
OSDI 2022 Roller 论文解读
今天来阅读一下最近 OSDI 放出的微软的 Roller 这篇论文,题目为:《Roller: Fast and Efficient Tensor Compilation
for Deep Learning》
论文链接:https://www.usenix.org/conference/osdi22/presentation/zhu 代码链接:https://github.com/microsoft/nnfusion/
前段时间我分享了一下 OSDI 2021 PET: Optimizing Tensor Programs with Partially Equivalent Transformations
and Automated Corrections》 这篇论文的解读。去年也分享了 OSDI 2020 《Ansor : Generating High-Performance Tensor Programs for Deep Learning》这篇论文的解读。这两篇论文的解读可以在这个地址:https://github.com/BBuf/tvm_mlir_learn/tree/main/paper_reading 或者知乎主页找到 。Ansor 的主要贡献是做到了自动寻找高效的Schedule(循环展开、合并、分块、缓存使用、改变并行度等等),不再需要开发者在TVM中基于Tensor Expression手写Schedule模板,大大增强了算子编译器(Tensor Compiler)的易用性并且对一些典型的算子和模型效果也很不错,算是AutoTVM的升级版(因为AutoTVM还需要手动指定需要搜索的Schedule模板:https://zhuanlan.zhihu.com/p/508283737)。PET则不关心算子的Schedule,而是从部分等价变换的新角度出发去增加并行度或者改善缓存从而达到加速效果,和Roller这篇论文没什么关系,其实读不读都没关系。
最近不少人问一些tvm相关的问题,我也是业余看了下所以很多时候不能很好的解答,我建立一个讨论TVM的微信群吧,有需要的读者可以加一下互相问一问。请加微信 bbuf23333 入群,备注一下tvm吧。另外业余接触编译器这一年整理的这个知识仓库已经有500+ star了,谢谢大家。希望能得到更多关注。
https://github.com/BBuf/tvm_mlir_learn
无论是Ansor,AutoTVM还是PET(一部分代码生成也是基于TVM AutoTVM/Ansor的)它们都面临了同样一个问题,那就是在对算子的Schedule进行搜索时需要耗费大量的时间,在特定硬件上对一个常见的视觉模型进行自动调优和生成代码kennel需要数小时。这严重阻碍了AI编译器应用于模型部署。基于这个痛点,Roller横空出世。
0x0. 标题&作者&摘要
 ROLLER:一个用于深度学习的快速高效的张量编译器。作者来自微软亚洲研究院以及多伦多大学等多所高校。
ROLLER:一个用于深度学习的快速高效的张量编译器。作者来自微软亚洲研究院以及多伦多大学等多所高校。
现代的张量编译器虽然取得了很多的进展,但通常这些编译器都需要小时计的时间去搜索和生成高效的Kernel,这是因为现有张量编译器通常指定的搜索空间很大。为了解决编译时间长的问题,本文提出了Roller,它的核心是rTile,这是一种新的Tile抽象,它封装了和底层加速器的关键特性一致的张量shape,从而通过限制shape的选择实现高效的运行。Roller采用了基于rTile的递归构建算法来生成目标程序(rProgram)。最终,Roller可以在几秒内就生产高效的Kernel,性能可以媲美目前主流加速器上的其它张量编译器,并且为IPU等新的加速器生产更好的Kernel。
