
OpenAI CLIP 论文解读
GiantPandaCV导语:视频内容主要是讲解 CLIP 这篇文章的思路,值得一看
点击小程序卡片观看视频
视频太长不看版:
CLIP 训练阶段
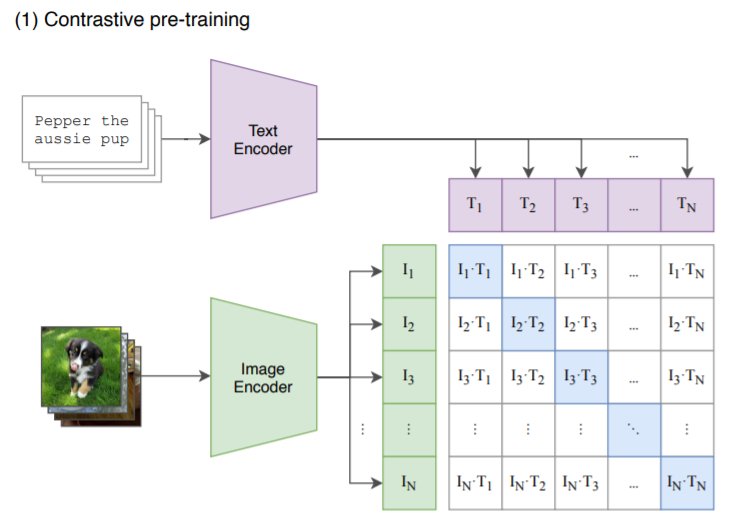
模型架构分为两部分,图像编码器和文本编码器,图像编码器可以是比如 resnet50,然后文本编码器可以是 transformer。
训练数据是网络社交媒体上搜集的图像文本对。在训练阶段,对于一个batch 的数据,首先通过文本编码器和图像编码器,得到文本和图像的特征,接着将所有的文本和图像特征分别计算内积,就能得到一个矩阵,然后从图像的角度看,行方向就是一个分类器,从文本角度看,列方向也是一个分类器。
而由于我们已经知道一个batch中的文本和图像的匹配关系,所以目标函数就是最大化同一对图像和文本特征的内积,也就是矩阵对角线上的元素,而最小化与不相关特征的内积。文章的作者从社交媒体上搜集了有大约4亿对的数据。
CLIP 测试阶段
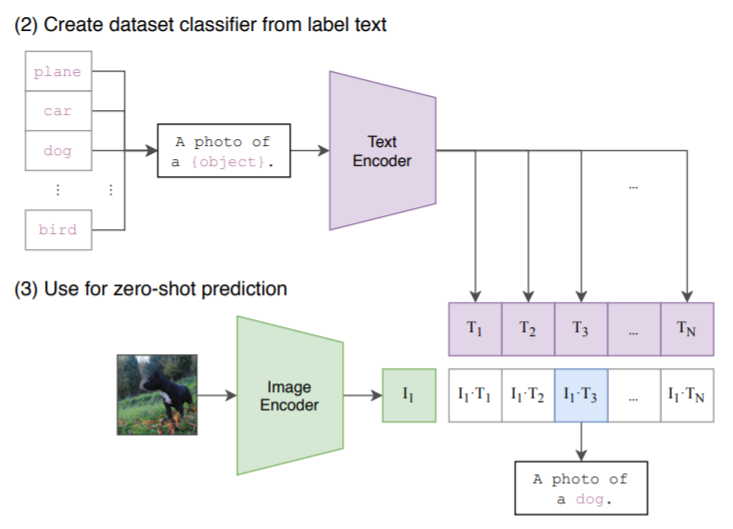
在测试阶段,可以直接将训练好的CLIP用于其他数据集而不需要finetune。和训练阶段类似,首先将需要分类的图像经过编码器得到特征,然后对于目标任务数据集的每一个标签,或者你自己定义的标签,都构造一段对应的文本,如上图中的 dog 会改造成 "A photo of a dog",以此类推。然后经过编码器得到文本和图像特征,接着将文本特征与图像特征做内积,内积最大对应的标签就是图像的分类结果。这就完成了目标任务上的 zero-shot 分类。
一些有趣的实验结果
在27个数据集上与有监督resnet50的对比
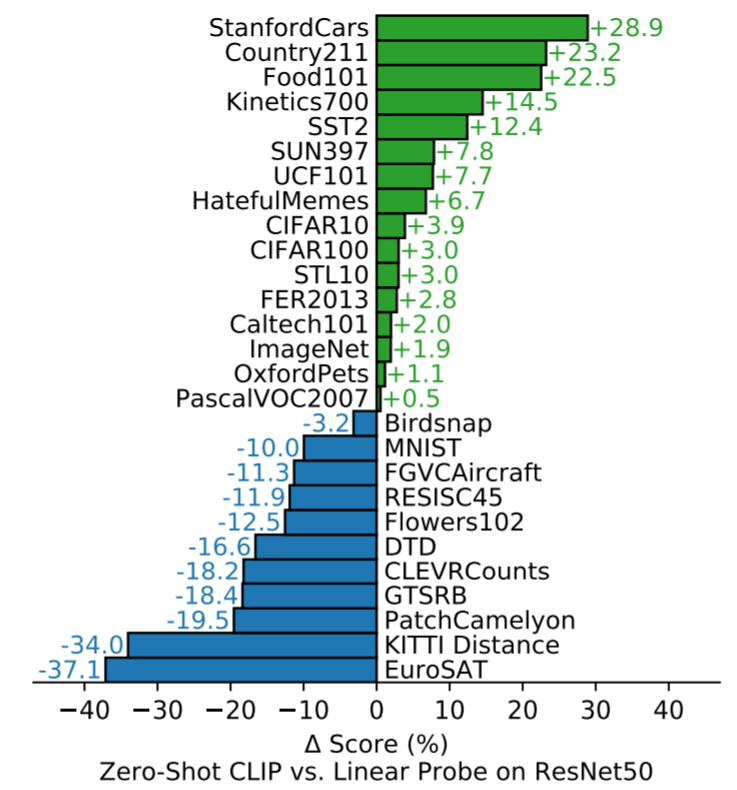
