
利用python进行基金数据分析
背景说明
本文主要是利用Python提取并分析相关数据,看下当前基金市场上存在哪些类型的基金,作为新手如何判断一支基金是否值得购买。
分析过程
1.获取所有种类基金数据
1.1导入相关包
import pandas as pd
import re
import numpy as np
from bs4 import BeautifulSoup
import requests
import matplotlib.pyplot as plt
%matplotlib inline # 解决图表在jupyter的显示问题
# 解决中文和‘-’号在jupyter的显示问题
plt.rcParams['font.sans-serif']='SimHei'
plt.rcParams['axes.unicode_minus']=False
1.2通过天天基金网接口获取基金数据
1.2.1获取网页信息
url='http://fund.eastmoney.com/js/fundcode_search.js'
num=requests.get(url)
# 通过正则表达式获取基金信息
text=re.findall(r'"(\d*?)","(.*?)","(.*?)","(.*?)","(.*?)"',num.text)
1.2.2将数据转化成二维表并写入本地磁盘(dataframe)
# 转化为二维表
基金代码=[]
基金名称=[]
基金类型=[]
for i in text:
content=list(i)
基金代码.append(content[0])
基金名称.append(content[2])
基金类型.append(content[3])
基金信息=pd.DataFrame({<!-- -->'代码':基金代码,'名称':基金名称,'类型':基金类型})
# 写入到本地磁盘,想到后续会在excel做一些分析,先把数据下载下来
writer=pd.ExcelWriter(r'D:\工作文档\工作\2020\11月\python\基金数据导出.xlsx')
基金信息.to_excel(writer,sheet_name='基金信息',index=False)
writer.save()
writer.close()
1.3数据概览
1.3.1查看前几行数据
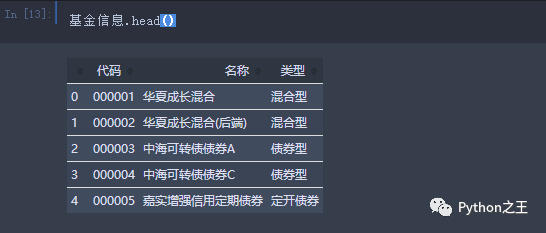
1.3.2查看各类型基金分布及可视化展示
# 按照类型进行分组
分组数量=基金信息.groupby('类型').agg(基金数量=('类型','count')).\
sort_values(by='基金数量',ascending=False).reset_index('类型')
# 图表展示
plt.style.use('ggplot')
fig=plt.figure(figsize=(20,8))
plt.xticks(fontsize=12)
plt.yticks(fontsize=12)
plt.bar(x='类型',height='基金数量',data=分组数量)
for a,b in zip(range(len(分组数量.类型)),分组数量.基金数量):
plt.text(a,b,b,ha='center',va='bottom',fontsize=16)
plt.title('各类基金数量',fontdict={<!-- -->'fontsize':20})
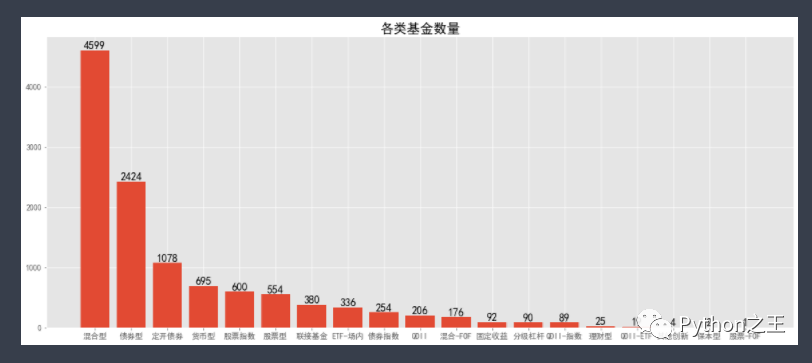
分析:
通过图表看到,目前市面上基金数量前五的类别分别是混合型、债券型、定开债券、货币型和股票指数型。一般来讲,数量越多表明受到投资者喜爱的程度越高。- 针对不同类型的基金,可通过了解他们的特点然后结合自己的自身情况选择购买某一种类型的基金。
2.对某支基金进行分析
背景: 通常在购买某支基金前,需要对其历史净值信息、历史涨跌等信息进行充分了解再决定是否购买,以下通过简单的分析看下当下某支基金是否值得购买。
2.1定义抓取函数
# 这里通过天天基金网的数据接口,通过输入基金代码、查询的起始时间获取基金数据
# 抓取网页
def get_url(url, params=None, proxies=None):
rsp = requests.get(url, params=params, proxies=proxies)
rsp.raise_for_status()
return rsp.text
# 从网页抓取数据
def get_fund_data(code,per=10,sdate='',edate='',proxies=None):
url = 'http://fund.eastmoney.com/f10/F10DataApi.aspx'