还不能看出什么,继续往下看吧。这里说的tile就是对输入进行分块以适应硬件的内存结构,我在之前的文章有详细讲到,不了解的同学可以先看一眼tile这部分的科普:https://zhuanlan.zhihu.com/p/508283737 。
0x1. 介绍
深度神经网络越来越重要,深度学习编译器在硬件上生成高效的Kernel也越来越重要,并且取得了很多成功。但是当代的编译器在生成高效的Kernel时往往需要搜索数个小时甚至数天,因为它们都是把这些网络中的算子实现成多重循环嵌套。张量编译器通常需要对已实现的多重循环计算进行循环展开、合并、分块、缓存使用、改变并行度等调整以适应硬件的内存结构(比如CPU的三级Cache和CUDA的global memory,l2 cache, l1 cache结构)或者硬件特性(比如向量化,并行化)。这里涉及到非常大和复杂的搜索空间,所以搜索时间会很久。这篇文章提出的Roller解决了搜索时间长的问题,它有如下几个特点。
首先,Roller不把DNN中的算子计算视为多层嵌套循环,而是视作数据处理管道,其中数据块(tile) 在具有并行执行单元(如GPU SM)和内存层次结构抽象的硬件上移动和处理。生成高效的Kernel的目标变成了提高流水线吞吐量的目标。
Roller将算子的计算过程建模为基于数据块(tile)的流水线,即将不同大小的数据块从多级内存结构中搬运到处理器如SM计算并逐级写回。
然后,为了使得基于数据块的流水线吞吐量最大化,要求每一级的数据块(Tile)shape都必须匹配(论文中叫对齐)硬件的参数设置,比如memory bank, memory transaction length, 和 minimum schedulable unit (e.g., warp size in GPUs)这些和内存带宽以及并行度相关的设置。这个约束不仅可以使得张量程序在每一级内存中都拥有很好的计算效率,这还大大降低了以前以多重循环为基础的参数搜索空间,从而解决张量编译器在编译时因为搜索Schedule耗费的大量时间。 最后,对齐硬件的数据处理管道的性能是高度可预测的。因为内存吞吐量可以从硬件规范或者Benchmark测试得出,这大大简化了对不同硬件进行对齐后做性能估计的难度,并不再需要基于硬件去构建复杂的代价模型来估计性能。
基于这些想法,Roller提出了rTile,这是一种新的抽象,它封装了和硬件加速器的关键特征和输入张量shape一致的数据块(Tile)shape(后面会详细看)。然后将数据处理管道描述为基于rTile的程序(rProgram),由Load, Store, Compute 三个接口组成,作用于rTile。为了构建高效的rProgram,Roller遵循了一个scale-up-then-scale-out的方法。它首先执行Scale-up的过程,该过程采用基于rTile的递归构造方法(Figure8)逐渐增加rTile shape大小,来构造一个饱和加速器单个执行单元(如SM)的rProgram。然后执行Scale-out的过程,由于深度学习的计算模式和加速器的并行执行单元的同质性,它只是将生成的rProgram复制到其它并行执行单元。这里的scale-up-then-scale-out可以叫做纵扩和横扩。
Roller可以在没有显著开销的情况下评估不同rTiles的性能。每种算子可以简单的测试一下峰值和带宽。由于对齐了硬件结构,其它关键的性能因素比如rTile的内存压力可以从硬件规则分析得到。这样就得到了一个高效的微评测模型,避免了其它编译器所需的对每个配置进行昂贵的在线分析,从而显著加速了编译过程。此外,由于严格的对齐要求,递归构造过程可以快速生产一些想要的rTiles和rPrograms。综合一下,Roller可以在几秒内生成高效的Kernel。
