
【论文解读】YOLOX: Exceeding YOLO Series in 2021
导读
旷视团队对YOLO系列的再一次超越。
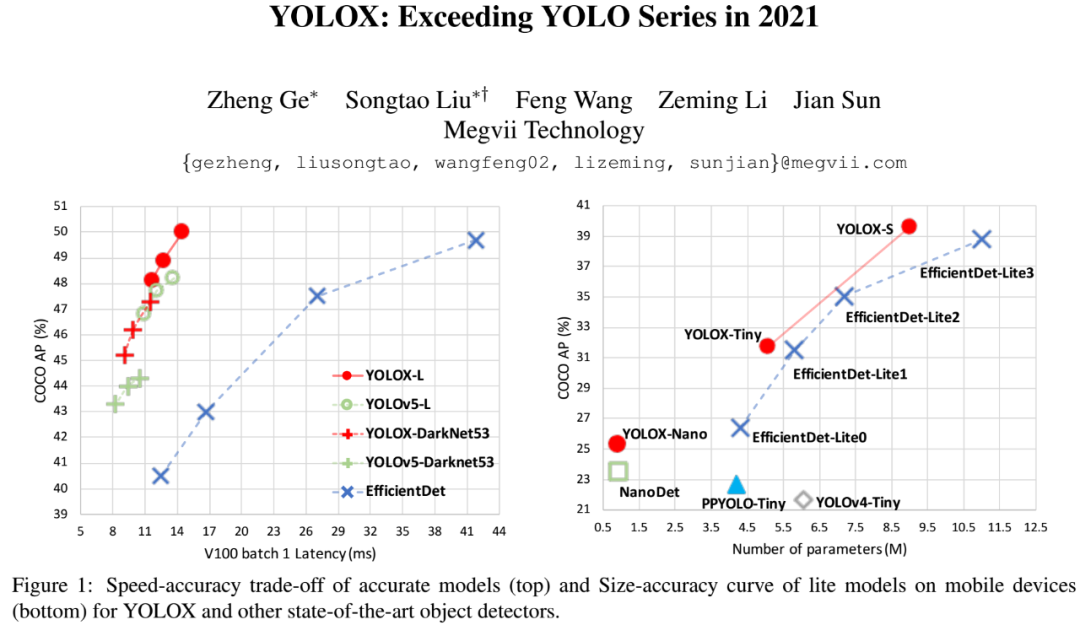
论文链接:https://arxiv.org/abs/2107.08430
1.1 YOLOX-DarkNet53
YOLOv3 baseline 以Darknet53作为Baseline,给大家介绍如何一步一步过渡到现在的YOLOX-DarkNet53。YOLOv3是以Darknet53为主干,后面再加上SPP。我们对训练策略进行了一些修改,增加了EMA weights updating,余弦学习率,IoU损失,以及IoU-aware分支,在训练分类和objectness的分支中,我们使用了BCE loss。在数据增强方面,我们只使用了水平翻转,颜色抖动和多尺度。
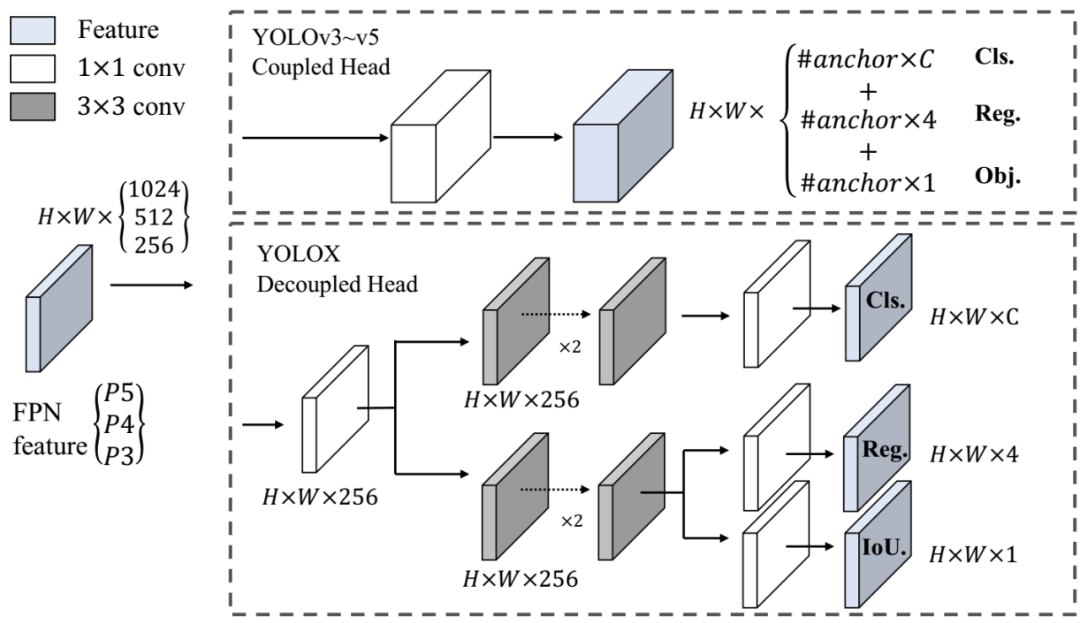
Decoupled head 在目标检测中,分类和回归的任务是有相互冲突的,这是个普遍认可的问题。因此,一般会将分类和回归分开2个分支,但是在YOLO系列中,仍然是没有分开的。这里,我们将耦合的检测头分开,变为2个相互独立的检测分支。具体如下图:
Strong data augmentation 在数据增强中,我们使用了Mosaic和Mix up的增强策略,使用了这些增强策略之后,我发现预训练模型已经没有必要了,因此后面所有的训练都是从头训练的。
Anchor-free 将YOLO转换为anchor free其实很简单,我们将每个空间位置的输出由3减少到1,直接输出4个值,即左上角点的两个偏差值,以及宽和高。对于每个目标,其中心点位置所在的区域即为正样本,并预先定义一个尺度范围,将每个目标分配到不同的FPN层上。
Multi positives 上面提到的anchor free的正样本选择策略,对于每个目标只选择了1个正样本,这样会忽略掉其他的高质量的预测,使用这些高质量的预测对于梯度是有好处的,而且样本的不均衡性也会减少一些。这里,我们简单的使用了中心点3x3的区域,都作为正样本。
SimOTA 对于标签的分配,我们总结了4个关键点:1)损失/质量相关性 2)中心优先 3)每个GT的正样本anchor点的动态数量 4)全局视角。我们使用OTA作为候选的标签匹配策略。然后对OTA进行了修改,提出了SimOTA。首先,计算每个prediction-gt对的匹配度,用损失和质量来表示,这里,在SimOTA中,使用损失来表示:
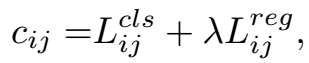
