5000+ 地铁站点进行数据分析实战
今天这篇文章,是通过对爬取到的 40 个已开通地铁的城市,共计 5000+ 地铁站点进行数据分析。
首先有一点常识需要普及:在部分城市是存在环线,或者地铁一期、二期等情况,对应的地铁站点会多次出现,在数据中表现为重复值,所以,第一件事,就是对这些重复数据的剔除。

"""删除完全重复的站点"""df_data_1 = df_data.drop_duplicates()df_data_1
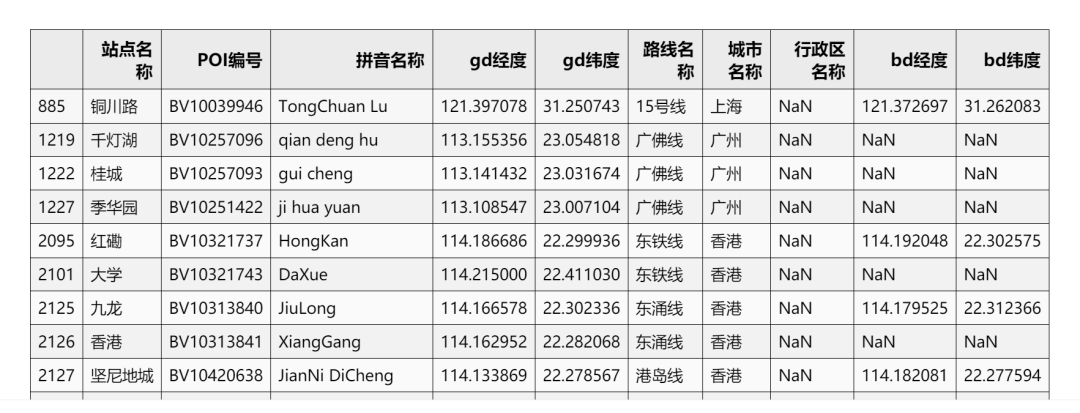
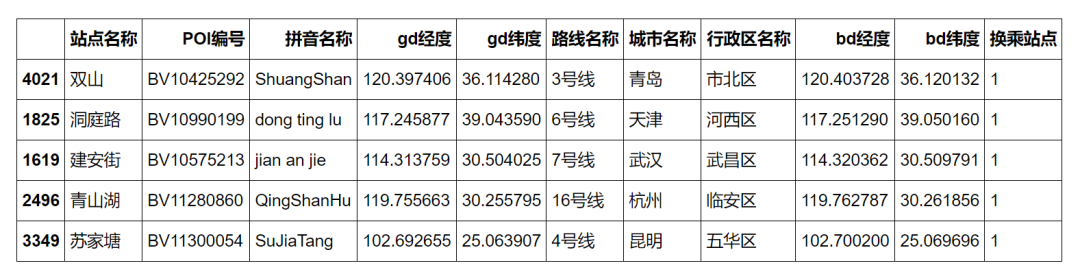
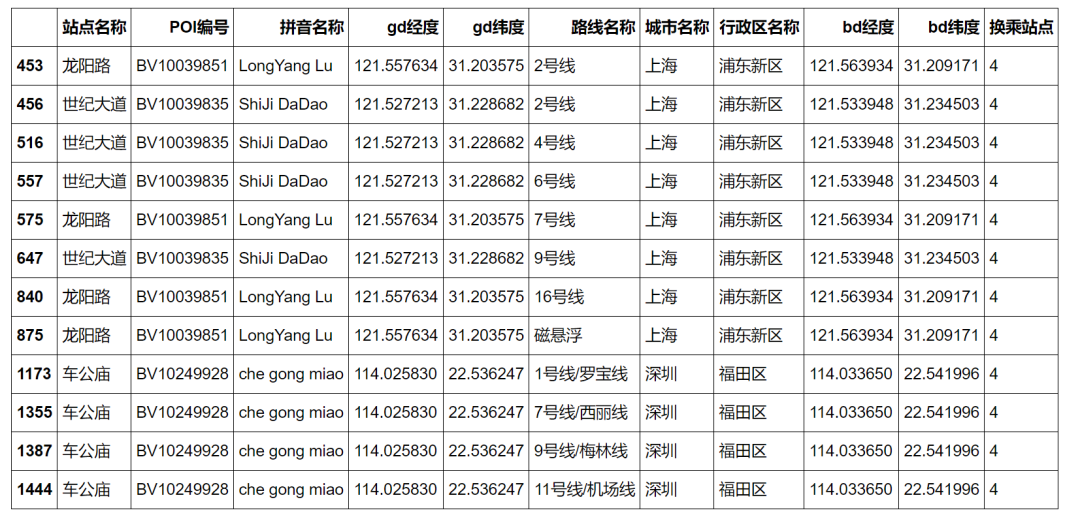