作者团队在TVM和Rammer(Rammer可以看:https://www.msra.cn/zh-cn/news/features/osdi-2020-rammer)之上实现了Roller并开源了代码。大量的实验表明Roller可以在几秒内生产高度优化的Kernel,特别是对于大型自定义的高成本算子。这在编译时间上实现了3个数量级的改进。Roller生成的Kernel可以和最先进的张量编译器乃至硬件厂商提供的加速库相媲美,并且通常性更好(指接入新的硬件)。使用三个 rTile-based 的接口(Load, Store, Compute)描述一个程序,Roller可以轻松适应不同的加速器如AMD GPU和Graphcore IPU。
0x2. 动机和关键观察
Excessive compilation time:张量编译器编译时间太长,影响生产。 Observation and insights:我们观察到对于深度学习算子的计算有不同的视角。以矩阵乘法为例子来说明我们的观察。和将MatMul视为跨三重循环的现有编译器不同,算子的计算过程也是一个数据处理管道。我们可以从A和B Load 2个子矩阵(tile),Compute 两个子矩阵,Store 结果到C的内存中。所以计算的性能取决于 Load-Compute-Store 管道移动一个 Tile 有多快。
影响流水线中所有步骤关键性能的因素是Tile shape和一维内存空间中的布局。Figure1(a)说明C中一个元素的计算和内存访问的模式。假设所有矩阵存储在行优先的布局中,从B加载列会有1个跨步访问。假设这里的事务内存长度(the memory transaction length)是4,那么就有3/4的冗余数据读取。所以数据块的形状应该和内存事务长度对齐,以实现高效的内存访问。在Figure1(b)中,当以1x4 Tile的粒度计算B时不会有内存带宽浪费。除了内存对齐之外,数据的Tile shape还应该和硬件执行单元如并行线程数对齐以避免浪费计算周期。此外,由于Cache的存在,Tile shape也会影响数据重用机会。例如Figure1(a)每次计算1x1 tile时需要读取2mnk个数据。然而在Figure1(b)中只需要1.25mnk次读取,因为来自A的一次数据读取可以重复使用4次。如果沿M维度的tile 大小设置为4x4,总的reads可以减少到0.5mnk,总的数据读取效率比Figure1(a)提高了10倍。

0x3. 系统设计
下面的Figure2描述了Roller的系统设计。Roller的输入是使用TE表达式。该表达式由用户生产或者从其它编译器生成(这一步可能会发生一些融合操作)。Roller从TE中提取张量形状并基于硬件规范来构建rTiles,即对齐硬件的构建块。基于rTiles,Roller提出了一种横扩纵扩递归构造算法,用于生成描述数据处理管道的高效张量化程序(rProgram)。在生成rProgram时,构建算法通过微观性能模型评估构建的rProgram的性能,从而识别出良好的rTile配置。它建立在通过硬件抽象描述的设备上,仅公开和rTiles相关的接口:Load/Save/Compute。构建的rProgram最终通过Codegen生成特定设备的最终Kernel。
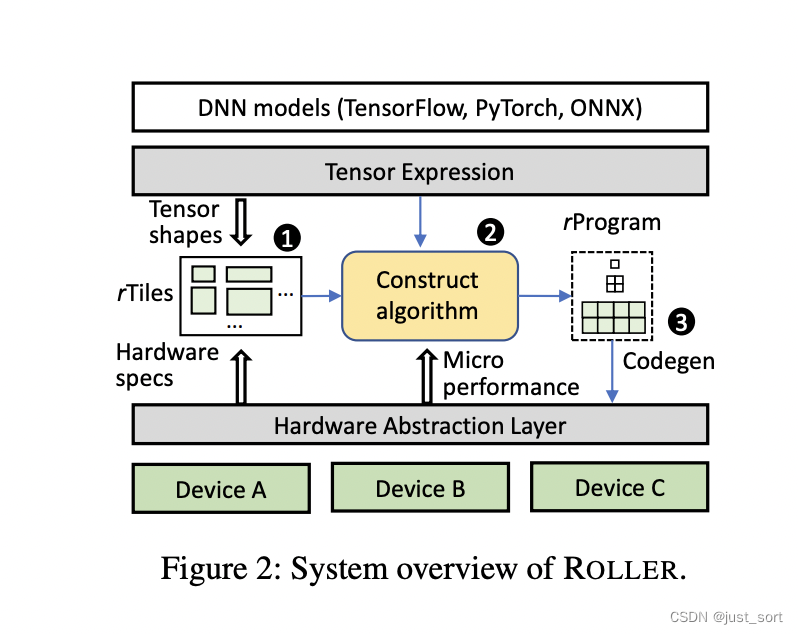
0x3.1 Tensor Expression and rTile
Roller将TVM中引入的Tensor Expression引入作为编译器的输入,Tensor Experssion这里不讲了,如果不了解可以看一下TVM里面chen tianqi写的文档。https://tvm.apache.org/docs/tutorial/tensor_expr_get_started.html