params = {<!-- -->'type': 'lsjz', 'code': code, 'page':1,'per': per, 'sdate': sdate, 'edate': edate}
html = get_url(url, params, proxies)
soup = BeautifulSoup(html, 'html.parser')
# 获取总页数
pattern=re.compile(r'pages:(.*),')
result=re.search(pattern,html).group(1)
pages=int(result)
# 获取表头
heads = []
for head in soup.findAll("th"):
heads.append(head.contents[0])
# 数据存取列表
records = []
# 从第1页开始抓取所有页面数据
page=1
while page<=pages:
params = {<!-- -->'type': 'lsjz', 'code': code, 'page':page,'per': per, 'sdate': sdate, 'edate': edate}
html = get_url(url, params, proxies)
soup = BeautifulSoup(html, 'html.parser')
# 获取数据
for row in soup.findAll("tbody")[0].findAll("tr"):
row_records = []
for record in row.findAll('td'):
val = record.contents
# 处理空值
if val == []:
row_records.append(np.nan)
else:
row_records.append(val[0])
# 记录数据
records.append(row_records)
# 下一页
page=page+1
# 数据整理到dataframe
np_records = np.array(records)
data= pd.DataFrame()
for col,col_name in enumerate(heads):
data[col_name] = np_records[:,col]
return data
2.2获取基金净值信息
#这里提取招商中证白酒基金作分析
found_code='161725'
start_date='2015-01-01'
end_date='2020-12-22'
增长率基准=0
if __name__ == "__main__":
data=get_fund_data(found_code,per=49,sdate=start_date,edate=end_date)
2.3 查看数据字段和数据内容
data.info()
data.head()
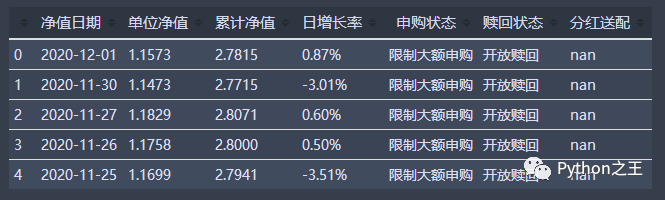
可以看到主要字段是日期、单位净值、累计净值和日增长率,这些都是后面分析的重要指标- 这里我们取了5年多的数据,差不多有一千三百多条数据,扣除节假日,数据量基本是对的,后续可通过查看某年或某月的数据进行验证。同时导出来的数据不存在缺失值,数据质量较好。
2.4历史净值数据可视化分析
# 修改数据类型
data['净值日期']=pd.to_datetime(data['净值日期'],format='%Y/%m/%d')
data['单位净值']= data['单位净值'].astype(float)
data['累计净值']=data['累计净值'].astype(float)
data['日增长率']=data['日增长率'].str.strip('%').astype(float)
# data['日增长率']=data['日增长率'].astype(float) #上面那句出错的情况用这一句转化,格式问题
data['基准值']=增长率基准
# 按照日期升序排序并重建索引
data=data.sort_values(by='净值日期',axis=0,ascending=True).reset_index(drop=True)
# 获取净值日期、单位净值、累计净值、日增长率等数据并
net_value_date = data['净值日期']
net_asset_value = data['单位净值']
accumulative_net_value=data['累计净值']
daily_growth_rate = data['日增长率']
daily_jizhun=data['基准值']