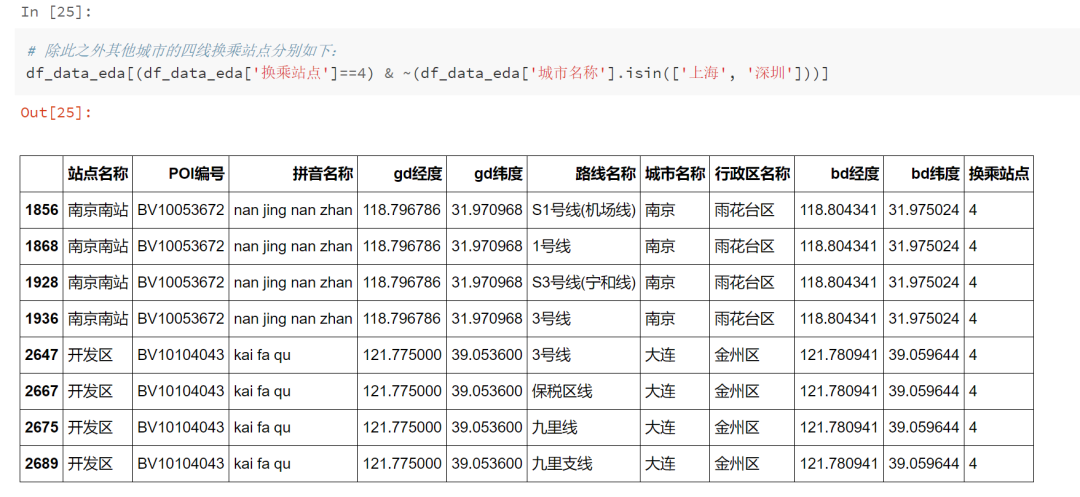
df_data_2 = df_data_notnull.copy()df_address_cnt = df_data_2.groupby(['城市名称', '站点名称']).agg({'拼音名称':'count'}).reset_index().rename(columns={'拼音名称': '换乘站点'})df_data_3 = df_data_2.merge(df_address_cnt, on=['城市名称', '站点名称'], how='left')df_data_3.sample(5)