Roller引入rTile作为基本计算单元来组成张量计算。如Figure3所示,rTile封装了沿给定张量表达式的expr的每个循环轴定义的多维tile shape。给定shape和expr,rTile可以静态推断所涉及的输入和输出数据块。例如,沿轴i, j, k的tile shape表示上述Matmul表达式的rTile,其中每个rTile加载来自A的4x2个数据以及来自B的2x4个数据,进行总共4x2x4 次 mul-add计算,并将4x4的数据tile写回到C,如Figure4所示。


rTile的一个独特属性在于它必须和给定张量表达式中的底层硬件特征和输入Tensor shape保持一致。所有这些对齐方式都由Figure3里rTile 的 shape 和 storage_padding 来控制,它们分别代表 rTile 的逻辑形式和物理布局。接下来,详细阐述对齐的详细要求:
Alignment with the hardware execution unit 。首先,rTile的shape必须和它运行的执行单元的并行度对齐。例如,在GPU上运行 rTile 的shape 大小必须是 wrap size的倍数比如 32 来达到最大的计算效率。当在NVIDIA GPU中使用TensorCore时,rTile shape大小应该是 16x16x16 的倍数。 Alignment with memory transaction 。其次,数据块(Tile)的 shape 应该和内存事务的长度保持一致,以实现最佳内存访问。具体来说,对于rTile的每个数据块我们都应该保证它的Leading dimension(如行优先Tensor中的最内层维度)是内存事务长度的倍数。如Figure5(a)所示,在Roller中,张量内存以缓存对齐的方式分配。因此,rTile可以避免浪费任何的内存读取,因为它的 shape 是和内存事务长度对齐的。
最大程度的利用全局内存带宽,提高全局内存加载效率是优化Kernel的基本条件,非对齐的内存会造成带宽浪费,可参考:https://face2ai.com/CUDA-F-4-3-%E5%86%85%E5%AD%98%E8%AE%BF%E9%97%AE%E6%A8%A1%E5%BC%8F/
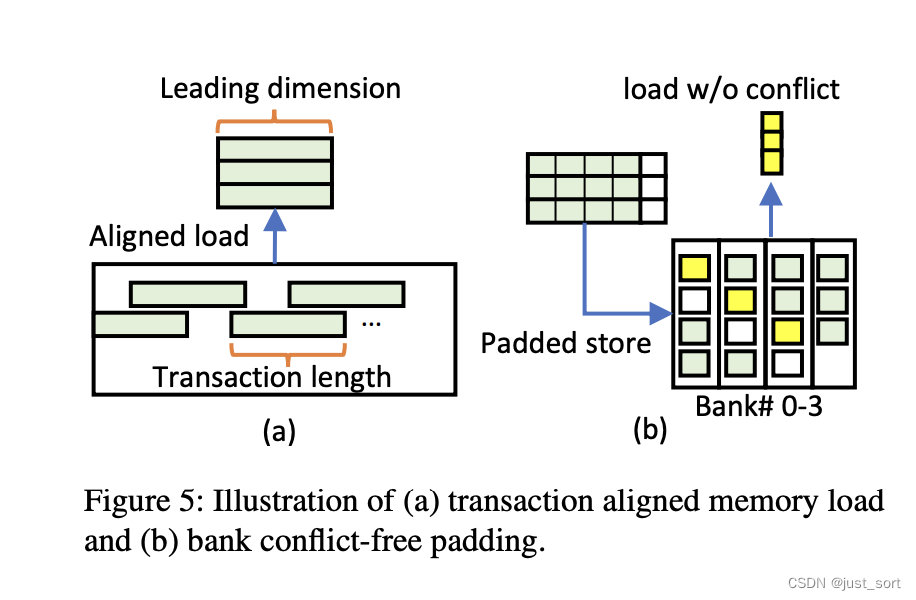
Alignment with memory bank. 第三,数据块的内存布局应该和Memory Bank对齐,以避免读取冲突。例如,在Figure5(b)中数据块a(shape为[3, 4] )跨4个bank保存在内存中,并由形状为 [3, 1] 的块读取。将这个形状为[3, 1]的小块中的数据存储在一个bank的naive方法将导致加载冲突。rTile通过padding来避免这种低效。给定一个Leading dimension为N的数据块,由另外一个Leading dimension为n的块读取,我们延N维度做一个padding_size大小的padding。
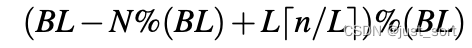
其中B和L分别是bank数量和bank的宽度。每一个维度的padding大小被计算出来后存到Figure3中的storage_padding字段。对于Figur5(b),通过padding_size为1的填充,所有的值 [3x1] 分布在不同的bank中,可以高效读取。
GPU Shared Memory bank conflict: https://blog.csdn.net/Bruce_0712/article/details/65447608
