基于深度学习的单目深度估计综述

极市导读
本文是一篇关于单目深度估计方法的综述文章,总结了基于深度学习的深度估计中被广泛使用的数据集、评价指标和重要的训练方法,并对该领域的未来提出展望。>>加入极市CV技术交流群,走在计算机视觉的最前沿
论文摘要
相关工作与介绍
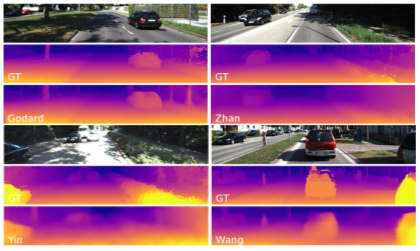
深度估计中的数据集和评价指标
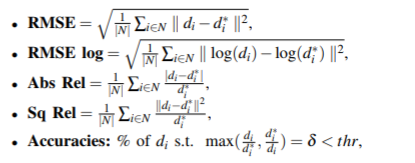
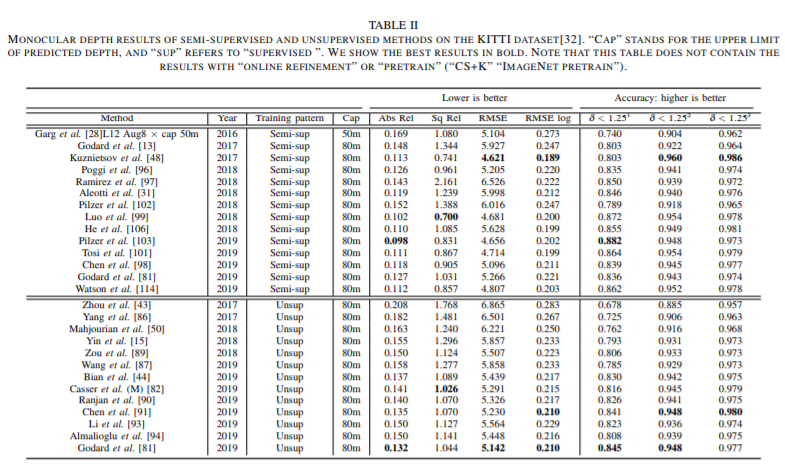
基于深度学习的单目深度估计
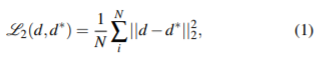
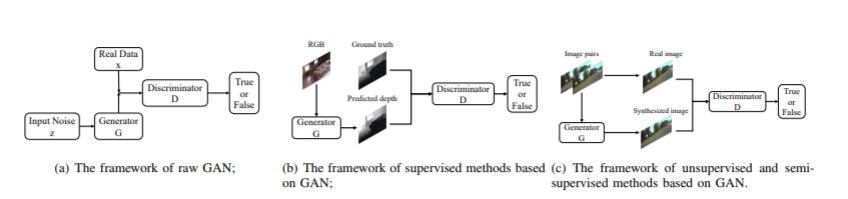
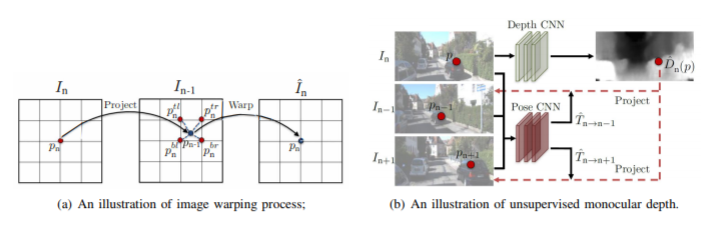
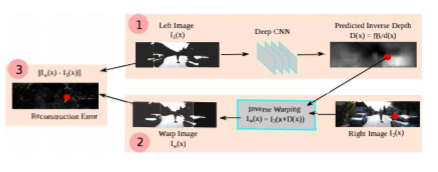
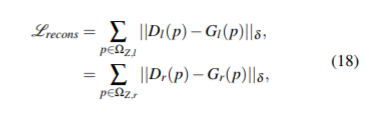
讨论
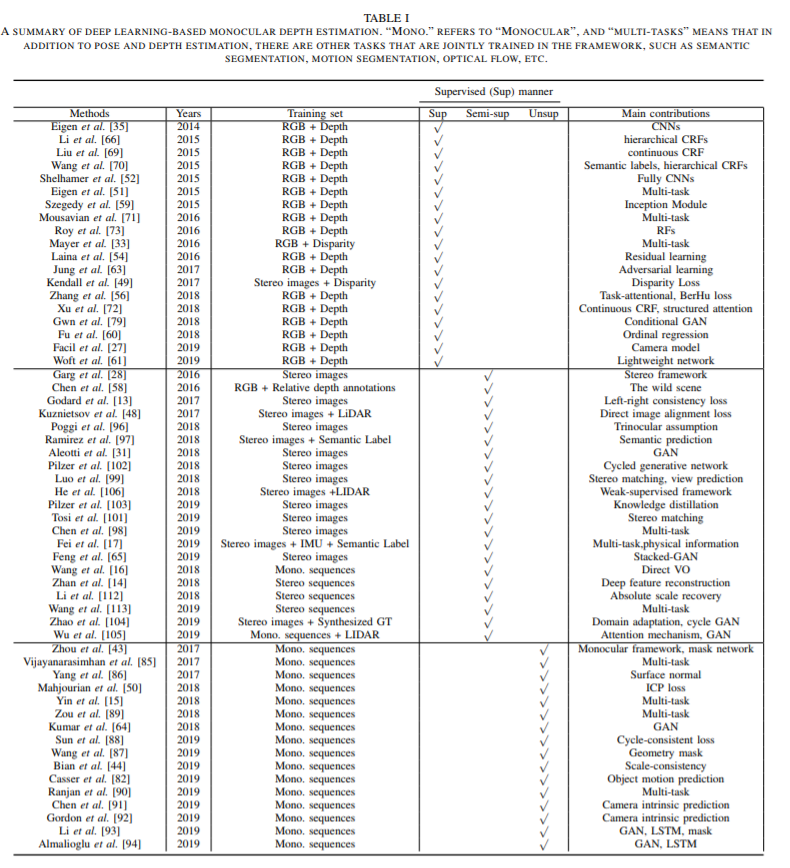
总结
推荐阅读

评论
 下载APP
下载APP极市导读
本文是一篇关于单目深度估计方法的综述文章,总结了基于深度学习的深度估计中被广泛使用的数据集、评价指标和重要的训练方法,并对该领域的未来提出展望。>>加入极市CV技术交流群,走在计算机视觉的最前沿
推荐阅读