
全面解读YOLO的X版本
 点蓝色字关注“机器学习算法工程师”
点蓝色字关注“机器学习算法工程师”
设为星标,干货直达!
近期旷视团队发布了YOLOX系列模型,在同等条件下YOLOX在COCO数据集上效果要超过YOLOV5,而且代码和模型细节报告都已经发布。这里根据公布的论文以及开源的代码来解读YOLOX。
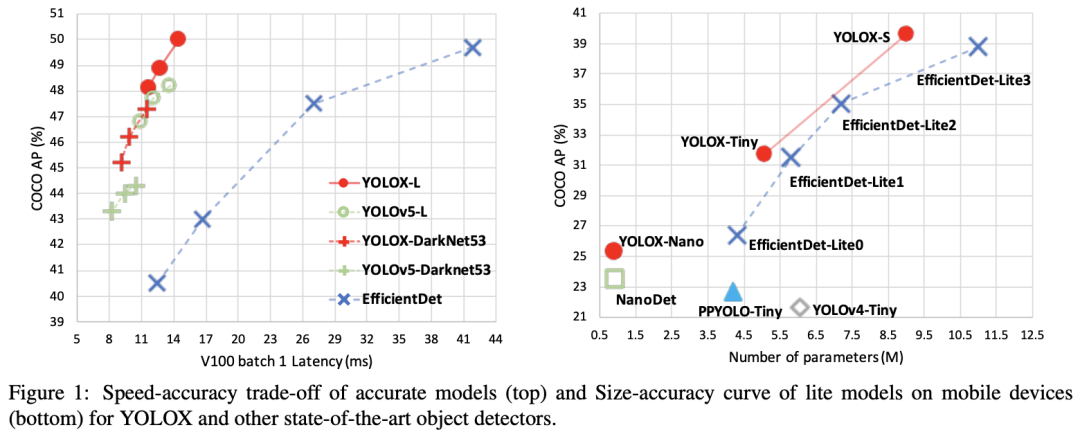
从YOLOv3开始
YOLOX选取的baseline模型为Darknet53-YOLOv3模型,并和YOLOv4和YOLOv5一样增加了 SPP layer。相比原始的YOLOv3模型,训练策略增加了EMA,学习速率采用cosine lr schedule。另外在loss上,cls和obj分支还是采用BCE,但是reg分支采用IoU loss。数据增强方面,采用RandomHorizontalFlip和ColorJitter,但没有采用RandomResizedCrop(此策略和后面要加入的mosaic augmentation重复),另外采用了multi-scale训练策略,模型的输入从448到832(只取32的整数倍数值),测试时的输入为640。模型训练采用momentum(0.9)SGD,学习速率为(线性规则),默认训练的batch size为128(8GPUs),训练的epoch为300,前5个epoch是warmup。这样得到的baseline模型在coco17val上AP为38.5,低于YOLOv3-ultralytics版本的44.3。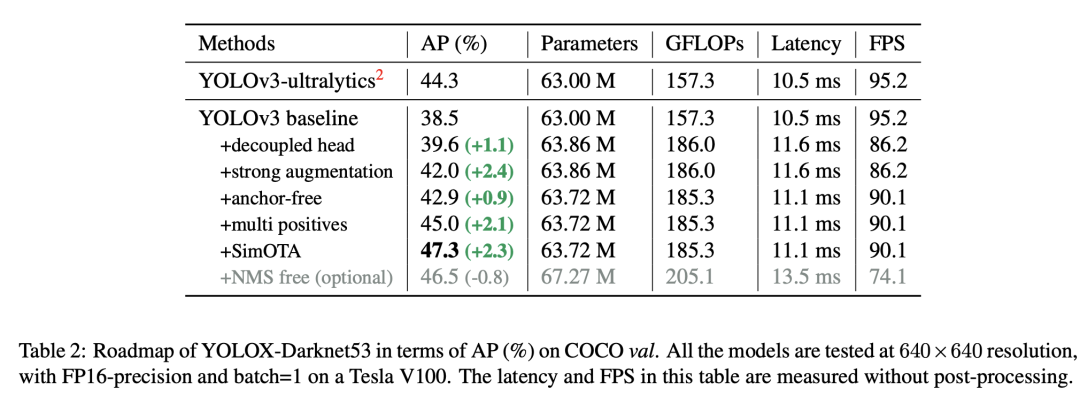
Decoupled head
YOLO模型的cls,obj和reg都是在同一个卷积层来预测,但其实其它的one-stage检测模型其实都采用decoupled head(这个其实是从RetinaNet开始的,后面的FCOS和ATSS都沿用),即将分类和回归任务分开来预测,因为这个两个任务其实是有冲突的。论文中做的第一个改进就是将YOLO改成了decoupled head,对于输入的FPN特征,首先通过1x1卷积将特征维度降低到256,然后分成两个并行的分支,每个分支包含2个3x3卷积,其中分类分支预测cls,而回归分支预测reg和obj(图中显示的是IoU分支,但实际上从代码来看和原始YOLO一样都是obj,不过按YOLO的本意其实obj里面也包含了定位准确性)。与RetinaNet不同的是,head在各个FPN特征是不共享的,这只会增加参数量,但不会影响速度,不过好在head是轻量级的。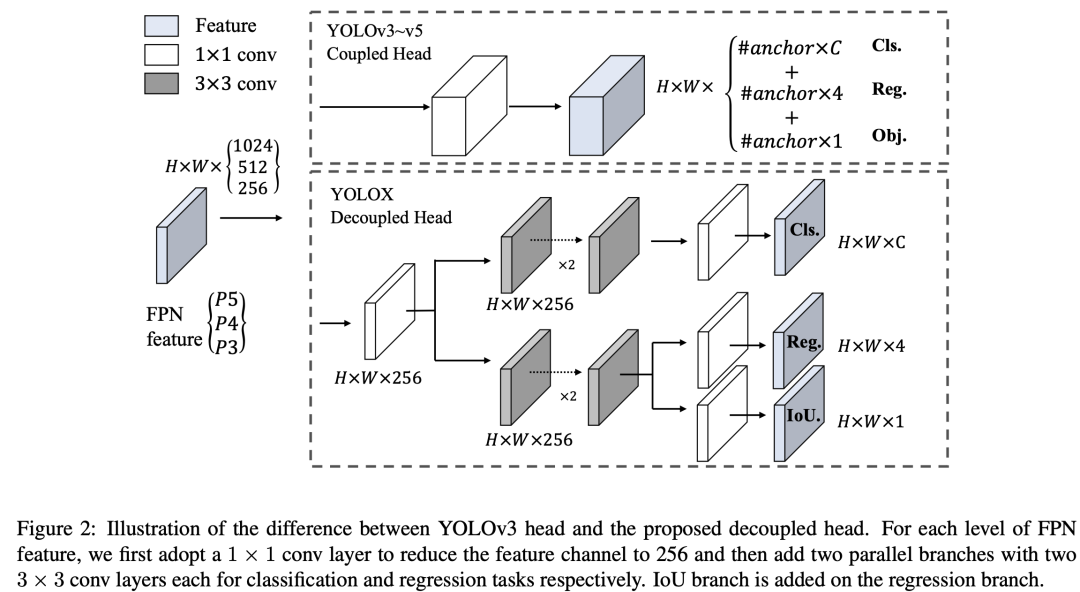 从论文的实验结果来看,改为decoupled head后,模型收敛速度更好,性能也有一定提升(+1.1)。