Alignment with tensor shape 最后,rTile的shape应该和输入张量表达式的张量shape对齐。否则,计算不能被rTile均匀且分,浪费计算资源或者产生大量的边界检查开销。一个简单的解决方案是沿着Tensor的维度(大小为 )进行padding,padding的大小为,使得 时rTile shape在维度i大小的倍数。但是较大的padding kennel会浪费计算,所以Roller将张量padding限制在内,并且需要满足以下公式:。这确保了计算的浪费百分比以 ε 为上界。有了这个限制,我们可以枚举所有满足这个条件的有效 rTile 形状。
Deriving allrTiles. 鉴于上述对齐要求,对于特定的张量表达式和硬件设备,Roller 使用以下接口增量导出所有符合条件的 rTiles:
vector<int> GetNextAlignedAxisSize(rTile T, Dev d),
在给定设备指定参数后,它返回rTile shape里每个维度的下一个对齐大小。这是通过在每个维度逐渐增加尺寸大小直到满足所有对齐要求来计算的。rTile抽象允许Roller被扩展以支持新的对齐要求,这是通过GetNextAlignedAxisSize接口来实现的。
Calculating data reuse score rTile一个有趣的特性是我们可以通过调整它的shape来隐式的控制内存流量。增加rTile 大小通常会以占用更多内存为代价为程序带来更多的数据重用机会。给定一个rTile T和在每一个轴上的下一个对齐大小,我们可以通过
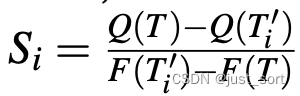
计算出轴的数据重用分数 ,其中 是通过用GetNextAlignedAxisSize得到的下一个对齐大小替换轴处维度大小获得的一个更大的rTile。函数Q(T)和F(T)计算以T的粒度执行计算时的内存流量和内存占用,这可以根据给定张量表达式和硬件内存规范直接推断(0x3.3节内容)。更大的意味着在使用相同的内存时可以节省更多的内存流量。内存重用分数在构建高效的 rProgram(使用 rTiles)中起着至关重要的作用。
0x3.2 Tensor Program Construction
rTile program。给定 rTile 和现代加速器的内存分层结构,张量计算可以自然地被看成数据流处理管道。计算从最低的内存级别加载数据块(在rTile中指定),在加速器的执行单元上对rTile进行计算,并将结果数据块写回最低的内存级别。对于每个内存级别,定义了一个特定的rTile和该内存级别的特性保持一致。 因此,Roller将张量计算描述为具有分层 rTile 配置的数据处理管道,成为rProgram。
Figure6展示了具有三个存储层(L0,L1,L2)的设备上的rProgram。rProgram由每个 内存层次 的 rTile 和 rTile 指令(Load, Store, Compute) 来描述。

Figure7(a)展示了Figure7(b)对应的MatMul程序。Figure7(c)说明了rProgram如何映射到设备的每个内存层次。具体来说,每次它从内存L2中加载一个A的4x4小块和B的4x8小块到L1中。然后从L1中加载一个A的2x1和B的1x2小块到L0(寄存器)中。每次计算完成后,结果的2x2小块会直接从L0写回到L2。
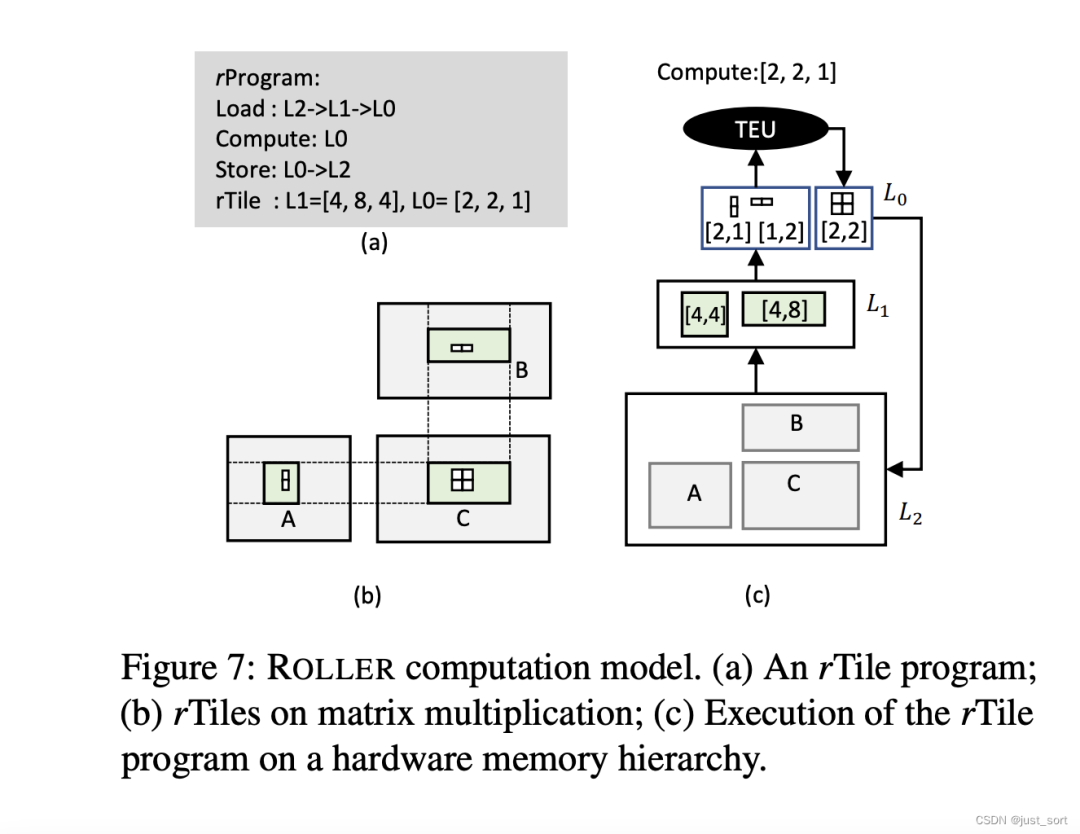
给定一个数据处理流水线,对应的rProgram的优化目标就是最大化流水线的吞吐量。这个目标可以转化为满足三个条件:1)计算和内存移动应该充分利用硬件的特性。2)吞吐量应该达到瓶颈阶段(接近峰值)。3)需要有足够的并行度来利用所有的并行执行单元。因此,Roller提出以下rProgram的构建策略:首先通过构建单核 rProgram在一个内核上纵向扩展,使得Kernel的硬件利用率饱和。然后通过复制构建的单Kernel横扩以利用硬件的并行度。