# 作基金净值图
fig = plt.figure(figsize=(16,10),dpi=240)
#坐标轴1
ax1 = fig.add_subplot(211)
ax1.plot(net_value_date,net_asset_value,label='基金净值')
ax1.plot(net_value_date,accumulative_net_value,label='累计净值')
ax1.set_ylabel('净值数据')
ax1.set_xlabel('日期')
plt.legend(loc='upper left')
#坐标轴2
ax2 = fig.add_subplot(212)
ax2.plot(net_value_date,daily_growth_rate,'r',label='日增长率')
ax2.plot(net_value_date,daily_jizhun,'b',label='增长率基准值')
ax2.set_ylabel('日增长率(%)')
plt.legend(loc='upper right')
plt.title('基金净值数据')
plt.show()
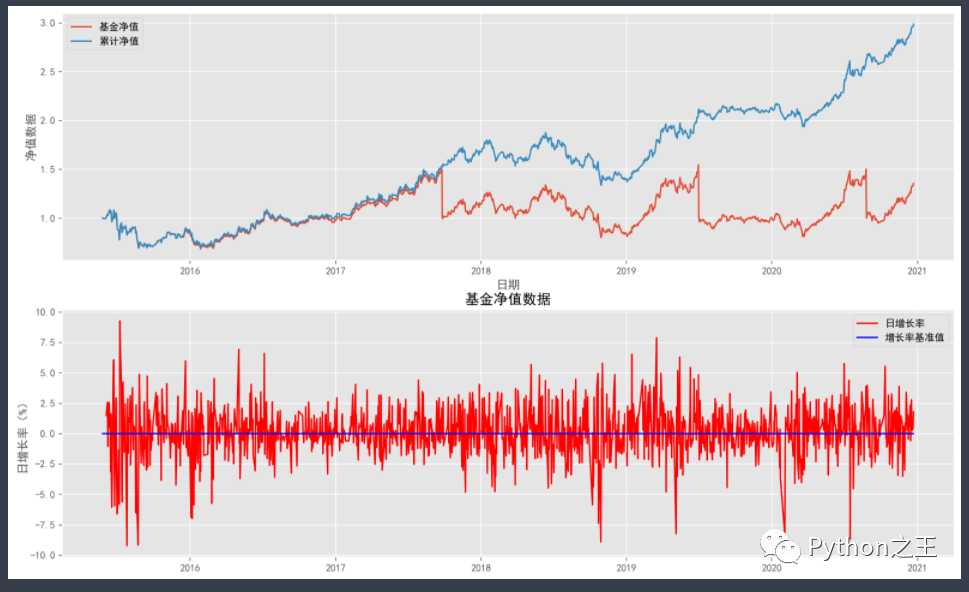
从整体趋势上看,该基金自成立后累计净值呈现的是向上走的趋势,中间也有过几次分红的情况,因此这是一支盈利水平较为不错的基金,从长期看,该基金有比较大的概率可以盈利。同时目前净值属于历史最高水平,如果进场遇到回调,可能导致资金被套住,应该注意风险把控。- 从日增长率上看,该基金增长率整体波动范围不大,较为稳定。
2.5查看每年增长率正负的天数
2.5.1增加“年”字段
data1=data.iloc[:,0:4] # 这里提取后面分析需要用到的字段
data1['年']=data1['净值日期'].dt.year # 增加“年”字段
2.5.2正增长和负增长的数量及年度增长平均值
# 获取正增长年月和负增长年月数据
data1_inc=data1[data1['日增长率']>0]
data1_des=data1[data1['日增长率']<0]
data1_g_inc=data1_inc.groupby('年',as_index=False).agg({<!-- -->'日增长率':'count'}).rename(columns\
={<!-- -->'日增长率':'正增长数量'})
data1_g_des=data1_des.groupby('年',as_index=False).agg({<!-- -->'日增长率':'count'}).rename(\
columns={<!-- -->'日增长率':'负增长数量'})
data_g=pd.merge(data1_g_inc,data1_g_des,on='年',how='left')
# 转化百分比函数
def baifenbi(x):
return ('%.2f%%'%(x*100))
data_g['正增长占比']=(data_g['正增长数量']/(data_g['正增长数量']+data_g['负增长数量']))
data_g['正增长占比']=data_g['正增长占比'].apply(baifenbi)
data_g
计算每一年的平均增长率
data_year_rate=data1.groupby('年',as_index=False).agg({<!-- -->'日增长率':'mean'}).rename(columns={<!-- -->'日增长率':'日增长率均值'})
data_year_rate.head(6)
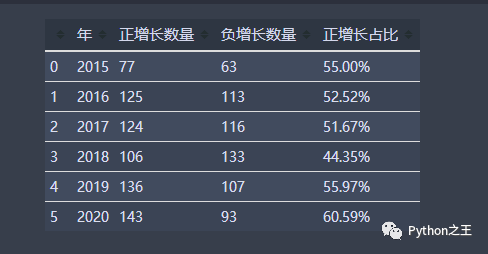
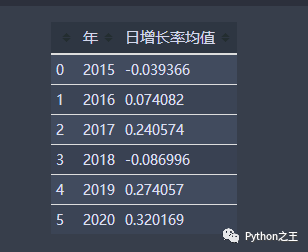
通过分析15年到20年的数据可知,除了18年股市整体大跌之外。其他年份日增长率为正的天数都是比负的多;再通过分析当年日增长率均值可看出,除了15年和18年日增长率均值为负,其他年份的均值均为正且绝对值相对来说比15年和18年的要大。因此如果长期持有的话,该基金还是能够有较大的盈利效应。
说明:这里只是利用python做一个简单的数据分析,具体选择基金的时候还需要注意到其他方面的问题。


Python“宝藏级”公众号【Python之王】专注于Python领域,会爬虫,数分,C++,tensorflow和Pytorch等等。
近 2年共原创 100+ 篇技术文章。创作的精品文章系列有:
日常收集整理了一批不错的 Python 学习资料,有需要的小伙可以自行免费领取。
获取方式如下:公众号回复资料。领取Python等系列笔记,项目,书籍,直接套上模板就可以用了。资料包含算法、python、算法小抄、力扣刷题手册和 C++ 等学习资料!
评论