另外论文也将YOLO改成了End-to-end YOLO版本,即参考论文Object Detection Made Simpler by Eliminating Heuristic NMS将YOLO改成one-to-one label assignment,就可以去掉后处理NMS,但是性能有下降,如果采用原始的coupled head,性能能从原来的38.5降低到34.3,而采用decoupled head仅下降0.8(猜测这个实验其实应该是中间的一个尝试,但最终由于效果放弃)。
从论文的实验结果来看,改为decoupled head后,模型收敛速度更好,性能也有一定提升(+1.1)。另外论文也将YOLO改成了End-to-end YOLO版本,即参考论文Object Detection Made Simpler by Eliminating Heuristic NMS将YOLO改成one-to-one label assignment,就可以去掉后处理NMS,但是性能有下降,如果采用原始的coupled head,性能能从原来的38.5降低到34.3,而采用decoupled head仅下降0.8(猜测这个实验其实应该是中间的一个尝试,但最终由于效果放弃)。
Strong data augmentation
这第二个改动就是采用更强的两个数据增强:Mosaic and MixUp。Mosaic是YOLOv3-ultralytics中提出的一种数据增强,这个策略也被YOLOv4和YOLOv5采用。估计是这两个数据增强太重了,在实验中的最后15个epoch会将它们关了。采用这两个数据增强提点比较明显,AP提升了2.4。此外,论文中也指出采用这两个数据增强,ImageNet上预训练模型就显得无用了,可以直接随机初始化训练。
Anchor-free
第三个改动就是将YOLO变为anchor-free,原来每个location或者grid放置3个anchor会预测3个box,那么只需要每个location只预测一个box即可,也不再设置anchor了,这里回归预测是相对location的左上点的offset以及box的width和height。对于label assignment,每个gt的中心点所在location为正样本,另外也在不同的FPN层设置scale range(和FCOS类似),所以每个gt只会分配到一个FPN层,也只有一个location来负责预测。这个改动AP提升0.9。
Multi positives
每个gt只有center location来预测,一方面正负样本不均衡,另外一些高质量的预测也会被抑制,这很可能影响模型效果。这里借鉴FCOS的center sampling策略,将gt中心所在的3x3区域均assign为正样本,此时每个gt就有multi positives,这个策略提点明显,模型AP提升至45.0,超过YOLOv3-ultralytics版本。
SimOTA