Scaling up an rProgram 。由于rTile的对齐属性确保了硬件的效率,Roller可以只专注于通过构建正确的rTile shape来最大化每个内存层次的吞吐量。通过利用0x3.1节中定义的数据重用分数,单核rProgram构建算法从初始化rTile开始,并逐渐将其扩大到rTile中收益最大的轴(也即具有最大重用分数的)。注意,构造算法不需要精确的数据重用分数,它只是选择最大的一个来最大化吞吐量。在此过程中,内存的性能会提高直到达到计算峰值或者最大的内存容量。上述过程从上到下对每个内存层次进行重复,直到构建出所需的rProgram。请注意,如果某些张量表达式的数据重用分数保持不变,比如elemetwise算子,Roller将只为顶层构建rTiles并从底层内存内存加载它们。
Figure8展示了详细的构建算法。给定一个张量表达式expr和目标设备dev,该算法在顶层内存构造一个初始化的rTile T并递归的放大T(对应第4行的EnlargeTile)。每一步,它都会枚举下一个更大的rTile T‘,最大程度的提高数据重用得分(对应第10行的GetNextRTileShapes)。如果T'达到内存容量(第13行)或者数据块加载的吞吐量MemRef(T')超过了峰值计算吞吐量 MaxComputePer f(T')(第17行),算法记录当前的rTile并在下一个内存级别继续EnlargeTile。否则,它会在当前内存层级继续扩大T'(第20行)。构建在最低的内存层级完成(第6行),产生一个结果并重复运行直到产生K个rPrograms(来容忍编译器的隐藏因素影响),注意,这里的MemPer f(T′)和MaxComputePer f(T′)是基于dev和0x3.3节的微性能模型推导出来的。
Scaling out an rProgram。鉴于大多数DNN算子的计算模式和加速器中的并行执行单元的同质性,Roller 通过将计算统一划分为大小等于最低内存层级 rTile 的 rTiles,简单地将在一个执行单元上构建的 rProgram 复制到其他单元。我们通过将所有rTiles平均分配到所有执行单元来实现这一点。注意,Roller更喜欢将reduce轴分配到同一执行单元上,因为它们可以在更高的内存层级中共享recue的结果。请注意,Roller并不假设会独占所有的计算单元,系统可以在横向扩展时显示地控制rProgram的并行度。 Small operator and irregular tensor shape 。横向扩展算法天然有利于有足够并行度的算子。例如,分区数明显大于执行单元数的。对于小算子,算法的整体性能kennel会受到并行执行单元利用率低的影响。这里可以通过Rammer编译器的同时调度一些小Kernel来解决。然后另外一种方法是对于每个rProgram,Roller尝试沿着具有最小数据重用分数的轴收缩rTiles,来实现足够的并行度。请注意,和其它对齐规则一样,此枚举过程每次都会返回下一个对齐的Tile大小,这是一个高效的过程,和整个构建过程相比产生的成本可以忽略。
另外大算子可能包含不规则的尺寸较小的张量维度,而Roller由于对齐要求kennel无法生成足够数量的rProgram。为了解决这个问题,Roller通过轴融合pass将张量表达式转换为规范的形式。具体来说,对于所有设计的张量,如果在一个张量中存在两个相邻的轴,这些轴在所有的其它张量中既存在又相邻,或者都缺失,Roller就可以安全的合并这两个轴。如,一个输入和输出张量形状都是[17, 11, 3]的张量,Roller会把这三个维度fuse起来变成。除了轴融合外,Roller还尝试在张量填充机制中贪心的增加参数,直到kProgram构建完成。
0x3.3 Efficient Evaluation of an rProgram
在构建算法中,Roller需要评估rProgram的性能。Roller无需评估真实硬件设备中端到端的rProgram,只需要评估 rTile 的性能,如Figure8中的MemPerf和MaxComputePerf。