绘图和分析的代码重复性比较高,只列举部分,具体可以查看源码
df_data_eda = df_data_3.copy()"""查看城市的地铁站点数量"""df_city_cnt = df_data_eda.groupby('城市名称').agg({'站点名称':pd.Series.nunique}).reset_index().rename(columns={'站点名称': 'metro_cnt'})# 设置标题plt.figure(figsize=(20, 8))plt.title('全国40城市地铁站点数量分布')ax = sns.barplot(data=df_city_cnt, x='城市名称', y='metro_cnt')plt.ylabel('地铁站点数量')# 显示数据的具体数值for x, y in zip(range(0, len(df_city_cnt['城市名称'].index.tolist())), df_city_cnt['metro_cnt'].values.tolist()):ax.text(x-0.3, y+0.5, '%d' % y, color='black')plt.show()
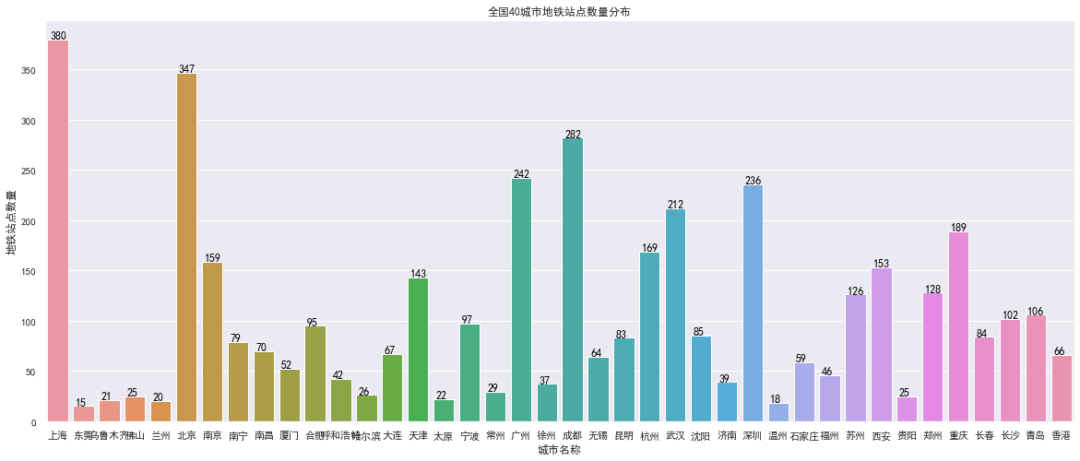
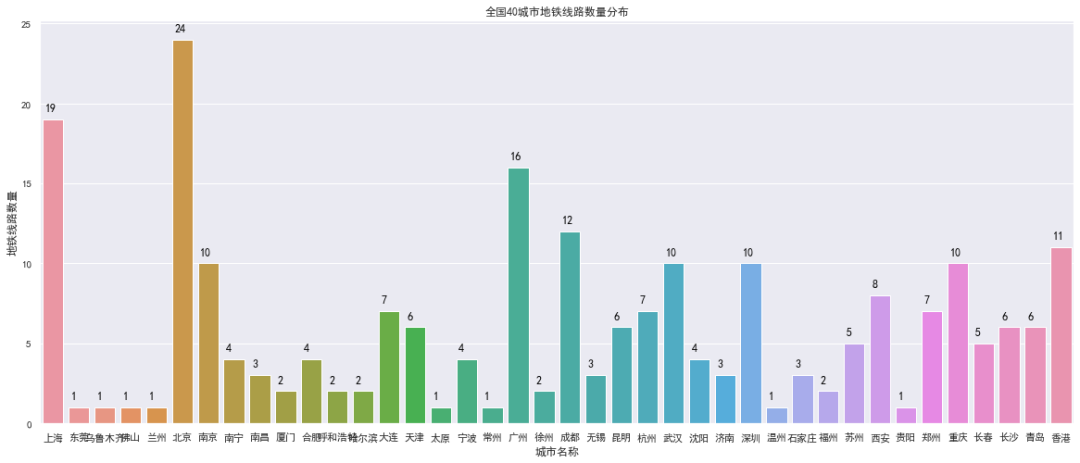
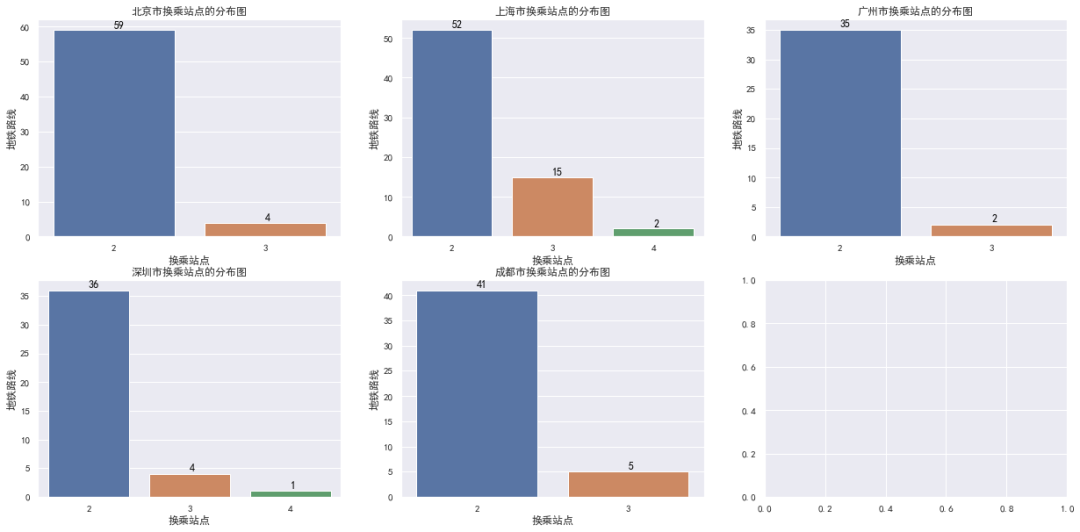