前面所述的label assignment其实还是一种简单的规则,更高级的是采用dynamic Label Assignment,比如ATSS和OTA。OTA也是旷视提出的,它将label assignment看成一个optimal transport problem(n个gt,m个anchor,每个gt匹配k个gt),通过Sinkhorn-Knopp algorithm来求解,但是会额外增加25%的训练时间。这里的改动是采用一种简化版本SimOTA:首先根据规则找到候选正样本locations,然后根据cost(gt和预测之间的分类和回归损失的加权和)来动态地为每个gt选择k个正样本。这里要注意两点:
这里的候选正样本是根据规则来选择的,具体实现采用的是每个gt所覆盖的location都在候选之列(in_box),另外在实现还考虑了center region,即将每个location是否包含在gt的center region(gt中心所在的2.5xstride区域)额外设置了一个很大的cost,其实in_box和center region并不完全重复,对于区域较大的gt,这个cost就会限制正样本在中心区域来选择; 这里的k也是动态的,并不是一个固定值,这个其实也是OTA论文中的策略,即先根据gt和pred的IoU值选择top q个pred,然后将这些pred和gt的IoU值相加取整数得到k,然后再根据cost来选择top k个pred作为正样本,这里所依赖的假设是每个gt的正样本数量应该和比较好回归gt的pred数量相关。
采用SimOTA策略,模型的AP可以提升2.3,提升也比较显著。另外论文也尝试了one-to-one label assignment(前面所述End-to-end YOLO),这个效果要比SimOTA要差0.8点,但模型是NMS-free的。
YOLOX
最后是将backbone替换成和YOLOv5一样的(修改的CSPNet),根据scaling rule就可以得到YOLOX-S, YOLOX-M,YOLOX-L和YOLOX-X四个不同size的模型,其相比YOLOv5模型效果更好(推理速度略有增加):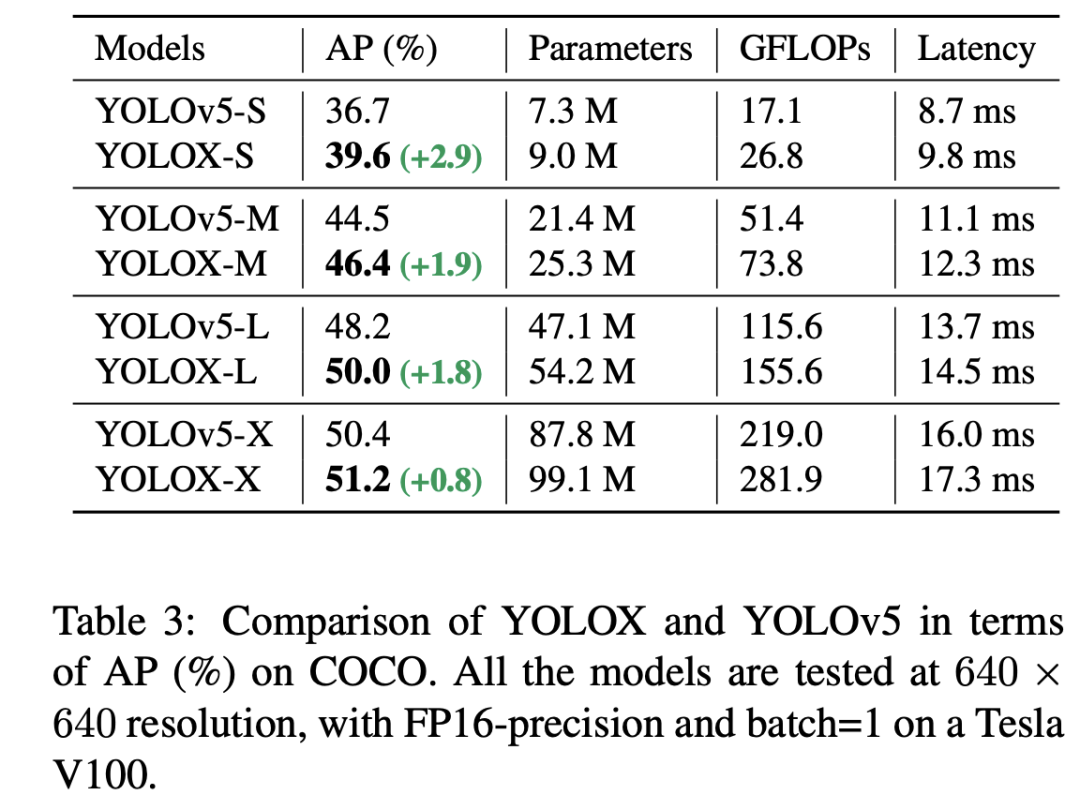
参考
YOLOX: Exceeding YOLO Series in 2021
推荐阅读
谷歌AI用30亿数据训练了一个20亿参数Vision Transformer模型,在ImageNet上达到新的SOTA!
"未来"的经典之作ViT:transformer is all you need!
PVT:可用于密集任务backbone的金字塔视觉transformer!
涨点神器FixRes:两次超越ImageNet数据集上的SOTA
不妨试试MoCo,来替换ImageNet上pretrain模型!
机器学习算法工程师
一个用心的公众号