为此,Roller针对硬件抽象层(HAL)中描述的设备构建了一个微观模型。HAL将加速器建模为具有分层内存的多个并行执行单元,HAL公开了三个基于rTile的接口:Load,Save,Compute。执行单元被抽象为rTile Execution Unit(TEU),它通过Compute接口对数据块进行计算。可以将多个TEUs组织为一个组,它们可以协同加载和存储Tiles。HAL将不同的内存层(如寄存器,共享内存,DRAM)视为一种统一类型,暴露了影响Tile性能的硬件规范。硬件规范包括内存容量,事务长度,缓存行大小,Memory Banks数量,可以通过Figure9的getDeviceSpec获取。

Micro performance model 。借助硬件抽象层,Roller可以轻松推导出rTile(和rProgram)的性能。首先,给定一个rTile,可以从rTile的张量表达式expr和shape(Figure9中的MemFootprint 和 MemTraffic 接口)静态推断出产生的内存占用(包括padding)和跨不同层的内存流量。计算数据重用分数并检查rTile是否已经超出内存容量。其次,为了计算rTile的MaxComputePerf,Roller通过积极扩大Tiles shape使得TEU饱和,进行一次性分析以测量峰值计算吞吐量。此性能数据缓存在Roller中,供将来在构造算法中查询。最后,对于给定的rTile,Roller还估计MemPerf,即从内存低层加载到更高层的性能。给定rTile中对齐的内存访问,加载常规Tile的延迟可以简单地通过将总流量处于内存带宽来建模。对于所有TEU共享的内存层,我们平均分配带宽。对于较小的访问内存,Roller对每种设备类型进行一次离线分析并缓存结果。值得注意的是,微观性能模型只需要在Tile shape完全对齐的情况下准备,这是Roller的关键要求。
4. 实现细节
代码生成:给定固定的代码结构(如Figure6中的一个rProgram),Roller基于预定义的模板生成代码(TVM 内置调度原语)。在每个内存层级加载和存储数据块由 TVM 的 cache_read 和 cache_write 原语实现。rTile 上的分区是通过 split 和 fuse 完成的。一些rTile计算的原语是通过TVM内置API完成的。基于模板,给定的rProgram可以直接生成cuda代码。 Tensor Padding:Roller依靠张量padding将rTiles和张量shape对齐。在实践中,最底层内存(例如 DRAM)中的大多数张量是由外部程序(例如 DNN 框架)分配的,因此我们只需在上层内存(例如共享内存)中应用padding。Roller的张量padding目前需要输入张量表达式来指定它是否允许填充,以及默认的填充值(例如,0 表示 MatMul 运算符)。对于 Memory Bank 对齐的storage padding,我们利用 TVM 的 storage_align 原语添加padding。 Performance profiling。Roller实现了两个性能分析器。一个微观性能分析器和一个内核分析器。前者通过micro-benchmark生成内存带宽,计算吞吐量等硬件指标。这是针对每种设备类型和张量表达式的一次离线分析。后者描述了top K个kPrograms中最快的kernel,如果k大于1则用于每一个编译结果。在实际应用中,特定内核代码的性能也会受到设备编译器和硬件相关隐藏因素的轻微影响,Roller 几乎无法控制。这些因素包括不同指令类型的指令密度、寄存器分配行为、设备编译器优化、warp 调度开销等。特别是在 NVIDIA GPU 上,Roller 依靠 nvcc 将生成的 CUDA 代码编译成机器代码。