对北上广深成五大城市分别进行深度分析,对北京市各区域的站点数量进行深度分析,如下:

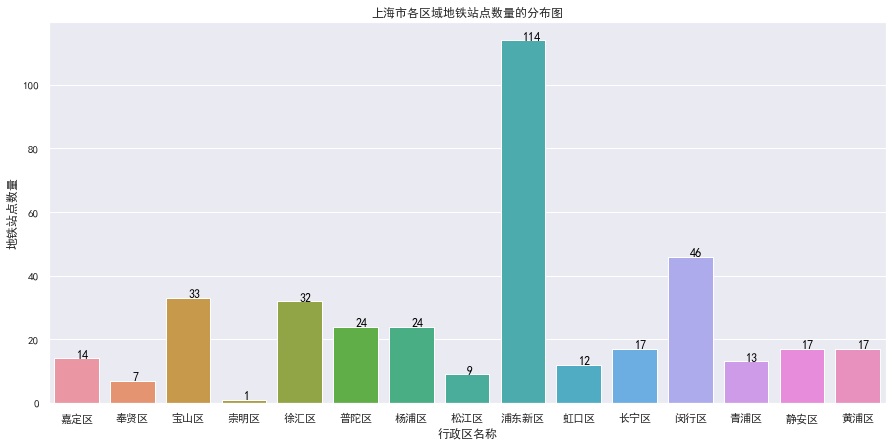

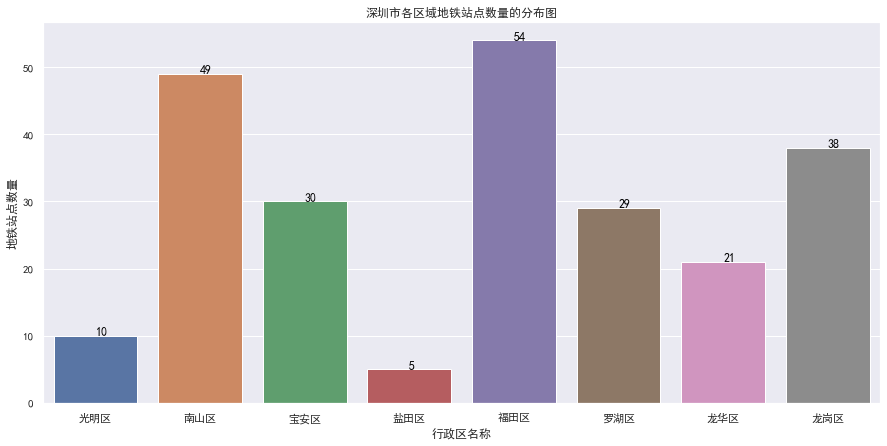
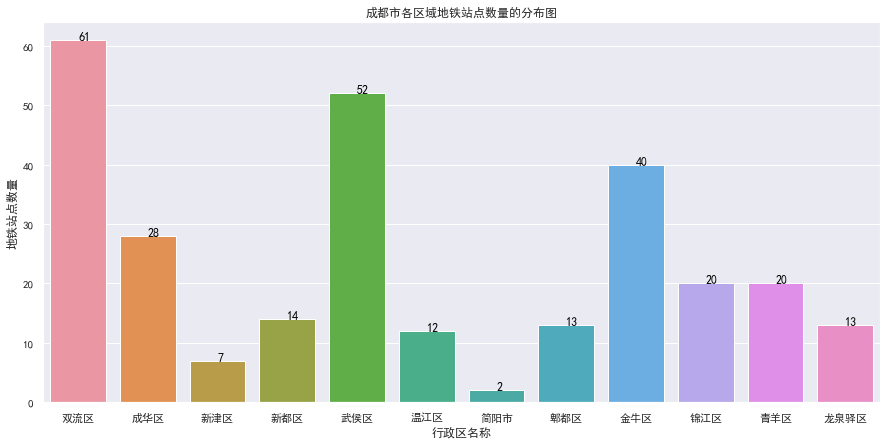
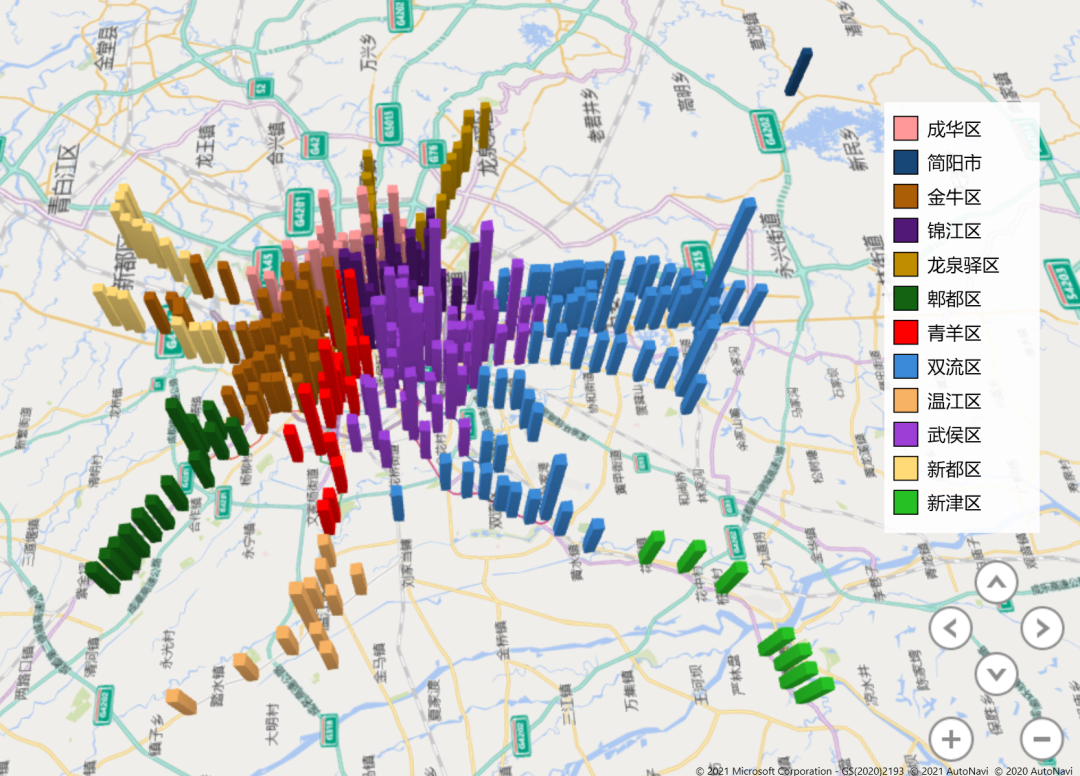
最后,通过 excel 的三维地图再来看看上面5个城市的聚集效应到底如何




通过客流量数据,结合地铁站点进行日内用户轨迹分析 通过租房数据,结合距离进行房价的进一步探索 通过地产数据,结合地铁站点进行价值分析





评论