上图是在27个数据集上的对比实验结果,Linear Probe ResNet50 是指首先将 ResNet50 在 imagenet 数据集上做预训练。接着扔掉最后一层全连接并固定网络参数,重新添加一层线性分类器,然后在这27个数据集上重新训练新增的这层分类器。从实验结果上看,Zero-Shot CLIP 在其中16个数据集上都超过了 Linear Probe ResNet50,甚至包括了 imagenet。
在 ImageNet 变种数据集上与resnet101对比

这个实验是对于imagenet数据集经过重新的筛选,制作了几个变种的版本。然后将 Zero-Shot CLIP 与在 Imagenet 上有监督训练的 ResNet101 在这些数据集上的分类精度做对比。可以看到随着变种版本的难度增大,ResNet101分类精度愈来愈差,而CLIP的表现则依然很坚挺。
通过添加标签对CLIP分类效果的影响
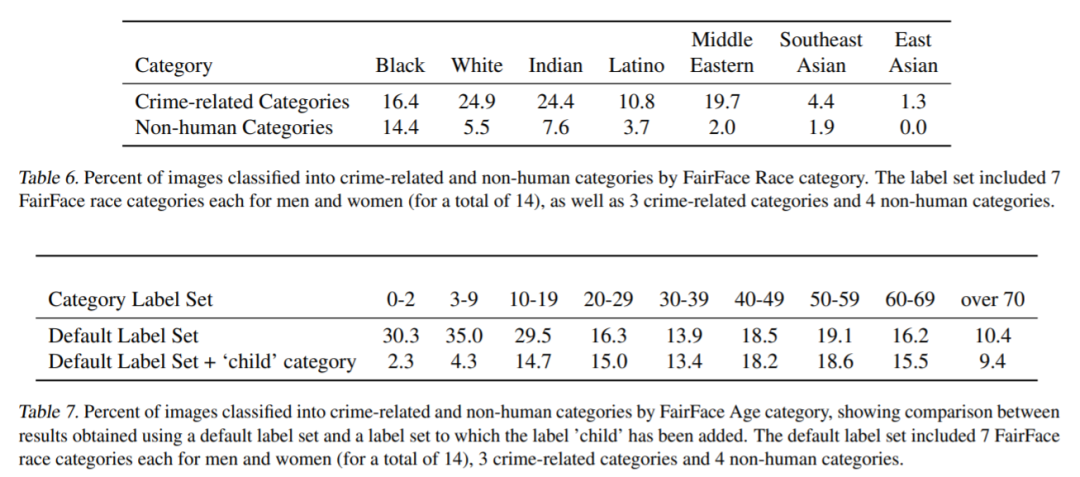
这是在一个人脸数据集上的实验结果,最上面的 Table 6 是表示数据集标签包含7个人类种族、3类罪犯相关的标签和4类非人类的标签。Table 7 才是重点,表示各个年龄段的人脸识别为罪犯或者非人类的图片比例,可以看到通过给 Default Label Set 添加一个新的 'child' 儿童这个类别,0~19岁低年龄段的人脸的误识别率都降低了很多,因为CLIP分类的时候多了个儿童这个选项。通过这个实验说明文本编码器部分的标签文本构造对CLIP分类结果的影响非常大。
总结
CLIP提供一个如何做 zero-shot 分类的思路,且模型鲁棒性强。基于 CLIP 可以自由定义自己的分类器,而且与现有的很多工作结合或许玩出很多花样,比如 DALL·E 中用到了 CLIP,又比如有人已经把 CLIP 和 stylegan 结合来生成图片,又或者可以和 GPT-3 结合等等。想了解更多详细内容可以阅读原文章或者观看视频。
原论文链接:https://arxiv.org/pdf/2103.00020.pdf