但是,nvcc 的专有优化可能会对程序执行行为产生不利影响。因此,Roller 利用内核分析器快速评估性能最佳的 rProgram 并选择最佳的。较大的 K 通常可以提高kernel质量。在评估前 10、20 和 50 个结果后,我们的经验表明,前 10 名可以获得大多数情况下的最佳结果。请注意,Roller 的内核分析器不同于以前编译器中由机器学习算法驱动的评估过程 。基于 ML 的方法通常需要数百甚至数千个顺序评估步骤,而 ROLLER 仅并行分析数十个候选者。未来,我们计划实现汇编级代码生成,以缓解高级设备编译器中的隐藏问题。
还有一些NIVIDIA GPU/AMD ROCm/Grphcore IPUs具体硬件上的一些实现细节,感兴趣的可以自己看下论文。
5. 评测
这里主要看一下在cuda上的结果。
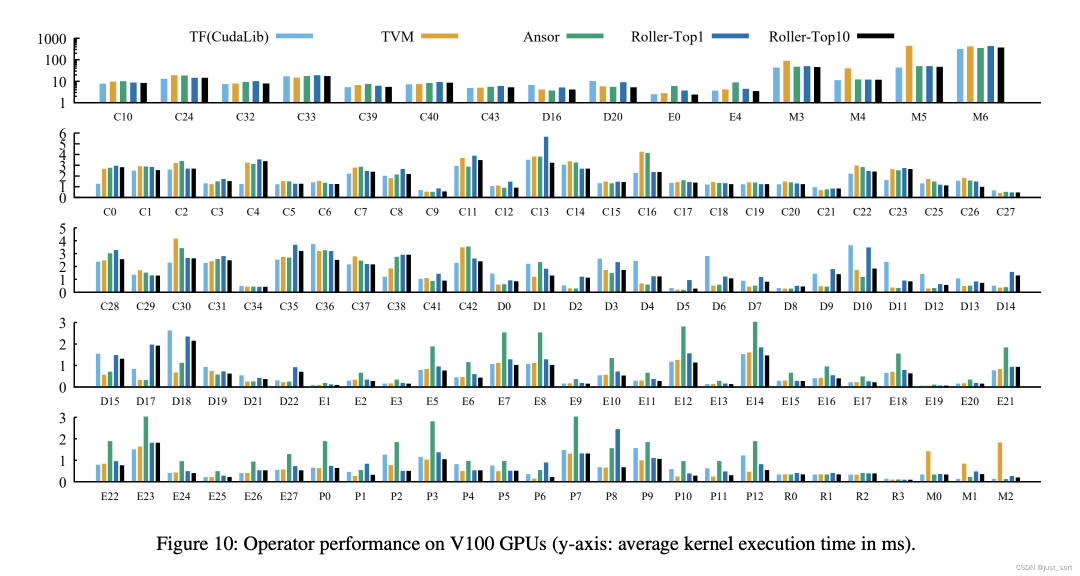
Figure 10 绘制了我们基准测试中 119 个算子的平均kernel性能,按算子类型和 ID 排序。我们将大型算子(例如,kernel时间大于 5ms)绘制在 y 轴为对数尺度的顶部子图中,而底部 4 个子图是其它中小型算子。首先,与 CUDA 库 (CudaLib) 相比,Roller 可以为 81.5% 占比的算子获得可比的性能(即在 10% 以内),并且对于 59.7% 的算子来说甚至更快。我们观察到,Roller 表现较差的大多数算子是具有 3×3 或更大滤波器的卷积算子,它们通常在 cuDNN 中使用更有效的数值算法(例如,Winograd [23])来实现,并且难以用张量表示表达。这就是在这些情况下 Ansor 和 TVM 也比 CudaLib 慢的原因。其次,与 TVM 和 Ansor 相比,Roller 也可以分别为 72.3% 和 80.7% 占比的算子获得可比的性能。其余的 27.7% 和 19.3% 主要是小算子或张量形状不规则,难以与硬件对齐。然而,这些算子的kernel执行时间通常相对较短,例如平均只有 1.65 毫秒和 1.16 毫秒。在所有算子的 54.6% 和 65.5% 占比中,Roller 甚至可以分别比 TVM 和 Ansor 生成更快的kernel。我们观察到这些算子中的大多数都是大型且耗时的。正如上面的子图所示,当算子大于 5 毫秒(最高 343 毫秒)时,Roller 可以为这些算子中的大多数实现更好的性能,例如,与 TVM 和 Ansor 相比,平均速度提高了 1.85 倍和 1.27 倍。
下面的Figure11还比较了算子编译的平均时间:
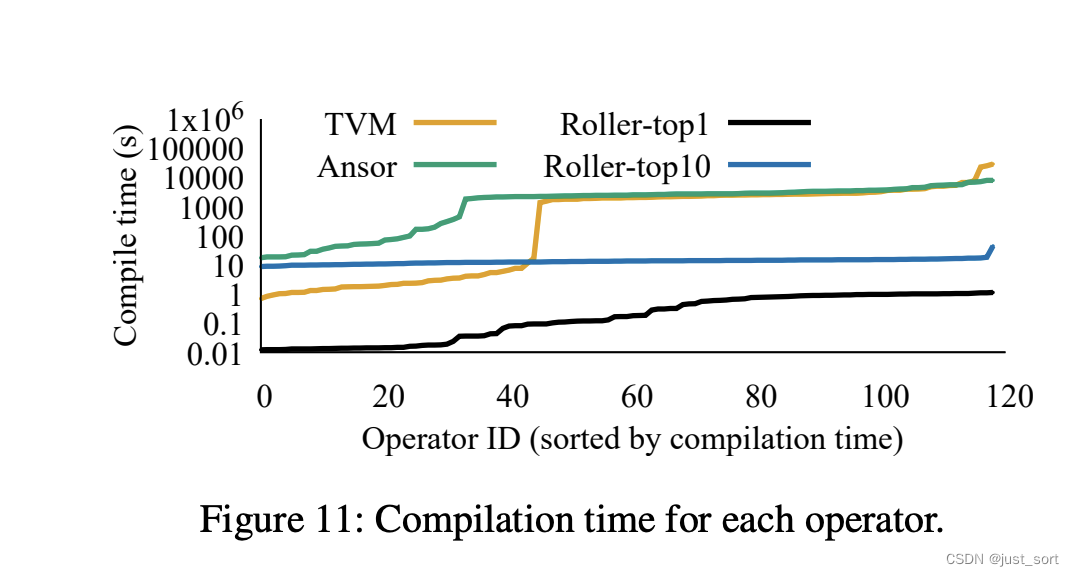 可以看到相比于TVM和Ansor,Roller的算子编译时间在数秒内,比TVM和Ansor的搜索时间快了2个数量级。
可以看到相比于TVM和Ansor,Roller的算子编译时间在数秒内,比TVM和Ansor的搜索时间快了2个数量级。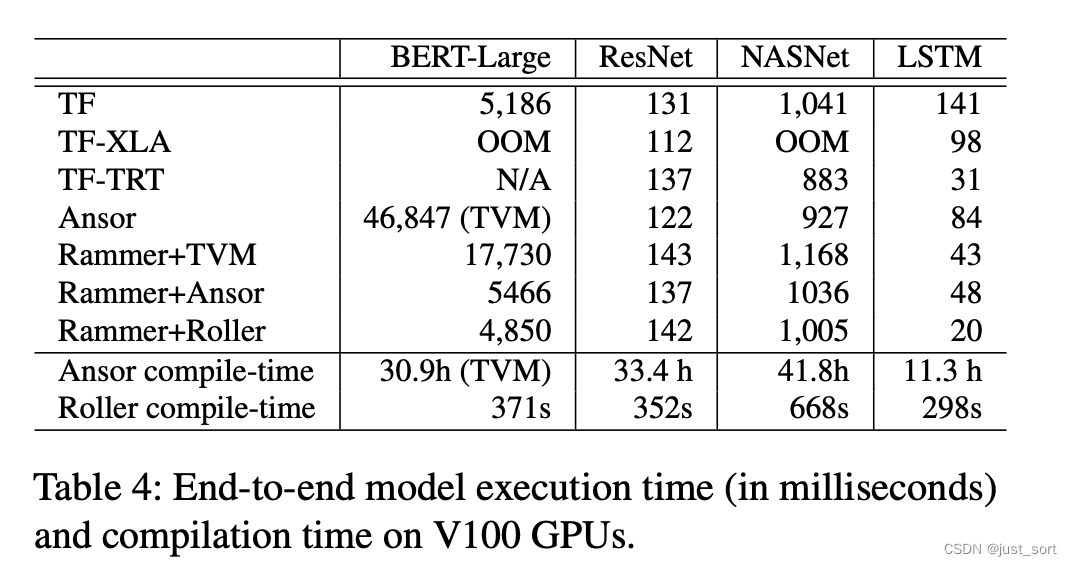
这里的Table展示了几个经典的神经网络的性能和编译时间,可以发现Rooller相比于TVM和Ansor可以获得相当的性能,但可以将编译时间从几十个小时缩短到几百秒钟,可以大大提高模型的实际生产周期。
6. 结论&评价
为了解决编译时间长的问题,这篇论文提出了Roller,它的核心是rTile,这是一种新的tile抽象,它封装了和底层加速器的关键特性一致的张量shape,从而通过限制shape的选择实现高效的运行。Roller采用了基于rTile的递归构建算法来生成目标程序(rProgram)。最终,Roller可以在几秒内就生产高效的Kernel,性能可以超越目前主流加速器上的其它张量编译器,并且为IPU等新的加速器生产更好的Kernel。