其中,λ是平衡系数,然后,对于一个gt,用gi来表示,我们选择在一个固定的中心区域内,topk个具有最小的cost的预测来作为正样本,最后,这些正样本所在的grid也被分配为正样本,其他的grid是负样本,注意,对于不同的gt,k是不一样的。
End-to-end YOLO 我们增加了2个额外的卷积层,进行一对一的标签分配,不需要梯度。这使得检测器可以端到端的运行,这个略微降低了性能和速度。所以作为可选项。
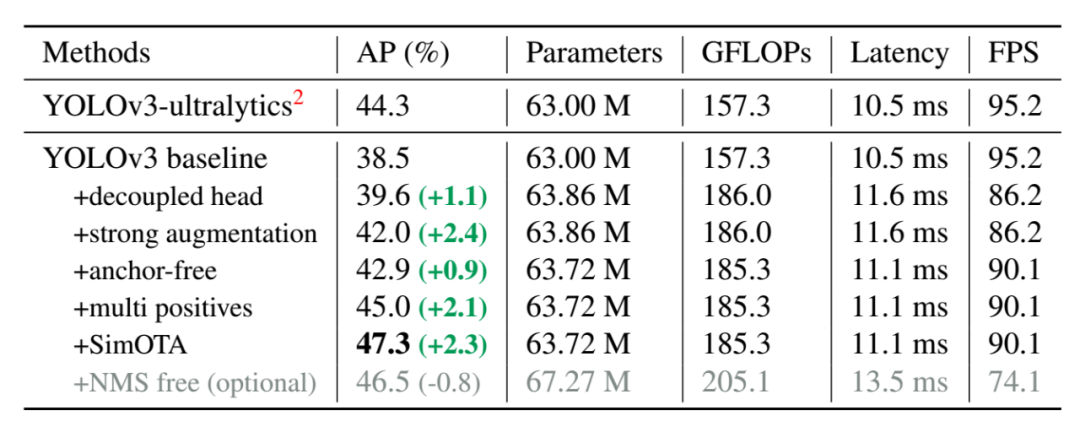
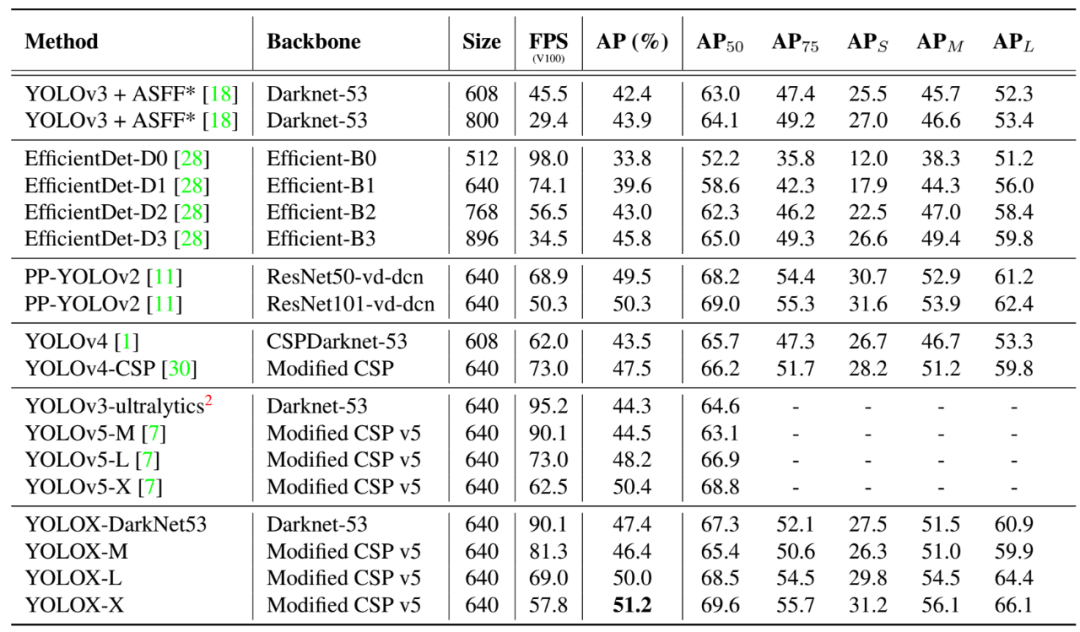
具体的各种修改的效果如下:
1.2 其他的backbone
我们还测试了其他的主干。
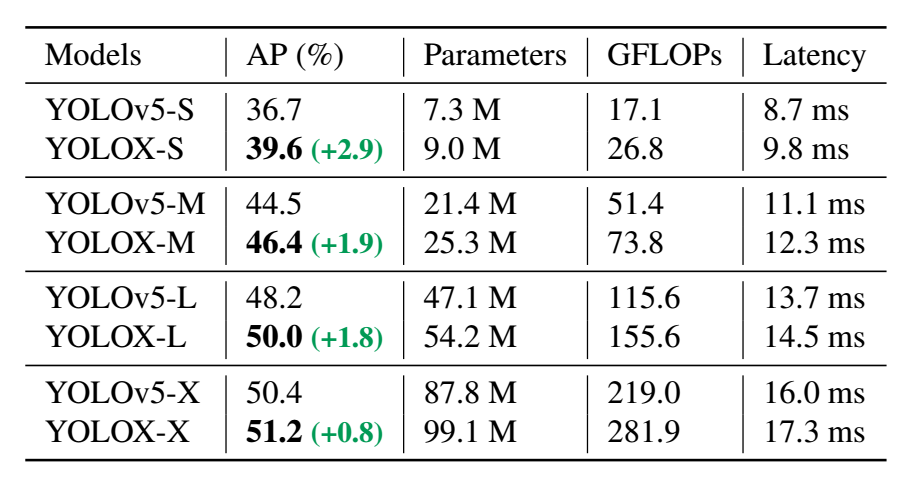
Modified CSPNet in YOLOv5
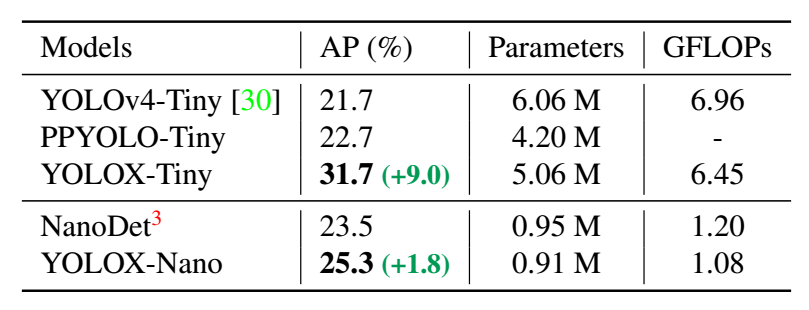
Tiny and Nano detectors
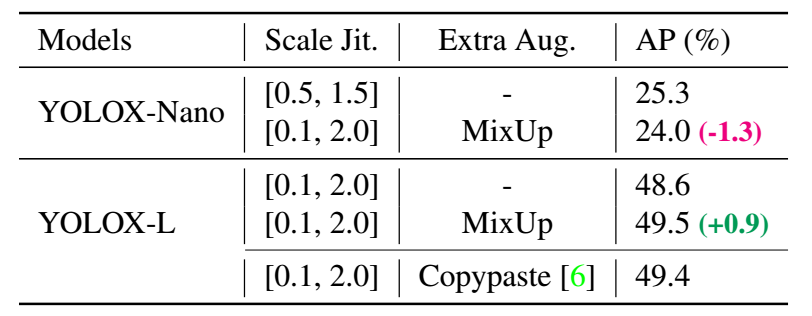
Model size and data augmentation
 —END—
—END—论文链接:https://arxiv.org/abs/2107.08430
往期精彩回顾本站qq群851320808,加入微信群请扫码: